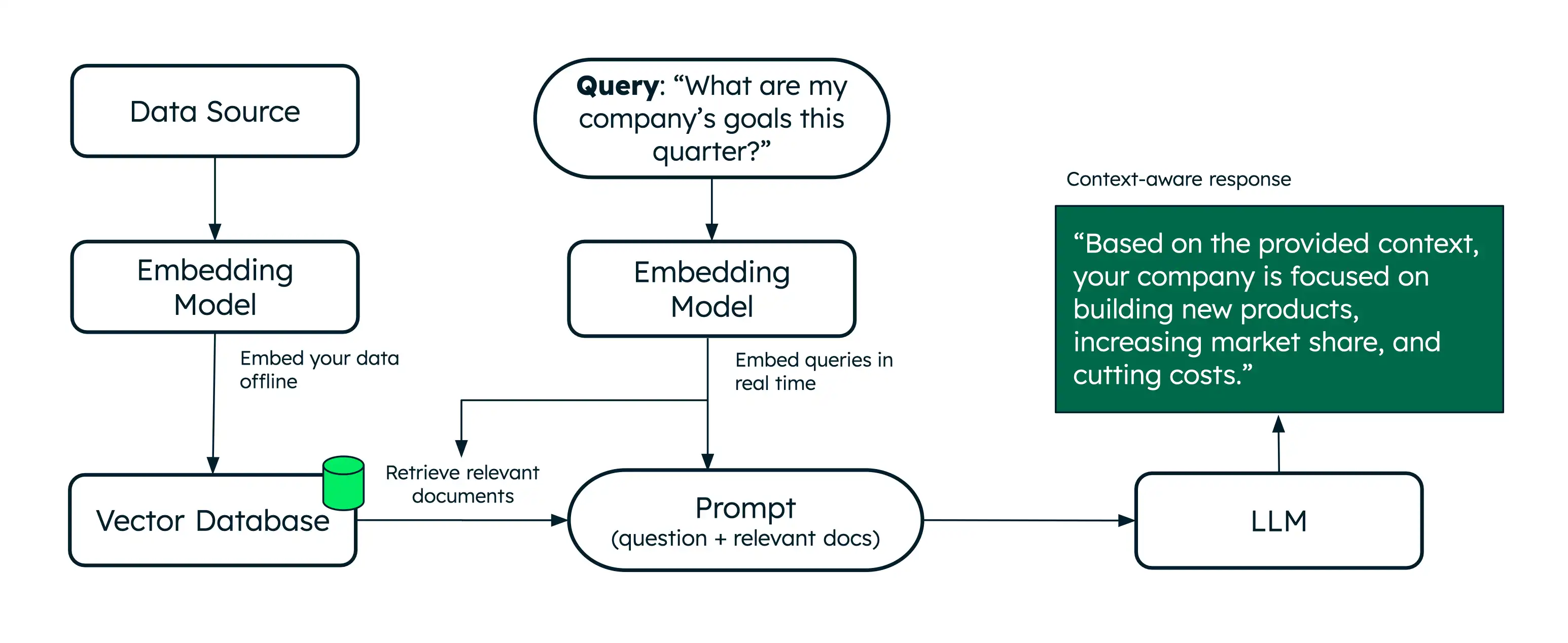
RAG(검색 강화 생성)는 시맨틱 검색 사용하여 추가 데이터로 대규모 언어 모델(LLM)을 보강하여 보다 정확한 응답을 생성할 수 있는 아키텍처입니다.
시맨틱 검색 의미를 기반으로 관련 문서를 검색하는 반면, RAG는 검색된 문서를 컨텍스트로 LLM에 제공하여 이를 한 단계 더 발전시킵니다. 이러한 추가 컨텍스트는 LLM이 사용자의 쿼리 에 대한 보다 정확한 응답을 생성하여 환각을 줄이는 데 도움이 됩니다. Voyage AI 동급 최고의 임베딩 및 리랭킹 모델을 제공하여 RAG 애플리케이션의 검색을 강화합니다.
코드를 작성하지 않고 RAG를 사용해 보려면 플레이그라운드를 사용하여 Voyage AI 기반 AI 챗봇을 빌드 . 자세한 학습 은 챗봇 데모 빌더를 참조하세요.
튜토리얼
다음 튜토리얼에서는 Voyage 임베딩을 사용하여 RAG를 구현 방법을 보여 줍니다.
GitHub리포지토리 복제하여 이 튜토리얼의 코드로 작업할 수도 있습니다.
왜 RAG를 사용해야 하나요?
LLM으로 작업할 때 다음과 같은 제한 사항이 발생할 수 있습니다.
오래된 데이터: LLM은 특정 점 까지의 정적 데이터 세트에서 학습됩니다. 즉, 지식 기반이 제한되어 있고 오래된 데이터를 사용할 수 있습니다.
추가 데이터에 대한 액세스 없음: LLM은 로컬, 개인화된 또는 도메인별 데이터에 액세스 할 수 없습니다. 따라서 특정 도메인에 대한 지식이 부족할 수 있습니다.
환각: 불완전하거나 오래된 데이터를 사용하는 경우 LLM은 부정확한 응답을 생성할 수 있습니다.
RAG는 일반적으로 시맨틱 검색 기반 되는 조회 단계를 추가하여 관련 문서를 실시간 가져오는 방식으로 이러한 제한을 해결합니다. 추가 컨텍스트를 제공하면 LLM이 더 정확한 응답을 생성하는 데 도움이 됩니다. 따라서 RAG는 도메인별 맞춤 질문 답변 및 텍스트 생성을 제공하는 AI 챗봇을 구축하기 위한 효과적인 아키텍처입니다.
벡터 데이터베이스란 무엇인가요?
벡터 데이터베이스는 벡터 임베딩을 저장 하고 효율적으로 조회 하도록 설계된 특수 데이터베이스입니다. 벡터를 메모리에 저장하는 것은 프로토타입 제작 및 실험에 적합하지만, 프로덕션 RAG 애플리케이션은 일반적으로 더 큰 코퍼스에서 효율적인 검색을 수행하기 위해 벡터 데이터베이스 필요합니다.
MongoDB 벡터 저장 및 조회를 네이티브 지원 하므로 다른 데이터와 함께 벡터 임베딩을 저장하고 검색할 때 편리합니다. 자세한 학습 은 MongoDB 벡터 검색 개요를 참조하세요.
다음 단계
추가 튜토리얼은 다음 리소스를 참조하세요.
널리 사용되는 LLM 프레임워크 및 AI 서비스로 RAG를 구현 방법을 학습 MongoDB AI 통합을 참조하세요.
AI 에이전트를 빌드 하고 에이전트 RAG를 구현 하려면 MongoDB 로 AI 에이전트 빌드를 참조하세요.