The definition of high availability
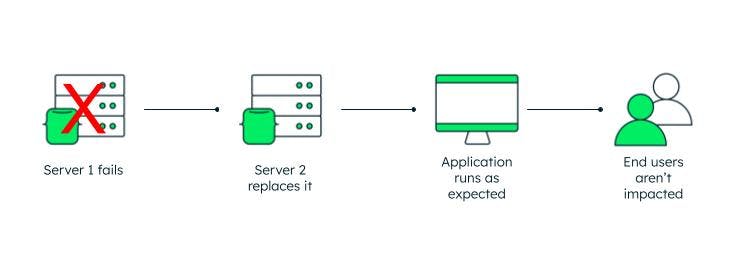
Let's start at the beginning: What is high availability? High availability means that we eliminate single points of failure so that should one of those components go down, the application or system can continue running as intended.
In other words, there will be minimal system downtime — or, in a perfect world, zero downtime — as a result of that failure.
In fact, this concept is often expressed using a standard known as "five nines," meaning that 99.999% of the time, systems work as expected. This is the (ambitious) desired availability standard that most of us are aiming for.
However, it’s worth noting some companies may have different availability targets, such as four nines (99.99%), three nines (99.9%), and two nines (99%). These tiers represent varying levels of availability commitment.
What you need to make it a reality
Two important aspects of high availability are (1) a data failover system and (2) data backup. To achieve high availability, the system has to have a way to maintain its functionality — by, for example, storing data — when things don't go according to plan.
In the example we provided earlier, the single point of failure is the transformer that went down. The city (hopefully) prepared for this with another transformer that can seamlessly pick up the slack.
Other examples of single points of failure that you might be able to relate to include routine server maintenance, network failure, hardware failure, software failure, and even power outages caused by natural disasters.
All of these can lead to service disruption and hamper a system's performance, sometimes significantly.
What about high-availability clusters?
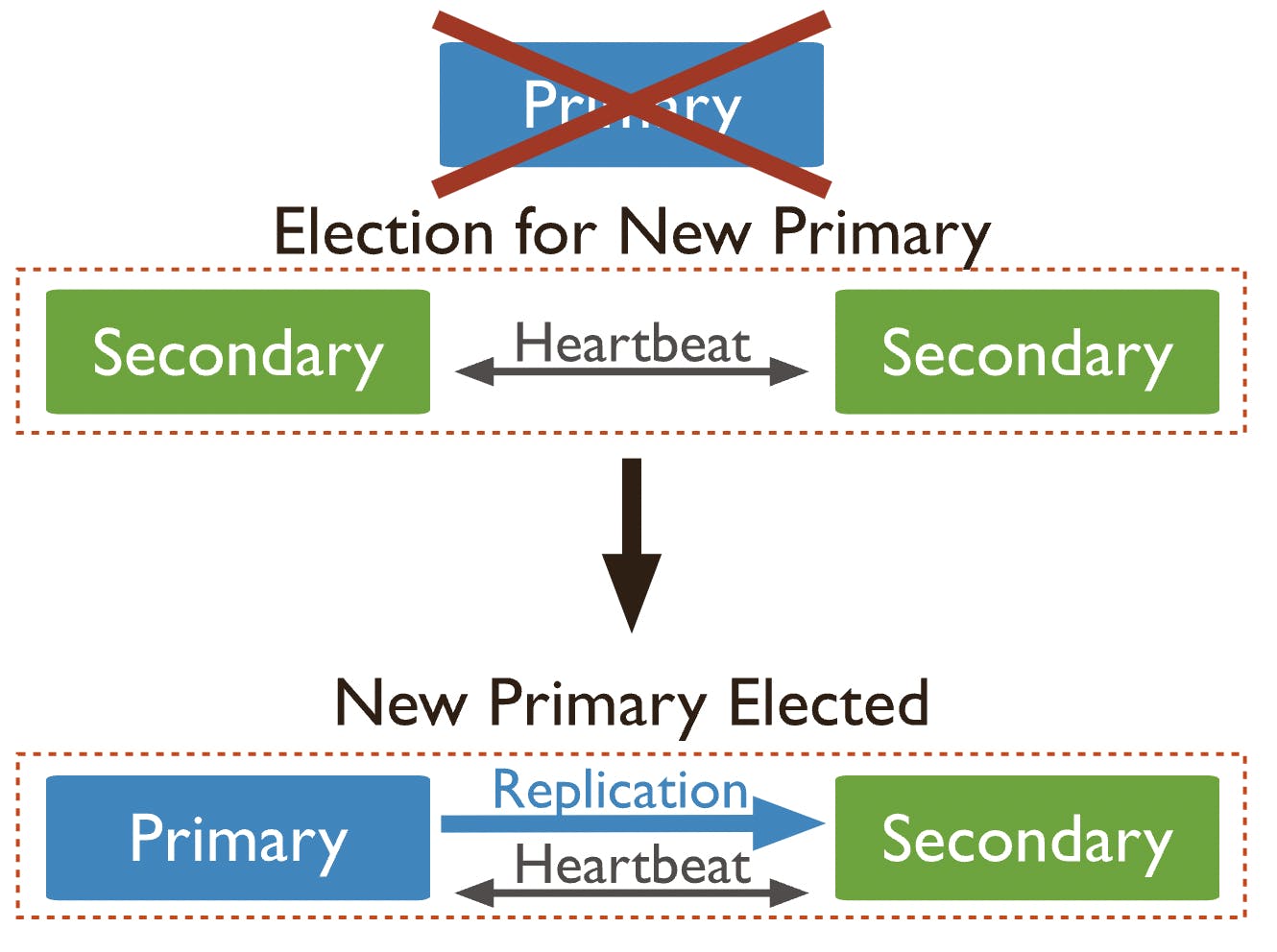
We can also speak more specifically about high-availability clusters, which are groups of servers that work together as one system. While these servers share storage, they're on different networks.
High-availability clusters have failover capabilities, which means that if one of the servers goes down, there's a backup component that can take its place.
Fault tolerance
When people talk about high availability, you might also hear "fault tolerance" used interchangeably. Essentially, they refer to the same concept.
Fault tolerance means that if one or more components within a system fail, there's a backup component ready to automatically take over, ensuring the system can maintain continuous availability, keeping users' access steady without interruption.
The backup components in a fault-tolerant system can include alternatives such as hardware, software, or power sources.