Data lakes offer a solution to the challenges posed by data swamps and data silos by employing a flexible architecture that allows for storing data in various formats and utilizing it for different purposes. Data lake architecture helps business users consume transformed data as well as allows data scientists to explore and experiment with raw data. While the specific setup of data lake architecture depends on the use case, it generally includes steps such as data ingestion, storage, processing, and distribution.
What is data lake architecture?
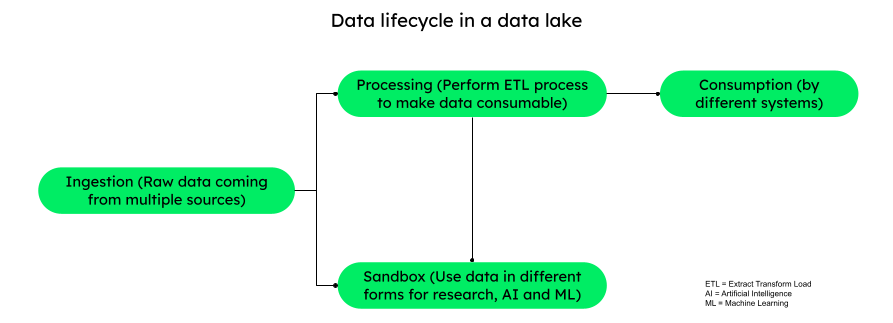
Data lake architecture is a framework or approach to designing a central repository to store and manage data in its original format, without any predefined schema. Data lake architecture accommodates all types of big data — structured, semi-structured, and unstructured. The basic structure of data lake architecture consists of various zones:
- Raw data landing zone: Data sourced from multiple sources comes here.
- Data ingestion zone: Data stored in its original format.
- Staging and processing zone: Data transformed and enriched for use.
- Exploration zone: Data used by scientists for research.
- Data governance zone: Data quality and auditing, metadata management.
Key data lake concepts
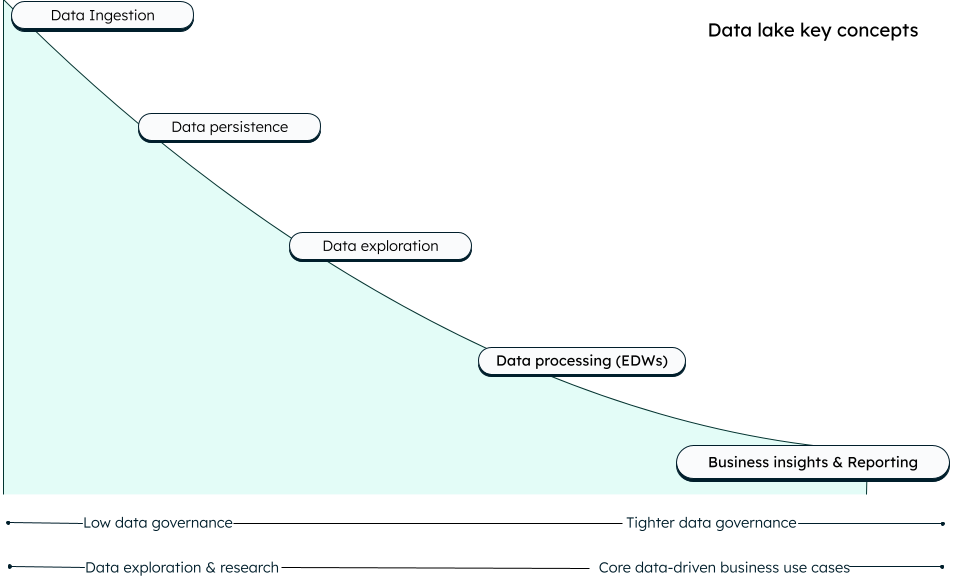
A data lake's main advantage is its ability to store data of any type, volume, or format in its original state. This allows for easy consolidation and analysis of diverse datasets for business purposes or analytics, providing valuable insights and enabling informed decision-making.
To fully leverage the advantages of a data lake, it's essential to adopt a strategic design approach that incorporates the following key concepts:
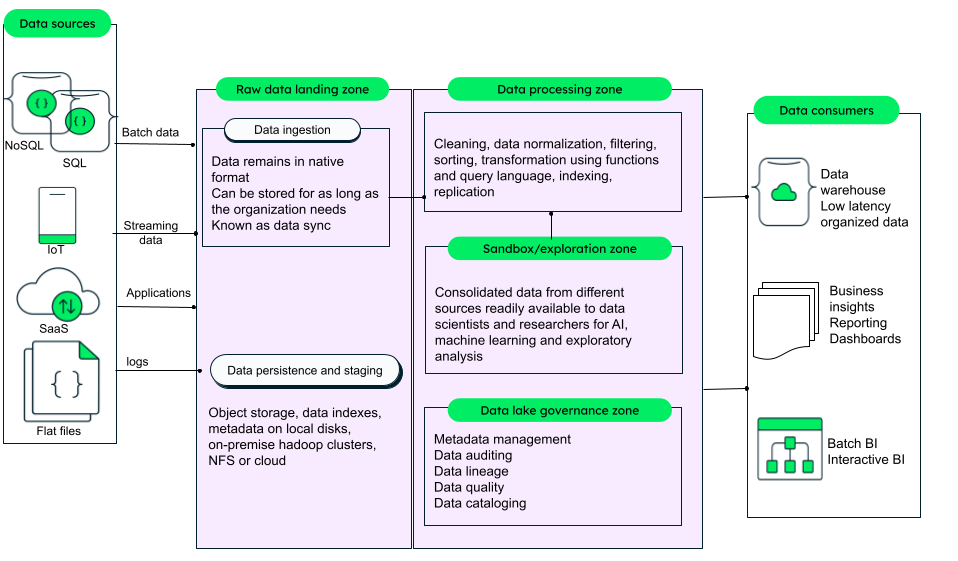
Data ingestion
Data ingestion, also known as the landing zone, is where all the data from various sources — NoSQL/SQL databases, streaming data from IoT devices, logs, applications, and services — is collected. Here data is in its raw (unprocessed) format, as received from the sources. This data requires the least governance and can be used for pilot projects or defining business requirements.
Data persistence
The batch data received from databases, data warehouses, or other data stores is stored in object storage. While persisting the data, we need to store the information about data — i.e., metadata — and also provide indexing mechanisms for data and metadata for faster data search.
Data processing
Streaming data received from IoT messages and applications, web applications, services running on cloud, and application logs go through ETL (Extract, Transform, Load) processing to make it standardized. Standardization is done using functions and queries and includes extracting features, cleaning, sorting, aggregation, normalization, indexing, and data replication. This refined, enriched data, also known as true data, gets stored in EDWs (Enterprise Data Warehouses), can be used for specific use cases and lines of business, and needs strict data governance.
Data exploration and analysis
Data scientists and business analysts can use the transformed data, raw data, or a combination of both, to create machine learning models, for AI, and for research and exploratory analysis. Organizations can democratize data, thus enabling even non-specialists to access and analyze data independently and use it for business intelligence.
Data governance
Data governance involves enforcing policies, like security, access control, tracking data lineage, maintaining data quality, data auditing, metadata management, and data cataloging. While raw data requires the least amount of governance, the transformed data, used for specific purposes, become a part of core data lake architecture, needing tighter governance.
Data lineage
One of the major benefits of utilizing a data lake is the ability to maintain data lineage. Data lineage involves tracking data from its original state to the transformed state, where it is used. Through data lineage, organizations can gain a comprehensive understanding of the data's journey, including its origin, how it was modified in the data pipeline, and its final destination. This enables organizations to ensure the quality and accuracy of data throughout its lifecycle, providing greater data reliability and usefulness.
Data cataloging
Data cataloging involves creating an inventory of data and data mapping using metadata and labeling so that data consumers can quickly search for the required data in a consolidated form. Results of data searched from a data catalog contain unstructured and structured data, reports, query results, visualizations, and dashboards. Data cataloging can also enable data lineage.
How to build a robust data lake architecture
Data lake architecture has evolved over many years to suit growing business requirements. Early data lake architectures included building on-premises on HDFS (Hadoop Distributed File System) clusters. However, maintaining the HDFS server, storage, and other operational costs quickly became costlier and difficult to manage. This led to the popularity of cloud data lakes.
Cloud storage and computing are scalable, highly available, and come at a significantly lower cost. Some popular cloud data lake providers are Azure Blob, Amazon S3, and Google Cloud.
The two major data lake architecture components — storage and compute — can be on-premise or on cloud, hence giving multiple possible combinations during the data lake architecture design phase.
Traditional on-premise data lake architecture deployments had only limited capabilities and needed manual intervention for capacity planning, performance optimization, and resource allocation. As needs for data grew and cloud data lakes gained more popularity, data lake architectures accommodated provision for efficient analytics along with automating many maintenance tasks like those above.
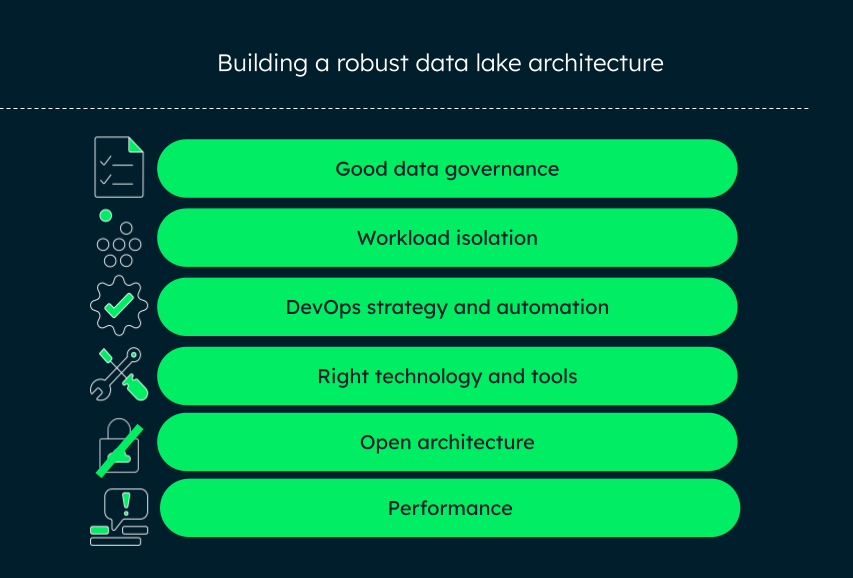
To design a robust modern data lake architecture, ensure the following:
Focus on data governance
Without proper data governance, a data lake might soon turn into a data swamp, losing its purpose. A good design should include governance measures like auditing, data cataloging, security, data integrity, compliance, and consistency. Further, it is important to preserve data lineage, as the data moves through the lake, and requires tracking the data at transactional as well as filesystem level. Data lakes such as Azure Databricks provide good data governance.
Keep workloads isolated
Data lake has two main components — storage and compute. Storage workloads like databases are tuned to maximize performance as most of the application searches depend on database retrieval. Compute workloads like analytical workloads, batch workloads, and transactional workloads need a good amount of processor and storage resources. Similarly, a real-time workload prefers low latency and high availability for sensitive applications like banking, military, and medical systems. Each of these workloads should be isolated so that even if one cracks up, the others remain unaffected. MongoDB Data Lake supports isolated workloads.
DevOps and automation
A data lake architecture consists of different zones or buckets for raw, conformed (or transformed), and purpose-built data that is ready to use for business use cases. Integrating a DevOps strategy into a data lake environment keeps the data lake reliable and clean. Organizations can automate the ETL tasks and set up continuous deployment pipelines easily, enabling developers to deliver applications on the data lake. However, setting up a DevOps strategy on a data lake environment needs a lot of planning, resources, and test cycles.
Technology and tool selection
A lot of data lake architecture implementation depends on the choice of tools and technologies for storage and computation. The choice largely depends on your business use case. If your workload demands a lot of real-time and streaming data, aggregations, and business intelligence, you should go for structures like a NoSQL database like MongoDB, or columnar data structures. Some popular technologies used for data lake implementation are Amazon S3, Azure Data Lake, Hadoop Distributed File System (on-premise), Spark clusters, and Google Cloud Storage.
Open architecture
Data lake design should be such that the organization does not depend on or lock in with a single vendor. For example, the incoming data need not conform to a specific schema. It should be parsed only when it is read.
Also, stick with the use of object storage to ensure high availability and low cost. Another important consideration is to use a centralized repository for data governance activities, like storing metadata, to avoid high operational infrastructure costs.
Performance
While handling different types of workloads, like the analytics workload, you need a high-performance engine at an optimal cost. To achieve good performance during querying, apply the storage best practices:
- Create metadata for every file.
- Store data in formats like Parquet or Avro for easier understanding of data and metadata.
- Practice a good partitioning strategy for quicker data retrieval.
Advantages of data lake architecture
Apart from the fact that you get a consolidated data view from all sources in the original format, there are other significant advantages of data lake architecture:
- By following an agile approach to a data lake, we can configure data lakes for any data structure, model, or application. We can automate end-to-end pipelines using functions as a service, or queries.
- Unlike traditional data storage methods, data lakes allow us to store data without the need for extensive preparation, such as creating indexes or metadata and transforming data. Instead, we can store data in its raw form until needed for a specific purpose, thus saving cost.
- Raw data can prove to be quite valuable to data scientists and researchers to gather business insights. Further, they can create self-service options for reporting and dashboards.
- Data lakes are flexible and scalable as the schema is defined only when the data is used (schema-on-read).
- Data lakes can cater to different types of audiences. For example, a business analyst can standardize, clean, and enrich data to use it for specific use cases; a non-technical person can use the data for generating reports for the organization; a researcher can use it for exploratory analysis; and a data scientist can use it for machine learning and AI.
- Data lakes bring data from different sources under one roof.
- Organizations have multiple options for storage and computing in a data lake — on-premise and cloud. They can choose any combination independently depending on their business model.
Challenges of data lakes
The main challenge with a data lake is storing huge amounts of raw data without clear laxity, which can lead to a "data swamp." To make data usable, you need to build a data lake architecture with proper mechanisms for data cataloging, security, governance, access controls, and semantic consistency.
Further, as more data is ingested, storage and processing costs may go up. Additionally, on-premises data lakes face challenges like data center and hardware setup, space, scalability, and cost as data volume grows.
Data lake architecture best practices
A data lake should be reliable and accurate at all times, for which organizations should ensure the following:
- Scalability: A data lake should be able to accept high volumes of data even as data grows. Data lakes such as MongoDB Atlas and Amazon S3 offer scalability.
- Flexible or no predefined schema: The purpose of a data lake is to store all types of data — structured or unstructured. Having a specific schema will lose the purpose of creating a data lake and might turn into a swamp.
- Data governance: Governance aspects like security, cataloging, and data quality should be given preferences while designing data lakes. It is important to have reliable data at all times and understand who can access what part of the data. Further, cataloging helps in faster data search and retrieval.
- Data exploration: Having tools and technologies to explore data for self-service BI, like visualization, machine learning, and AI enables data scientists to focus on advanced research with a consolidated and detailed view of data.
- Data recovery and disaster management: In case of a failure or outage, a data lake should be able to back up, replicate, and restore data without loss of data. Check out how MongoDB Atlas covers disaster management and data recovery.
Build your data lakes in the cloud with MongoDB Atlas
Building a data lake on-premise can seem like a good option, but you’d face scalability issues and higher maintenance costs as your organization's data grows. Additionally, managing the infrastructure and workloads yourself can be resource-intensive and time-consuming, particularly when dealing with complex pipelines.
MongoDB Atlas provides a serverless, scalable data lake optimized for analytical queries while maintaining the economics of cloud object storage. And with Data Federation, you can query data from those data lakes with the same query language you are familiar with. MongDB’s data lake offers automated data extraction from Atlas clusters, optimal format for analytics workloads, and is fully integrated into MongoDB Atlas.