Visão geral
Neste guia, você pode aprender como armazenar e recuperar arquivos grandes no MongoDB usando GridFS. O sistema de armazenamento GridFS divide os arquivos em chunks ao armazená-los e reagrupa esses arquivos ao recuperá-los. A implementação do driver do GridFS é uma abstração que gerencia as operações e a organização do armazenamento de arquivos.
Use o GridFS se o tamanho de qualquer um dos seus arquivos exceder o limite de tamanho de documento BSON de 16 MB. Para obter informações mais detalhadas sobre se o GridFS é adequado para seu caso de uso, consulte GridFS no manual do MongoDB Server .
Como funciona o GridFS
O GridFS organiza arquivos em um bucket, um grupo de coleções do MongoDB que contêm os blocos de arquivos e as informações que os descrevem. O bucket contém as seguintes coleções:
chunks: Armazena os blocos de arquivos bináriosfiles: armazena os metadados do arquivo
O driver cria o bucket GridFS , se ele ainda não existir, quando você grava dados pela primeira vez. O bucket contém as collections chunks e files prefixadas com o nome de bucket padrão fs, a menos que você especifique um nome diferente. Para garantir a recuperação eficiente dos arquivos e de seus respectivos metadados, o driver cria um índice em cada collection. O driver garante que esses índices existam antes de realizar operações de leitura e gravação no bucket GridFS .
Para obter mais informações sobre os índices do GridFS , consulte Índices do GridFS no manual do MongoDB Server .
Ao usar o GridFS para armazenar arquivos, o driver divide os arquivos em partes menores, cada um representado por um documento separado na coleção chunks. Ele também cria um documento na coleção files que contém um ID de arquivo, nome de arquivo e outros metadados de arquivo.
O diagrama a seguir mostra como o GridFS divide os arquivos quando eles são carregados em um bucket:

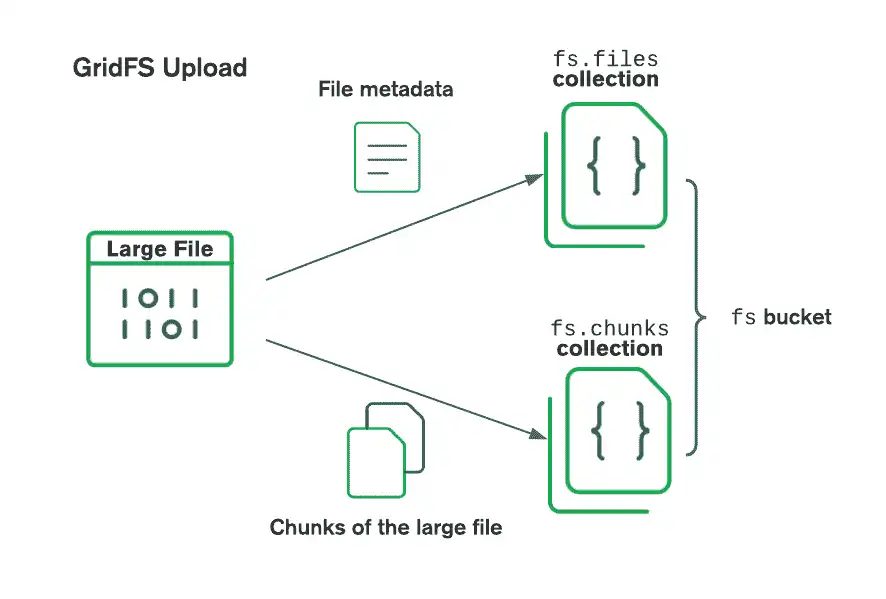
Ao recuperar arquivos, o GridFS obtém os metadados da coleção files no contêiner especificado e utiliza as informações para reconstruir o arquivo a partir de documentos na coleção chunks.
Crie um intervalo GridFS
Para começar a usar o GridFS para armazenar ou recuperar arquivos, crie uma nova instância da classe GridFSBucket , passando um objeto IMongoDatabase que representa seu banco de dados. Este método acessa um bucket existente ou cria um novo bucket se não existir.
O exemplo seguinte cria uma nova instância da classe GridFSBucket para o banco de dados db :
var client = new MongoClient("<connection string>"); var database = client.GetDatabase("db"); // Creates a GridFS bucket or references an existing one var bucket = new GridFSBucket(database);
Personalizar o bucket
Você pode personalizar a configuração do bucket GridFS passando uma instância da classe GridFSBucketOptions para o construtor GridFSBucket(). A tabela seguinte descreve as propriedades na classe GridFSBucketOptions :
Campo | Descrição |
|---|---|
| O nome do bucket a ser usado como prefixo para os arquivos e collections de chunks. O valor padrão é Tipo de dados: |
| O tamanho do chunk em que o GridFS divide os arquivos. O valor padrão é 255 KB. Tipo de dados: |
| A preocupação de leitura a ser usada para operações de bucket. O valor padrão é a preocupação de leitura do banco de dados. Tipo de Dados: ReadConcern |
| A preferência de leitura a ser usada para operações de bucket. O valor padrão é a preferência de leitura do banco de dados. Tipo de dados: ReadPreference |
| O preocupação de gravação a ser usado para operações de bucket. O valor padrão é a preocupação de gravação do banco de dados. Tipo de Dados: WriteConcern |
O exemplo seguinte cria um bucket denominado "myCustomBucket" passando uma instância da classe GridFSBucketOptions para o construtor GridFSBucket():
var options = new GridFSBucketOptions { BucketName = "myCustomBucket" }; var customBucket = new GridFSBucket(database, options);
Fazer upload de arquivos
Você pode fazer upload de arquivos para um bucket GridFS usando os seguintes métodos:
OpenUploadStream()ouOpenUploadStreamAsync(): abre um novo fluxo de upload para o qual você pode gravar o conteúdo do arquivoUploadFromStream()ouUploadFromStreamAsync(): faz o upload do conteúdo de um stream existente para um arquivo GridFS
As seções a seguir descrevem como usar esses métodos.
Escrever em um fluxo de upload
Use o método OpenUploadStream() ou OpenUploadStreamAsync() para criar um fluxo de upload para um determinado nome de arquivo. Esses métodos aceitam os seguintes parâmetros:
Parâmetro | Descrição |
|---|---|
| O nome do arquivo a ser carregado. Tipo de dados: |
| Opcional. Uma instância da classe Tipo de dados: GridFSUploadOptions |
| Opcional. Um token que você pode usar para cancelar a operação. Tipo de dados: CancellationToken |
Este exemplo de código demonstra como abrir um fluxo de upload executando as seguintes etapas:
Chama o método
OpenUploadStream()para abrir um fluxo GridFS gravável para um arquivo chamado"my_file"Chama o método
Write()para escrever dados emmy_fileChama o método
Close()para fechar o fluxo que aponta paramy_file
Selecione a aba Synchronous ou Asynchronous para ver o código correspondente:
using (var uploader = bucket.OpenUploadStream("my_file")) { // ASCII for "HelloWorld" byte[] bytes = { 72, 101, 108, 108, 111, 87, 111, 114, 108, 100 }; uploader.Write(bytes, 0, bytes.Length); uploader.Close(); }
using (var uploader = await bucket.OpenUploadStreamAsync("my_file", options)) { // ASCII for "HelloWorld" byte[] bytes = { 72, 101, 108, 108, 111, 87, 111, 114, 108, 100 }; await uploader.WriteAsync(bytes, 0, bytes.Length); await uploader.CloseAsync(); }
Para personalizar a configuração do fluxo de upload, passe uma instância da classe GridFSUploadOptions para o método OpenUploadStream() ou OpenUploadStreamAsync() . A classe GridFSUploadOptions contém as seguintes propriedades:
Propriedade | Descrição |
|---|---|
| O número de chunks para upload em cada lote. O valor padrão é 16 MB dividido pelo valor da propriedade Tipo de dados: |
| O tamanho de cada chunk, exceto o último, que é menor. O valor padrão é 255 KB. Tipo de dados: |
| Metadados para armazenar com o arquivo, incluindo os seguintes elementos:
O valor padrão é Tipo de dados: BsonDocument |
O exemplo a seguir executa as mesmas etapas do exemplo anterior, mas também usa a opção ChunkSizeBytes para especificar o tamanho de cada chunk. Selecione a aba Synchronous ou Asynchronous para ver o código correspondente.
Carregar um stream existente
Utilize o método UploadFromStream() ou UploadFromStreamAsync() para carregar o conteúdo de um stream para um novo arquivo GridFS . Esses métodos aceitam os seguintes parâmetros:
Parâmetro | Descrição |
|---|---|
| O nome do arquivo a ser carregado. Tipo de dados: |
| O stream a partir do qual ler o conteúdo do arquivo. Tipo de dados: Stream |
| Opcional. Uma instância da classe Tipo de dados: GridFSUploadOptions |
| Opcional. Um token que você pode usar para cancelar a operação. Tipo de dados: CancellationToken |
Este exemplo de código demonstra como abrir um fluxo de upload executando as seguintes etapas:
Abre um arquivo localizado em
/path/to/input_filecomo um stream no modo de leitura bináriaChama o método
UploadFromStream()para escrever o conteúdo do stream em um arquivo GridFS chamado"new_file"
Selecione a aba Synchronous ou Asynchronous para ver o código correspondente.
using (var fileStream = new FileStream("/path/to/input_file", FileMode.Open, FileAccess.Read)) { bucket.UploadFromStream("new_file", fileStream); }
using (var fileStream = new FileStream("/path/to/input_file", FileMode.Open, FileAccess.Read)) { await bucket.UploadFromStreamAsync("new_file", fileStream); }
Baixar arquivos
Você pode baixar arquivos de um bucket GridFS usando os seguintes métodos:
OpenDownloadStream()ouOpenDownloadStreamAsync(): abre um novo fluxo de downloads do qual você pode ler o conteúdo do arquivoDownloadToStream()ouDownloadToStreamAsync(): grava o conteúdo de um arquivo GridFS em um fluxo existente
As seções a seguir descrevem esses métodos em mais detalhes.
Ler de um fluxo de download
Use o método OpenDownloadStream() ou OpenDownloadStreamAsync() para criar um stream de download. Esses métodos aceitam os seguintes parâmetros:
Parâmetro | Descrição |
|---|---|
| O valor Tipo de dados: BsonValue |
| Opcional. Uma instância da classe Tipo de dados: GridFSDownloadOptions |
| Opcional. Um token que você pode usar para cancelar a operação. Tipo de dados: CancellationToken |
O exemplo de código a seguir demonstra como abrir um fluxo de download executando as seguintes etapas:
Recupera o valor
_iddo arquivo GridFS denominado"new_file"Chama o método
OpenDownloadStream()e passa o valor_idpara abrir o arquivo como um fluxo GridFS legívelCria um vetor
bufferpara armazenar o conteúdo do arquivoChama o método
Read()para ler o conteúdo do arquivo do fluxodownloaderpara o vetor
Selecione a aba Synchronous ou Asynchronous para ver o código correspondente.
var filter = Builders<GridFSFileInfo>.Filter.Eq(x => x.Filename, "new_file"); var doc = bucket.Find(filter).FirstOrDefault(); if (doc != null) { using (var downloader = bucket.OpenDownloadStream(doc.Id)) { var buffer = new byte[downloader.Length]; downloader.Read(buffer, 0, buffer.Length); // Process the buffer as needed } }
var filter = Builders<GridFSFileInfo>.Filter.Eq(x => x.Filename, "new_file"); var cursor = await bucket.FindAsync(filter); var fileInfoList = await cursor.ToListAsync(); var doc = fileInfoList.FirstOrDefault(); if (doc != null) { using (var downloader = await bucket.OpenDownloadStreamAsync(doc.Id)) { var buffer = new byte[downloader.Length]; await downloader.ReadAsync(buffer, 0, buffer.Length); // Process the buffer as needed } }
Para personalizar a configuração do fluxo de download, passe uma instância da classe GridFSDownloadOptions para o método OpenDownloadStream(). A classe GridFSDownloadOptions contém a seguinte propriedade:
Propriedade | Descrição |
|---|---|
| Indica se o stream oferece suporte à busca, a capacidade de fazer query e alterar a posição atual em um stream. O valor padrão é Tipo de dados: |
O exemplo a seguir executa as mesmas etapas do exemplo anterior, mas também define a opção Seekable como true para especificar que o fluxo é pesquisável.
Selecione a aba Synchronous ou Asynchronous para ver o código correspondente.
Baixar em um stream existente
Use o método DownloadToStream() ou DownloadToStreamAsync() para baixar o conteúdo de um arquivo GridFS para um stream existente. Esses métodos aceitam os seguintes parâmetros:
Parâmetro | Descrição |
|---|---|
| O valor Tipo de dados: BsonValue |
| O fluxo para o qual o driver .NET/C# baixa o arquivo GridFS . O valor desta propriedade deve ser um objeto que implemente a classe Tipo de dados: Stream |
| Opcional. Uma instância da classe Tipo de dados: GridFSDownloadOptions |
| Opcional. Um token que você pode usar para cancelar a operação. Tipo de dados: CancellationToken |
O exemplo de código abaixo demonstra como fazer o download em um stream existente executando as seguintes ações:
Abre um arquivo localizado em
/path/to/output_filecomo um stream no modo de escrita bináriaRecupera o valor
_iddo arquivo GridFS denominado"new_file"Chama o método
DownloadToStream()e passa o valor_idpara baixar o conteúdo de"new_file"para um stream
Selecione a aba Synchronous ou Asynchronous para ver o código correspondente.
var filter = Builders<GridFSFileInfo>.Filter.Eq(x => x.Filename, "new_file"); var doc = bucket.Find(filter).FirstOrDefault(); if (doc != null) { using (var outputFile = new FileStream("/path/to/output_file", FileMode.Create, FileAccess.Write)) { bucket.DownloadToStream(doc.Id, outputFile); } }
var filter = Builders<GridFSFileInfo>.Filter.Eq(x => x.Filename, "new_file"); var cursor = await bucket.FindAsync(filter); var fileInfoList = await cursor.ToListAsync(); var doc = fileInfoList.FirstOrDefault(); if (doc != null) { using (var outputFile = new FileStream("/path/to/output_file", FileMode.Create, FileAccess.Write)) { await bucket.DownloadToStreamAsync(doc.Id, outputFile); } }
Encontrar arquivos
Para localizar arquivos em um contêiner GridFS , chame o método Find() ou FindAsync() em sua instância do GridFSBucket. Esses métodos aceitam os seguintes parâmetros:
Parâmetro | Descrição |
|---|---|
| Um filtro de consulta que especifica as entradas a serem correspondidas na coleção Tipo de dados: |
| O stream a partir do qual ler o conteúdo do arquivo. Tipo de dados: Stream |
| Opcional. Uma instância da classe Tipo de dados: GridFSFindOptions |
| Opcional. Um token que você pode usar para cancelar a operação. Tipo de dados: CancellationToken |
O seguinte exemplo de código mostra como recuperar e imprimir metadados de arquivo de arquivos em um bucket GridFS . O método Find() retorna uma instância IAsyncCursor<GridFSFileInfo> da qual você pode acessar os resultados. Ela usa um foreach loop para iterar pelo cursor retornado e exibir o conteúdo dos arquivos carregados nos exemplos de Carregar arquivos.
Selecione a aba Synchronous ou Asynchronous para ver o código correspondente.
var filter = Builders<GridFSFileInfo>.Filter.Empty; var files = bucket.Find(filter); foreach (var file in files.ToEnumerable()) { Console.WriteLine(file.ToJson()); }
{ "_id" : { "$oid" : "..." }, "length" : 13, "chunkSize" : 261120, "uploadDate" : { "$date" : ... }, "filename" : "new_file" } { "_id" : { "$oid" : "..." }, "length" : 50, "chunkSize" : 1048576, "uploadDate" : { "$date" : ... }, "filename" : "my_file" }
var filter = Builders<GridFSFileInfo>.Filter.Empty; var files = await bucket.FindAsync(filter); await files.ForEachAsync(file => Console.Out.WriteLineAsync(file.ToJson()))
{ "_id" : { "$oid" : "..." }, "length" : 13, "chunkSize" : 261120, "uploadDate" : { "$date" : ... }, "filename" : "new_file" } { "_id" : { "$oid" : "..." }, "length" : 50, "chunkSize" : 1048576, "uploadDate" : { "$date" : ... }, "filename" : "my_file" }
Para personalizar a operação de localizar, passe uma instância da classe GridFSFindOptions para o método Find() ou FindAsync(). A classe GridFSFindOptions contém as seguintes propriedades:
Propriedade | Descrição |
|---|---|
| A ordem de classificação dos resultados. Se você não especificar uma ordem de classificação, o método retornará os resultados na ordem em que foram inseridos. Tipo de dados: |
Excluir arquivos
Para excluir arquivos de um contêiner GridFS , chame o método Delete() ou DeleteAsync() na sua instância do GridFSBucket. Esse método remove a coleção de metadados de um arquivo e seus blocos associados do seu bloco.
Os métodos Delete e DeleteAsync() aceitam os seguintes parâmetros:
Parâmetro | Descrição |
|---|---|
| O Tipo de dados: BsonValue |
| Opcional. Um token que você pode usar para cancelar a operação. Tipo de dados: CancellationToken |
O seguinte exemplo de código mostra como excluir um arquivo denominado "my_file" passando seu valor _id para delete_file():
Utiliza a classe
Builderspara criar um filtro que corresponda ao arquivo denominado"my_file"Utiliza o método
Find()para localizar o arquivo denominado"my_file"Passa o valor
_iddo arquivo para o métodoDelete()para excluir o arquivo
Selecione a aba Synchronous ou Asynchronous para ver o código correspondente.
var filter = Builders<GridFSFileInfo>.Filter.Eq(x => x.Filename, "new_file"); var doc = bucket.Find(filter).FirstOrDefault(); if (doc != null) { bucket.Delete(doc.Id); }
var filter = Builders<GridFSFileInfo>.Filter.Eq(x => x.Filename, "new_file"); var cursor = await bucket.FindAsync(filter); var fileInfoList = await cursor.ToListAsync(); var doc = fileInfoList.FirstOrDefault(); if (doc != null) { await bucket.DeleteAsync(doc.Id); }
Observação
Revisões de arquivos
Os métodos Delete() e DeleteAsync() suportam a exclusão de somente um arquivo de cada vez. Para excluir cada revisão de arquivo ou arquivos com tempos de carregamento diferentes que compartilham o mesmo nome de arquivo, colete os valores _id de cada revisão. Em seguida, passe cada valor _id em chamadas separadas para o método Delete() ou DeleteAsync().
Documentação da API
Para saber mais sobre as classes usadas nesta página, consulte a seguinte documentação da API:
Para saber mais sobre os métodos da classe GridFSBucket usados nesta página, consulte a seguinte documentação da API: