이 가이드 Voyage AI 모델을 사용하여 시맨틱 검색 수행하는 방법을 설명합니다. 이 페이지에는 순위 재지정을 사용한 검색 , 다국어, 다중 모드, 상황별 청크 및 대규모 코퍼스 검색을 포함한 기본 및 고급 시맨틱 검색 사용 사례에 대한 예제가 포함되어 있습니다.
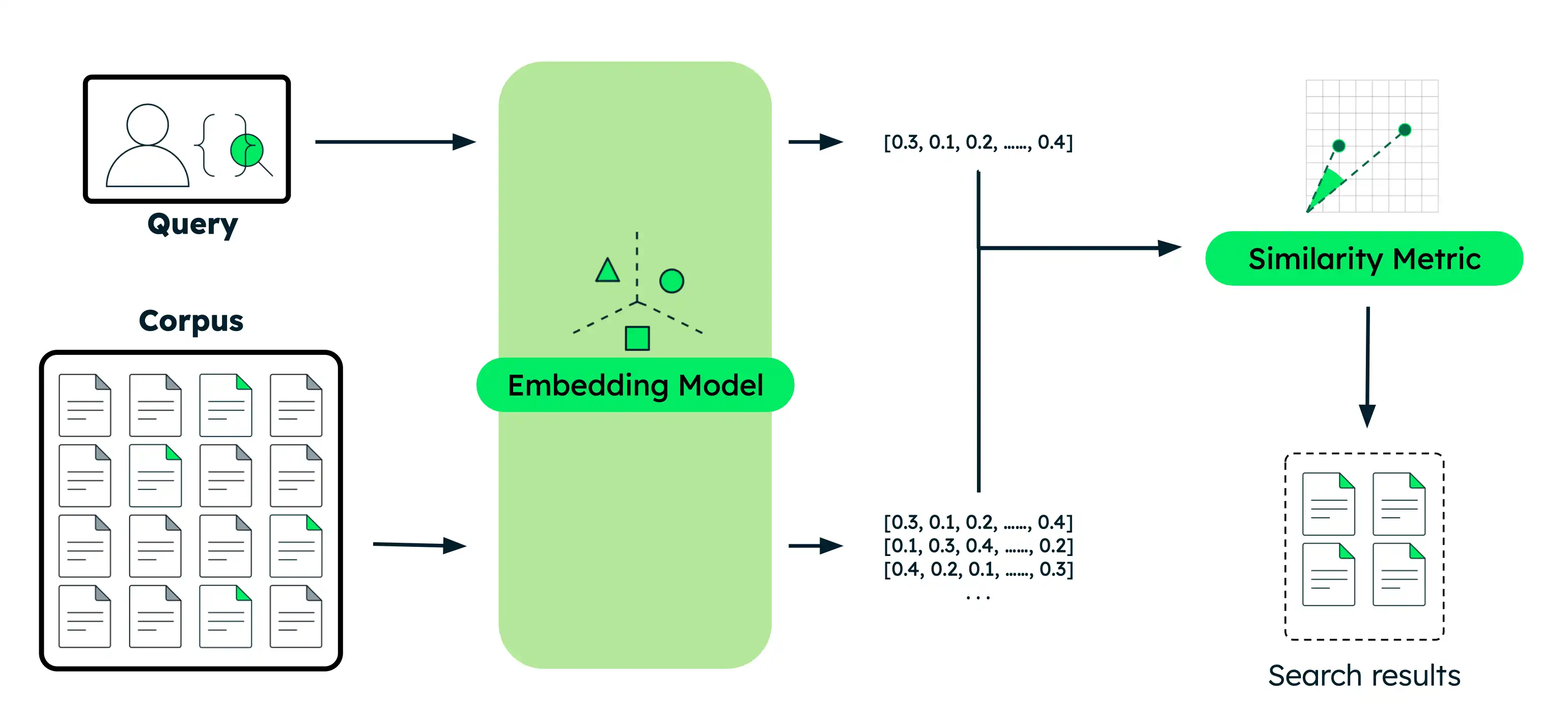
시맨틱 검색 수행
이 섹션에서는 다양한 Voyage AI 모델을 사용한 다양한 시맨틱 검색 사용 사례에 대한 코드 예제를 제공합니다. 각 예시 에 대해 동일한 기본 단계를 수행합니다.
문서 임베딩: 데이터를 의미를 포착하는 벡터 임베딩으로 변환합니다. 이 데이터는 텍스트, 이미지, 문서 청크 또는 대규모 텍스트 코퍼스가 될 수 있습니다.
쿼리 포함: 검색 쿼리 문서와 동일한 벡터 표현으로 변환합니다.
유사한 문서 찾기: 쿼리 벡터를 문서 벡터와 비교하여 의미상 가장 유사한 결과를 식별합니다.
이 튜토리얼의 실행 가능한 버전을 Python 노트북으로 사용합니다.
환경을 설정합니다.
시작하기 전에 프로젝트 디렉토리 생성하고, 라이브러리를 설치하고, 모델 API 키를 설정하다 .
터미널에서 다음 명령을 실행하여 이 튜토리얼을 위한 새 디렉토리 만들고 필요한 라이브러리를 설치합니다.
mkdir voyage-semantic-search cd voyage-semantic-search pip install --upgrade voyageai numpy datasets 아직 하지 않았다면 단계에 따라모델 API 키를 만들 후 터미널에서 다음 명령을 실행 환경 변수로 내보냅니다.
export VOYAGE_API_KEY="your-model-api-key"
시맨틱 검색 쿼리를 실행합니다.
각 섹션을 펼치면 각 유형의 시맨틱 검색 에 대한 코드 예제를 볼 수 있습니다.
프로젝트 에
semantic_search_basic.py이라는 파일 만들고 다음 코드를 붙여넣습니다.
import voyageai import numpy as np # Initialize Voyage AI client vo = voyageai.Client() # Sample documents documents = [ "The Mediterranean diet emphasizes fish, olive oil, and vegetables, believed to reduce chronic diseases.", "Photosynthesis in plants converts light energy into glucose and produces essential oxygen.", "20th-century innovations, from radios to smartphones, centered on electronic advancements.", "Rivers provide water, irrigation, and habitat for aquatic species, vital for ecosystems.", "Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET.", "Shakespeare's works, like 'Hamlet' and 'A Midsummer Night's Dream,' endure in literature." ] # Search query query = "When is Apple's conference call scheduled?" # Generate embeddings for documents doc_embeddings = vo.embed( texts=documents, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for query query_embedding = vo.embed( texts=[query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product similarities = np.dot(doc_embeddings, query_embedding) # Sort documents by similarity (highest to lowest) ranked_indices = np.argsort(-similarities) # Display results print(f"Query: '{query}'\n") for rank, idx in enumerate(ranked_indices, 1): print(f"{rank}. {documents[idx]}") print(f" Similarity: {similarities[idx]:.4f}\n")
터미널에서 다음 명령을 실행하세요.
python semantic_search_basic.py
Query: 'When is Apple's conference call scheduled?' 1. Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET. Similarity: 0.6691 2. 20th-century innovations, from radios to smartphones, centered on electronic advancements. Similarity: 0.2751 3. Shakespeare's works, like 'Hamlet' and 'A Midsummer Night's Dream,' endure in literature. Similarity: 0.2335 4. The Mediterranean diet emphasizes fish, olive oil, and vegetables, believed to reduce chronic diseases. Similarity: 0.1955 5. Photosynthesis in plants converts light energy into glucose and produces essential oxygen. Similarity: 0.1881 6. Rivers provide water, irrigation, and habitat for aquatic species, vital for ecosystems. Similarity: 0.1601
프로젝트 에
semantic_search_reranker.py라는 파일 만들고 다음 코드를 붙여넣습니다.
import voyageai import numpy as np # Initialize Voyage AI client vo = voyageai.Client() # Sample documents documents = [ "The Mediterranean diet emphasizes fish, olive oil, and vegetables, believed to reduce chronic diseases.", "Photosynthesis in plants converts light energy into glucose and produces essential oxygen.", "20th-century innovations, from radios to smartphones, centered on electronic advancements.", "Rivers provide water, irrigation, and habitat for aquatic species, vital for ecosystems.", "Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET.", "Shakespeare's works, like 'Hamlet' and 'A Midsummer Night's Dream,' endure in literature." ] # Search query query = "When is Apple's conference call scheduled?" # Generate embeddings for documents doc_embeddings = vo.embed( texts=documents, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for query query_embedding = vo.embed( texts=[query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product similarities = np.dot(doc_embeddings, query_embedding) # Sort by similarity (highest to lowest) ranked_indices = np.argsort(-similarities) # Display results before reranking print(f"Query: '{query}'\n") print("Before reranker (embedding similarity only):") for rank, idx in enumerate(ranked_indices[:3], 1): print(f"{rank}. {documents[idx]}") print(f" Similarity Score: {similarities[idx]:.4f}\n") # Rerank documents for improved accuracy rerank_results = vo.rerank( query=query, documents=documents, model="rerank-2.5" ) # Display results after reranking print("\nAfter reranker:") for rank, result in enumerate(rerank_results.results[:3], 1): print(f"{rank}. {documents[result.index]}") print(f" Relevance Score: {result.relevance_score:.4f}\n")
터미널에서 다음 명령을 실행하세요.
python semantic_search_reranker.py
Query: 'When is Apple's conference call scheduled?' Before reranker (embedding similarity only): 1. Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET. Similarity Score: 0.6691 2. 20th-century innovations, from radios to smartphones, centered on electronic advancements. Similarity Score: 0.2751 3. Shakespeare's works, like 'Hamlet' and 'A Midsummer Night's Dream,' endure in literature. Similarity Score: 0.2335 After reranker: 1. Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET. Relevance Score: 0.9453 2. 20th-century innovations, from radios to smartphones, centered on electronic advancements. Relevance Score: 0.2832 3. The Mediterranean diet emphasizes fish, olive oil, and vegetables, believed to reduce chronic diseases. Relevance Score: 0.2637
프로젝트 에
semantic_search_multilingual.py라는 파일 만들고 다음 코드를 붙여넣습니다.
import voyageai import numpy as np # Initialize Voyage AI client vo = voyageai.Client() # English documents about technology companies english_docs = [ "Apple announced record-breaking revenue in its latest quarterly earnings report.", "The Mediterranean diet emphasizes fish, olive oil, and vegetables.", "Microsoft is investing heavily in artificial intelligence and cloud computing.", "Shakespeare's plays continue to influence modern literature and theater." ] # Spanish documents about technology companies spanish_docs = [ "Apple anunció ingresos récord en su último informe trimestral de ganancias.", "La dieta mediterránea enfatiza el pescado, el aceite de oliva y las verduras.", "Microsoft está invirtiendo fuertemente en inteligencia artificial y computación en la nube.", "Las obras de Shakespeare continúan influenciando la literatura y el teatro modernos." ] # Chinese documents about technology companies chinese_docs = [ "苹果公司在最新季度财报中宣布创纪录的收入。", "地中海饮食强调鱼类、橄榄油和蔬菜。", "微软正在大力投资人工智能和云计算。", "莎士比亚的作品继续影响现代文学和戏剧。" ] # Perform semantic search in English english_query = "tech company earnings" # Generate embeddings for English documents english_embeddings = vo.embed( texts=english_docs, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for English query english_query_embedding = vo.embed( texts=[english_query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product english_similarities = np.dot(english_embeddings, english_query_embedding) # Sort by similarity (highest to lowest) english_ranked = np.argsort(-english_similarities) print(f"English Query: '{english_query}'\n") for rank, idx in enumerate(english_ranked[:2], 1): print(f"{rank}. {english_docs[idx]}") print(f" Similarity: {english_similarities[idx]:.4f}\n") # Perform semantic search in Spanish spanish_query = "ganancias de empresas tecnológicas" # Generate embeddings for Spanish documents spanish_embeddings = vo.embed( texts=spanish_docs, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for Spanish query spanish_query_embedding = vo.embed( texts=[spanish_query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product spanish_similarities = np.dot(spanish_embeddings, spanish_query_embedding) # Sort by similarity (highest to lowest) spanish_ranked = np.argsort(-spanish_similarities) print(f"Spanish Query: '{spanish_query}'\n") for rank, idx in enumerate(spanish_ranked[:2], 1): print(f"{rank}. {spanish_docs[idx]}") print(f" Similarity: {spanish_similarities[idx]:.4f}\n") # Perform semantic search in Chinese chinese_query = "科技公司收益" # Generate embeddings for Chinese documents chinese_embeddings = vo.embed( texts=chinese_docs, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for Chinese query chinese_query_embedding = vo.embed( texts=[chinese_query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product chinese_similarities = np.dot(chinese_embeddings, chinese_query_embedding) # Sort by similarity (highest to lowest) chinese_ranked = np.argsort(-chinese_similarities) print(f"Chinese Query: '{chinese_query}'\n") for rank, idx in enumerate(chinese_ranked[:2], 1): print(f"{rank}. {chinese_docs[idx]}") print(f" Similarity: {chinese_similarities[idx]:.4f}\n")
터미널에서 다음 명령을 실행하세요.
python semantic_search_multilingual.py
English Query: 'tech company earnings' 1. Apple announced record-breaking revenue in its latest quarterly earnings report. Similarity: 0.5172 2. Microsoft is investing heavily in artificial intelligence and cloud computing. Similarity: 0.4745 Spanish Query: 'ganancias de empresas tecnológicas' 1. Apple anunció ingresos récord en su último informe trimestral de ganancias. Similarity: 0.5232 2. Microsoft está invirtiendo fuertemente en inteligencia artificial y computación en la nube. Similarity: 0.4871 Chinese Query: '科技公司收益' 1. 苹果公司在最新季度财报中宣布创纪录的收入。 Similarity: 0.4725 2. 微软正在大力投资人工智能和云计算。 Similarity: 0.4426
샘플 이미지를 검색하여 프로젝트 디렉토리 에 저장합니다. 다음 코드 예시 고양이, 개, 바나나 이미지가 있다고 가정합니다.
프로젝트 에
semantic_search_multimodal.py라는 파일 만들고 다음 코드를 붙여넣습니다.
import voyageai import numpy as np from PIL import Image # Initialize Voyage AI client vo = voyageai.Client() # Prepare interleaved text + image inputs interleaved_inputs = [ ["An orange cat", Image.open('cat.jpg')], ["A golden retriever", Image.open('dog.jpg')], ["A banana", Image.open('banana.jpg')], ] # Prepare image-only inputs image_only_inputs = [ [Image.open('cat.jpg')], [Image.open('dog.jpg')], [Image.open('banana.jpg')], ] # Labels for display labels = ["cat.jpg", "dog.jpg", "banana.jpg"] # Search query query = "a cute pet" # Generate embeddings for interleaved text + image inputs interleaved_embeddings = vo.multimodal_embed( inputs=interleaved_inputs, model="voyage-multimodal-3.5" ).embeddings # Generate embedding for query query_embedding = vo.multimodal_embed( inputs=[[query]], model="voyage-multimodal-3.5" ).embeddings[0] # Calculate similarity scores using dot product interleaved_similarities = np.dot(interleaved_embeddings, query_embedding) # Sort by similarity (highest to lowest) interleaved_ranked = np.argsort(-interleaved_similarities) print(f"Query: '{query}'\n") print("Search with interleaved text + image:") for rank, idx in enumerate(interleaved_ranked, 1): print(f"{rank}. {interleaved_inputs[idx][0]}") print(f" Similarity: {interleaved_similarities[idx]:.4f}\n") # Generate embeddings for image-only inputs image_only_embeddings = vo.multimodal_embed( inputs=image_only_inputs, model="voyage-multimodal-3.5" ).embeddings # Calculate similarity scores using dot product image_only_similarities = np.dot(image_only_embeddings, query_embedding) # Sort by similarity (highest to lowest) image_only_ranked = np.argsort(-image_only_similarities) print("\nSearch with image-only:") for rank, idx in enumerate(image_only_ranked, 1): print(f"{rank}. {labels[idx]}") print(f" Similarity: {image_only_similarities[idx]:.4f}\n")
터미널에서 다음 명령을 실행하세요.
python semantic_search_multimodal.py
Query: 'a cute pet' Search with interleaved text + image: 1. An orange cat Similarity: 0.2685 2. A golden retriever Similarity: 0.2325 3. A banana Similarity: 0.1564 Search with image-only: 1. dog.jpg Similarity: 0.2485 2. cat.jpg Similarity: 0.2438 3. banana.jpg Similarity: 0.1210
프로젝트 에
semantic_search_contextualized.py라는 파일 만들고 다음 코드를 붙여넣습니다.
import voyageai import numpy as np # Initialize Voyage AI client vo = voyageai.Client() # Sample documents (each document is a list of chunks that share context) documents = [ [ "This is the SEC filing on Greenery Corp.'s Q2 2024 performance.", "The company's revenue increased by 7% compared to the previous quarter." ], [ "This is the SEC filing on Leafy Inc.'s Q2 2024 performance.", "The company's revenue increased by 15% compared to the previous quarter." ], [ "This is the SEC filing on Elephant Ltd.'s Q2 2024 performance.", "The company's revenue decreased by 2% compared to the previous quarter." ] ] # Search query query = "What was the revenue growth for Leafy Inc. in Q2 2024?" # Generate contextualized embeddings (preserves relationships between chunks) contextualized_result = vo.contextualized_embed( inputs=documents, model="voyage-context-3", input_type="document" ) # Flatten the embeddings and chunks for semantic search contextualized_embeddings = [] all_chunks = [] chunk_to_doc = [] # Maps chunk index to document index for doc_idx, result in enumerate(contextualized_result.results): for emb, chunk in zip(result.embeddings, documents[doc_idx]): contextualized_embeddings.append(emb) all_chunks.append(chunk) chunk_to_doc.append(doc_idx) # Generate contextualized query embedding query_embedding_ctx = vo.contextualized_embed( inputs=[[query]], model="voyage-context-3", input_type="query" ).results[0].embeddings[0] # Calculate similarity scores using dot product similarities_ctx = np.dot(contextualized_embeddings, query_embedding_ctx) # Sort by similarity (highest to lowest) ranked_indices_ctx = np.argsort(-similarities_ctx) # Display top 3 results print(f"Query: '{query}'\n") for rank, idx in enumerate(ranked_indices_ctx[:3], 1): doc_idx = chunk_to_doc[idx] print(f"{rank}. {all_chunks[idx]}") print(f" (From document: {documents[doc_idx][0]})") print(f" Similarity: {similarities_ctx[idx]:.4f}\n")
터미널에서 다음 명령을 실행하세요.
python semantic_search_contextualized.py
Query: 'What was the revenue growth for Leafy Inc. in Q2 2024?' 1. The company's revenue increased by 15% compared to the previous quarter. (From document: This is the SEC filing on Leafy Inc.'s Q2 2024 performance.) Similarity: 0.7138 2. This is the SEC filing on Leafy Inc.'s Q2 2024 performance. (From document: This is the SEC filing on Leafy Inc.'s Q2 2024 performance.) Similarity: 0.6630 3. The company's revenue increased by 7% compared to the previous quarter. (From document: This is the SEC filing on Greenery Corp.'s Q2 2024 performance.) Similarity: 0.5531
프로젝트 에
semantic_search_large_corpus.py라는 파일 만들고 다음 코드를 붙여넣습니다.
import voyageai import numpy as np from datasets import load_dataset from collections import defaultdict # Initialize Voyage AI client vo = voyageai.Client() # Load legal benchmark dataset corpus_ds = load_dataset("mteb/legalbench_consumer_contracts_qa", "corpus")["corpus"] queries_ds = load_dataset("mteb/legalbench_consumer_contracts_qa", "queries")["queries"] qrels_ds = load_dataset("mteb/legalbench_consumer_contracts_qa")["test"] # Extract corpus and query data corpus_ids = [row["_id"] for row in corpus_ds] corpus_texts = [row["text"] for row in corpus_ds] query_ids = [row["_id"] for row in queries_ds] query_texts = [row["text"] for row in queries_ds] # Build relevance mapping (defaultdict creates sets for missing keys) qrels = defaultdict(set) for row in qrels_ds: if row["score"] > 0: qrels[row["query-id"]].add(row["corpus-id"]) # Generate embeddings for the entire corpus print(f"Generating embeddings for {len(corpus_texts)} documents...") corpus_embeddings = vo.embed( texts=corpus_texts, model="voyage-4-large", input_type="document" ).embeddings # Select a sample query query_idx = 1 query = query_texts[query_idx] query_id = query_ids[query_idx] # Generate embedding for the query query_embedding = vo.embed( texts=[query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product similarities = np.dot(corpus_embeddings, query_embedding) # Sort by similarity (highest to lowest) ranked_indices = np.argsort(-similarities) # Display top 5 results print(f"Query: {query}\n") print("Top 5 Results:") for rank, idx in enumerate(ranked_indices[:5], 1): doc_id = corpus_ids[idx] is_relevant = "✓" if doc_id in qrels[query_id] else "✗" print(f"{rank}. [{is_relevant}] Document ID: {doc_id}") print(f" Similarity: {similarities[idx]:.4f}") print(f" Text: {corpus_texts[idx][:100]}...\n") # Show the ground truth most relevant document most_relevant_id = list(qrels[query_id])[0] most_relevant_idx = corpus_ids.index(most_relevant_id) print(f"Ground truth most relevant document:") print(f"Document ID: {most_relevant_id}") print(f"Rank in results: {np.where(ranked_indices == most_relevant_idx)[0][0] + 1}") print(f"Similarity: {similarities[most_relevant_idx]:.4f}")
터미널에서 다음 명령을 실행하세요.
python semantic_search_large_corpus.py
Generating embeddings for 154 documents... Query: Will Google come to a users assistance in the event of an alleged violation of such users IP rights? Top 5 Results: 1. [✓] Document ID: 9NIQ0Wobtq Similarity: 0.6047 Text: Your content Some of our services give you the opportunity to make your content publicly available ... 2. [✗] Document ID: gAk7Gdp0CX Similarity: 0.5515 Text: Taking action in case of problems Before taking action as described below, well provide you with adv... 3. [✗] Document ID: S87XwXaHCP Similarity: 0.5178 Text: Privacy and Data Protection Our Privacy Center explains how we treat your personal data. By using th... 4. [✗] Document ID: 8IRh1E2JDB Similarity: 0.5134 Text: OUR PROPERTY The Service is protected by copyright, trademark, and other US and foreign laws. These ... 5. [✗] Document ID: 50OXirZRiR Similarity: 0.5098 Text: Uploading Content If you have a YouTube channel, you may be able to upload Content to the Service. Y... Ground truth most relevant document: Document ID: 9NIQ0Wobtq Rank in results: 1 Similarity: 0.6047
예시 정보
다음 표에는 이 페이지의 예시가 요약되어 있습니다.
예시 | 사용 모델 | 결과 이해 |
|---|---|---|
기본 시맨틱 검색 |
| Apple 화상 회의 문서 관련 없는 문서보다 훨씬 높은 1위를 차지하여 정확한 시맨틱 매칭을 보여줍니다. |
Reranker를 사용한 시맨틱 검색 |
| 순위를 재지정하면 전체 쿼리-문서 관계 분석하여 검색 정확도가 향상됩니다. 유사성을 임베드하는 것만으로도 보통의 점수로 올바른 문서 순위를 매기는 반면, 재순위 지정기는 관련성 점수를 크게 높여 관련 없는 결과로부터 문서를 더 잘 구분합니다. |
다국어 시맨틱 검색 |
| Voyage 모델은 다양한 언어에 걸쳐 시맨틱 검색 효과적으로 수행합니다. 이 예시 영어, 스페인어, 중국어로 세 가지 개별 검색을 수행하여 각각의 언어 내에서 기술 회사 수익에 대한 가장 관련성이 높은 문서를 올바르게 식별하는 방법을 보여 줍니다. |
멀티모달 시맨틱 검색 |
| 이 모델은 인터리브 처리된 텍스트, 이미지, 동영상은 물론 이미지 전용 및 동영상 전용 검색 도 지원합니다. 두 경우 모두 애완동물 이미지(고양이와 개)의 순위가 관련이 없는 바나나 이미지보다 훨씬 높으며, 이는 정확한 시각적 콘텐츠 검색을 보여줍니다. 설명 텍스트가 있는 인터리브 입력은 이미지 전용 입력보다 약간 더 높은 유사성 점수를 생성합니다. |
상황별 청크 임베딩 |
| 15% 수익 증가율 청크 Leafy Inc. 문서 에 연결되어 있기 때문에 1위를 차지합니다. 그리너리의 유사한 7% 성장 청크 점수가 더 낮으며, 이는 모델이 문서 컨텍스트를 정확하게 고려하여 유사한 청크를 구분하는 방법을 보여줍니다. |
대규모 코퍼스를 사용한 시맨틱 검색 |
| 사용자 콘텐츠에 대한 실측값 문서 154 문서 중 1위를 차지하며, 의미론적 복잡성에도 불구하고 확장하다 로 효과적인 검색을 보여줍니다. |
- 임베딩 액세스
이 예시에서는
VOYAGE_API_KEY환경 변수에서 API 키를 자동으로 읽는 Python 클라이언트voyageai.Client()를 사용합니다. API 응답 객체 반환합니다. 실제 임베딩 벡터에 액세스 하려면.embeddings속성을 사용합니다.result = vo.embed(texts=["example"], model="voyage-4-large", input_type="document") embeddings = result.embeddings # List of embedding vectors - 유사성 계산
이 예제에서는 Numpy의 내적 함수인
np.dot()을 사용하여 쿼리 와 문서 임베딩 간의 유사성 점수를 계산합니다. Voyage AI 임베딩은 길이 1로 정규화되므로 내적은 수학적으로 코사인 유사도와 동일합니다.유사도별로 결과의 순위를 지정하기 위해 예시에서는 Numpy의
argsort()함수를 사용하여 상위 N개의 결과를 표시합니다. 음수 기호는 내림차순으로 정렬되므로 유사성 점수가 가장 높은 것이 먼저 표시됩니다.- 입력 유형 매개변수
input_type매개변수를query또는document로 설정하다 Voyage AI 모델이 벡터를 생성하는 방식을 최적화합니다. 이 매개변수를 생략하지 마세요. 자세한 학습 은 입력 유형 지정을 참조하세요.
자세한 학습 은 Accessing Voyage AI Models(Voyage AI 모델 액세스) 를 참조하거나 전체 API 사양을 살펴보세요.
시맨틱 검색이란 무엇인가요?
시맨틱 검색 데이터의 시맨틱 또는 기본 의미를 기반으로 결과를 반환하는 검색 방법입니다. 일치하는 텍스트를 찾는 기존의 전체 텍스트 검색 과 달리 시맨틱 검색 벡터를 다차원 공간에서 검색 쿼리 에 가까운 벡터를 찾습니다. 벡터가 쿼리 에 가까울수록 의미가 유사합니다.
예시
기존 텍스트 검색 정확히 일치하는 항목만 반환하므로 사용자가 데이터에 있는 텀과 다른 텀으로 검색 경우 결과가 제한됩니다. 예시 들어 데이터에 컴퓨터 마우스 및 동물 마우스에 대한 문서가 포함된 경우 컴퓨터 마우스에 대한 정보를 찾으려고 할 때 'mouse'를 검색하면 잘못된 일치 항목이 발생합니다.
그러나 시맨틱 검색 어휘 중복이 없는 경우에도 단어나 구 간의 기본 관계 캡처합니다. 컴퓨터 제품을 검색할 때 '마우스'를 검색하면 더 관련성 높은 결과를 얻을 수 있습니다. 이는 시맨틱 검색 검색 쿼리 의 의미론적 의미를 데이터와 비교하여 정확한 검색 에 관계없이 가장 관련성이 높은 결과만 반환하기 때문입니다.

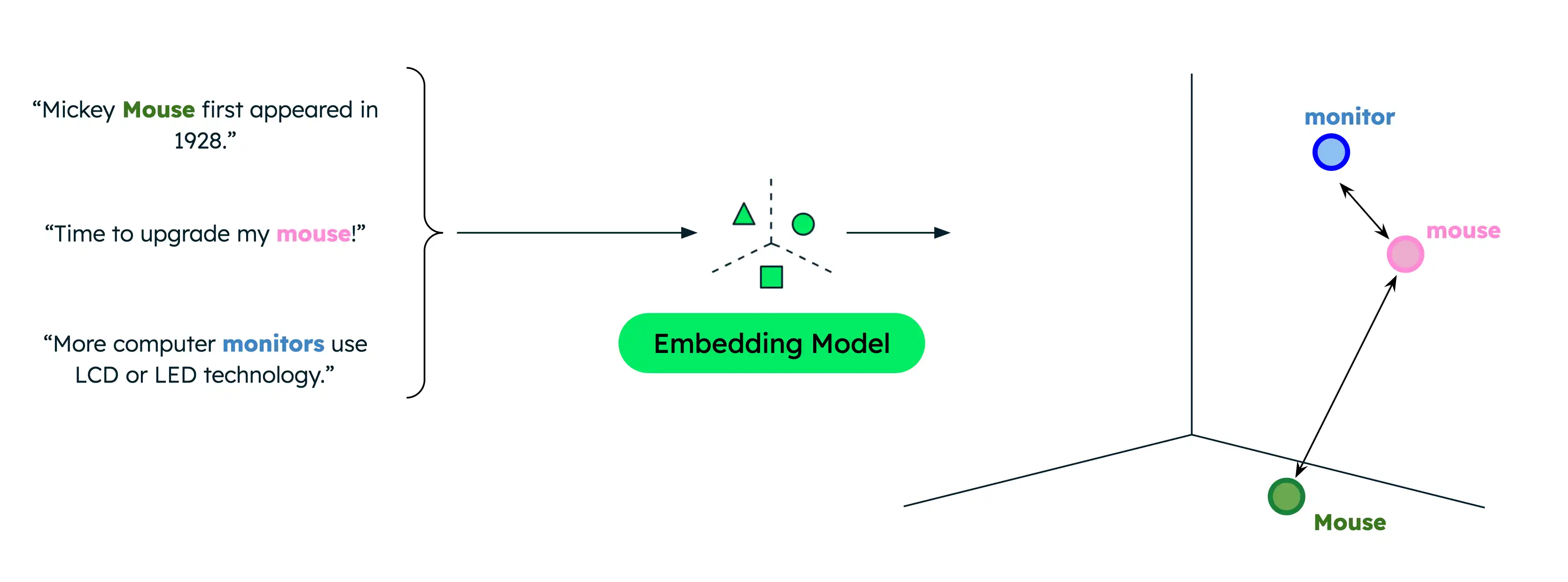
유사성 함수 는 두 벡터가 서로 얼마나 가까운지, 즉 얼마나 유사한지를 측정합니다. 일반적인 함수에는 내적, 코사인 유사성 및 유클리드 거리가 포함됩니다. Voyage AI 임베딩은 길이 1으로 정규화되며, 이는 다음을 의미합니다.
코사인 유사성은 내적 유사성과 동일하지만 후자는 더 빠르게 계산할 수 있습니다.
코사인 유사도와 유클리드 거리의 결과는 동일한 순위가 됩니다.
프로덕션 환경에서의 시맨틱 검색
벡터를 메모리에 저장하고 자체 검색 파이프라인을 구현하는 것은 프로토타입 및 실험에 적합하지만, 프로덕션 애플리케이션에는 벡터 데이터베이스 와 엔터프라이즈 검색 솔루션을 사용하면 더 큰 코퍼스에서 효율적으로 검색을 수행할 수 있습니다.
MongoDB 벡터 저장 및 조회를 네이티브 지원 하므로 다른 데이터와 함께 벡터 임베딩을 저장하고 검색할 때 편리합니다. MongoDB Vector Search로 시맨틱 검색 수행하는 방법에 대한 튜토리얼을 완료하려면 Atlas 클러스터의 데이터에 대해 시맨틱 검색을 수행하는 방법을 참조하세요.
다음 단계
시맨틱 검색 과 LLM을 결합하여 RAG 애플리케이션구현 .