AI agents are pushing the frontier of automation, driving efficiency and productivity across many domains like software engineering and knowledge work. But building real-world agents at scale remains a challenge. The bottleneck is not the models themselves, which are incredibly capable, but context engineering. Memory, a form of context, is the critical piece that enables reliable and personalized agentic experiences.
Just as traditional applications depend on operational data to function effectively, AI agents rely on memory to operate intelligently. In both cases, databases play a central role, providing the infrastructure needed to store, retrieve, and manage data. However, agent memory introduces specific challenges, such as highly evolving data structures, large-scale contextual retrieval, and inherently unpredictable agentic workloads. Meeting these needs requires a database architecture for the era of AI agents.
What is the role of memory in agents?
AI agents, powered by large language models, perform tasks through planning, reasoning, and tool use. What sets them apart is their ability to autonomously decide when and how to apply these capabilities, whether independently, within structured workflows, as part of a multi-agent system, or in collaboration with humans.
Robust context management is critical to making agents reliable and effective. This context includes the current conversation, intermediate states, outputs, and long-term knowledge, which together form an agent’s memory.
Like humans, agents rely on different types of memory to support distinct capabilities. Each type plays a specific role and requires specific implementation strategies.
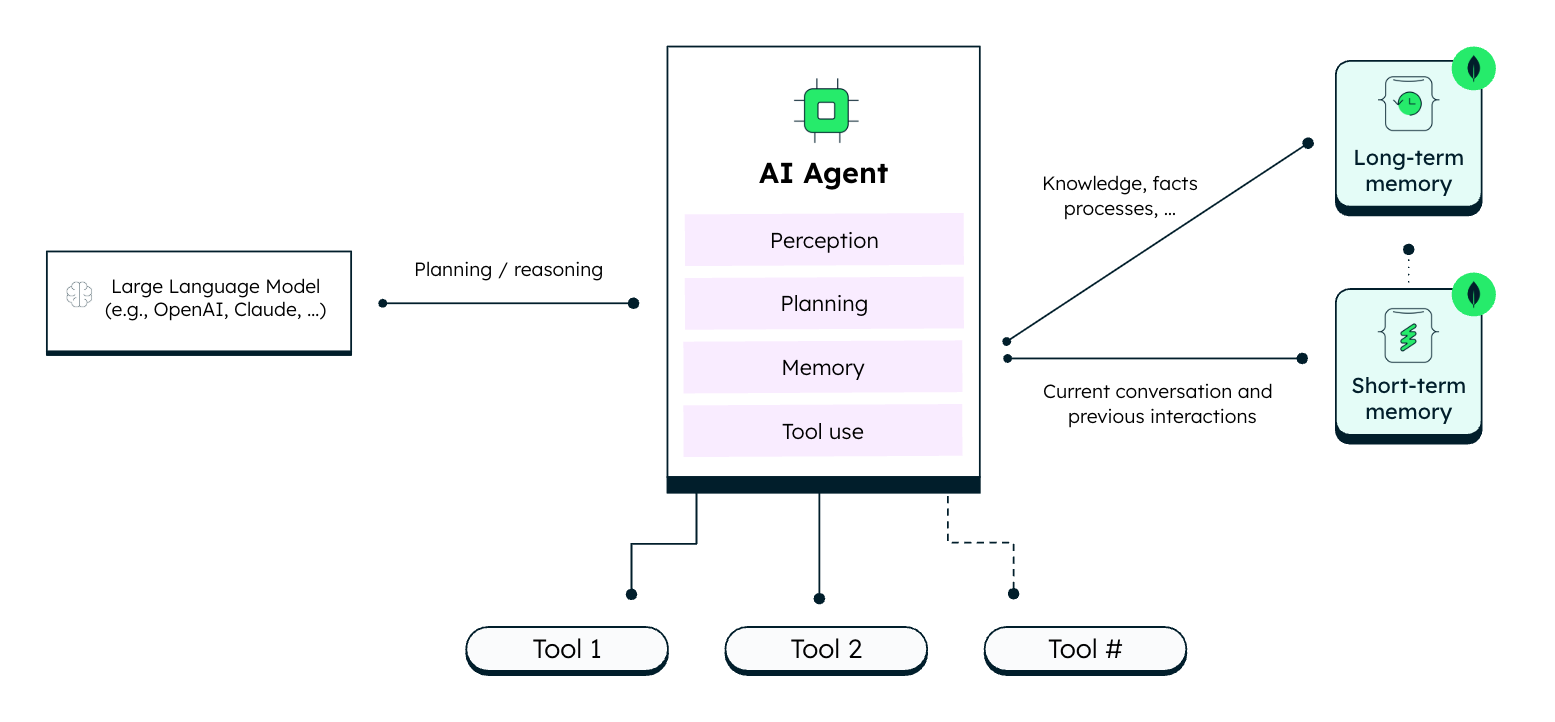
What is short-term agentic memory?
Short-term memory provides the immediate context an AI agent needs to complete its main tasks. It typically includes the active conversation and the most recent interactions. This is often implemented through sessions, where the full conversation, along with tool outputs and intermediate calculations, is kept synchronized and continuously added to the agent’s context. By storing this session state, the conversation can later be resumed from the same point.
Other short-term memory implementations include semantic caches, which store recent prompts and LLM responses for retrieval when similar queries are prompted, and shared memory, which is used in multi-agent systems to provide a common space for coordination and information sharing.
What is long-term agentic memory?
Long-term memory serves as an agent’s knowledge base, allowing it to remember facts and learnings for future use. It includes several functional types, each requiring specific storage and retrieval strategies:
- Episodic memory: captures specific events and interactions, such as conversation history or summaries of key occurrences with metadata (e.g., timestamps, participants). For instance, a customer support agent can use this to recall a user’s past issues and offer personalized responses.
- Procedural memory: records instructions or rules for recurring tasks. This can be achieved through Agent Skills, which offer easy sharing and high composability, but are still a manual process today. For MongoDB, explore the official skills that provide expert best practices for agents. Alternatively, procedural memory can be implemented more dynamically, enabling it to evolve.
- Semantic memory: stores general knowledge, facts, and concepts. This is often implemented through retrieval-augmented generation (RAG), where data is stored as vector embeddings and retrieved based on semantic similarity.
- Associative memory: stores key entities and relationships between different pieces of information, enabling an agent to identify patterns and make inferences by navigating these connections. It's often implemented using graph structures that support efficient exploration of relationships. Context graphs or GraphRAG are commonly used patterns for implementing this type of memory. It can overlap with semantic memory or replace it in some cases.
Implementing long-term memory is complex, especially at scale. The challenges include efficiently storing and retrieving relevant information at the right time, and effectively updating or forgetting outdated memories. The variety of memory types, retrieval strategies, and data formats adds to the complexity.
Moreover, existing challenges in LLM-based applications remain, such as limited context window sizes and high token costs for large contexts. This complexity makes it clear that building reliable and scalable long-term memory fundamentally relies on a robust data infrastructure.
Agent Memory Demands a Database Built for AI
As frontier large language models become smarter and cheaper, most of the value will reside at the agent layer. In a world where building is increasingly easy, the only real differentiation may come from personalized and unique user experiences that improve with continued use. This makes agent memory a critical component of agent development, and the choice of the database powering it a strategic one.
Agent memory is not just about storing data. It requires intelligent, context-aware retrieval at scale. More importantly, it is the layer that gives your agent its distinct, compounding value over time. Because of this, owning your memory infrastructure, rather than delegating it to a third party, is a strategic imperative. That ownership is only meaningful if the underlying database is flexible, scalable, and portable. The main characteristics to look for include:
- Support for diverse data types. AI agents work with a wide range of data types. Frontier LLMs process multimodal data and a variety of inputs such as raw text, markdown, tabular data, and more, so memory must be flexible enough to match. This is why efficient memory systems must support structured, semi-structured, unstructured, vector, and graph data to address the diversity of memory needs.
- Advanced retrieval capabilities. Retrieving the right information at the right time is essential. This requires multiple search strategies, including full-text, vector, hybrid, and graph-based queries. These capabilities are key to enabling the full spectrum of long-term memory types, from episodic to associative, through a unified retrieval layer.
- Reliability and scalability. AI agents introduce unique operational demands. Fine-grained role-based access control is needed to define what agents can access and how. Performance must be maintained under unpredictable agentic workloads, making workload isolation and autoscaling key capabilities.
- Fine-grained security. Memory can range from general knowledge to highly personalized user information. Since the nature of data is not always known in advance, and LLMs decide what to store, sensitive information may be saved. Strong security guardrails and fine-grained role-based access control (RBAC) should be enforceable.
- Agnosticity and no lock-in: Memory is a core component that makes the agentic experience valuable and distinct. As such, it should be owned and controlled directly, rather than relying on locked-in systems. Ensure that memory remains portable and model or cloud-agnostic.
An ideal database for agent memory should meet these requirements without forcing developers to stitch together multiple specialized systems. For a time, the dominant pattern was a “Frankenstein architecture.” Teams combined one database for operational data, another for vector search, another for graph storage, plus one or more AI model providers.
At scale, this led to data synchronization issues, operational complexity, and a fragmented developer experience. Consolidation became necessary and is now underway. Platforms such as MongoDB Atlas offer operational data storage, advanced vector search, and state-of-the-art retrieval models within a single platform, making it easier to build and run agents at scale.
Capable Agents Start With Memory
Agent memory delivers the right context at the right time, enabling AI agents to reach their full potential and drive real value for users and organizations. Beyond enhancing agent capabilities, effective memory engineering enables personalized experiences and creates long-term advantages through accumulated knowledge. To realize this, agentic systems must be reliable, scalable, and portable. Choosing the right foundational database is critical to long-term agent success.