Deep learning is a subfield of artificial intelligence (AI) that teaches computers to learn from data by using layered neural networks modeled loosely on the human brain. These deep neural networks automatically discover patterns and representations in large, complex datasets—from images and text to audio and video—without requiring explicit programming.
Deep learning powers many of , from voice assistants and recommendation systems to medical imaging and autonomous vehicles. In this article, we’ll explore how deep neural networks work, how their layers process and refine information, and why they’ve become a cornerstone of modern AI systems.
Table of Contents:
- Difference between deep learning, machine learning, and AI
- How deep learning is similar to the human brain
- How is deep learning different from the brain?
- Layers of deep neural networks
- How layers train the deep learning algorithms
- Deep learning models
- Deep learning model in real-world applications
- Challenges in deep learning
- Conclusion
- FAQs
Difference between deep learning, machine learning, and AI
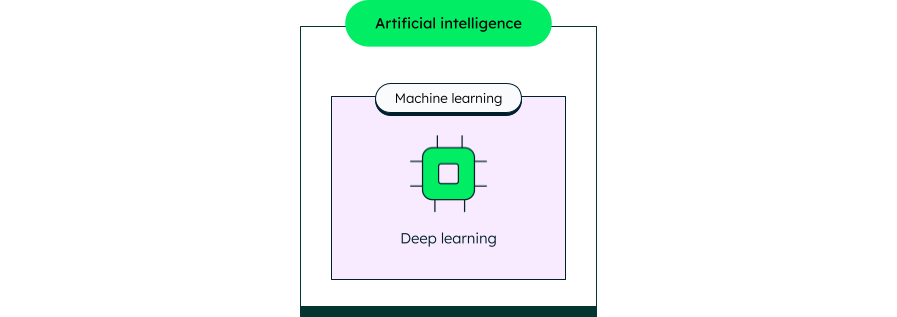
Think of AI, machine learning, and deep learning as layers of an onion. AI is the outer layer, encompassing all intelligent systems. Machine learning sits inside it, giving systems the ability to learn from data. Deep learning is the core—a subset of machine learning that uses multi-layered neural networks to solve more complex tasks.
Artificial intelligence (AI)
AI includes a variety of approaches and technologies. It's the broadest concept that refers to machines or systems being able to perform tasks that typically require human intelligence. These tasks include problem-solving, learning, planning, linguistic understanding, and perception. AI systems use a variety of algorithms, from simple rule-based algorithms to complex machine learning algorithms, to complete these tasks.
Machine learning
Machine learning (ML) is a subset of AI that enables systems to learn from data and improve their performance over time without being explicitly programmed. ML models use statistical and optimization techniques to uncover patterns and make predictions or decisions.
While ML often uses structured, labeled data, some ML techniques (like unsupervised learning) can work with unlabeled or semi-structured data. However, preprocessing is typically required to make the data usable. ML excels at spam detection, credit scoring, and recommendations.
Deep learning
Deep learning minimizes the need for manual feature engineering by automatically learning hierarchical representations of data through multiple neural network layers. These networks—often composed of many hidden layers—handle unstructured data such as images, text, and audio with minimal human intervention.
How deep learning is similar to the human brain
Deep learning takes loose inspiration from how the human brain processes information. Both the brain and artificial neural networks are composed of interconnected units that transmit signals and learn from experience. In the brain, these are biological neurons linked by synapses; in artificial neural networks, they are mathematical neurons connected by weighted parameters that adjust during training.
Layered processing: The brain processes information across specialized regions and layers that handle different types of sensory and cognitive input. Similarly, deep learning models use layered architectures where each layer extracts increasingly complex representations of data. Hidden layers perform most of the computation, transforming low-level features (like pixels or sound frequencies) into higher-level patterns.
Pattern recognition: Both systems excel at identifying patterns and making decisions based on them. Deep neural networks learn statistical relationships in data—such as shapes in images or meanings in text—much like how the brain recognizes faces, sounds, and language patterns through repeated exposure and adaptation.
How is deep learning different from the brain?
While deep learning draws inspiration from the brain, the similarities are largely structural metaphors rather than functional realities. The human brain remains vastly more complex, efficient, and adaptable than any artificial neural network.
Consciousness and cognition: The brain possesses consciousness, reasoning, and emotional intelligence—capabilities far beyond current AI systems. Neural networks can simulate narrow cognitive tasks like recognition or prediction but lack understanding, awareness, and the ability to reason abstractly and experience emotion.
Learning requirements: Humans can learn new concepts from just a few examples and generalize knowledge across contexts. Deep learning models, by contrast, require enormous labeled datasets and extensive computational resources to achieve comparable performance in narrow tasks.
Layers of deep neural networks
As outlined above, neural networks are at the heart of deep learning and function through a series of layers having interconnected nodes. Each layer has a specific role in processing and interpreting data. In the below diagram, each neuron (the circle with a plus) of one layer is connected to each neuron of the next layer. For example, there are three neurons in the input layer. Each of these are connected to each of the five neurons of the hidden layer one. The same applies to all the layers. Each neuron represents a specific feature, pixel, text embedding, or a value of the input data.
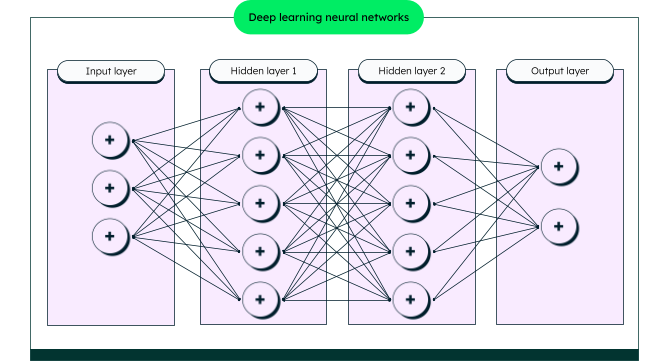
Input layer: The process starts with the input layer, where the neural network receives its data in numerical form so it can communicate digitally. The data along with the weight moves to the first hidden layer.
Hidden layers: The main calculations happen in one or more hidden layers. Hidden layers contain the activation function, which is a mathematical function to determine the output of a neuron based on the input value.
Weights and biases: Each neuron carries weights and biases from the input to the hidden layer. Weights carry the importance of the input data that the neuron carries, and biases shift the results up or down. The neural network adjusts weights and biases as it learns.
Activation functions: Activation functions introduce non-linearity into neural networks, allowing them to learn complex, non-linear relationships in data. They determine how a neuron’s weighted input is transformed before being passed to the next layer. This decision is based on the strength of the signals the neurons receive.
Output layer: This is the final layer that gives the prediction or result. For example, in a task where the network identifies objects in images, it indicates which object the deep neural network believes is present in the image.
How layers train the deep learning algorithms
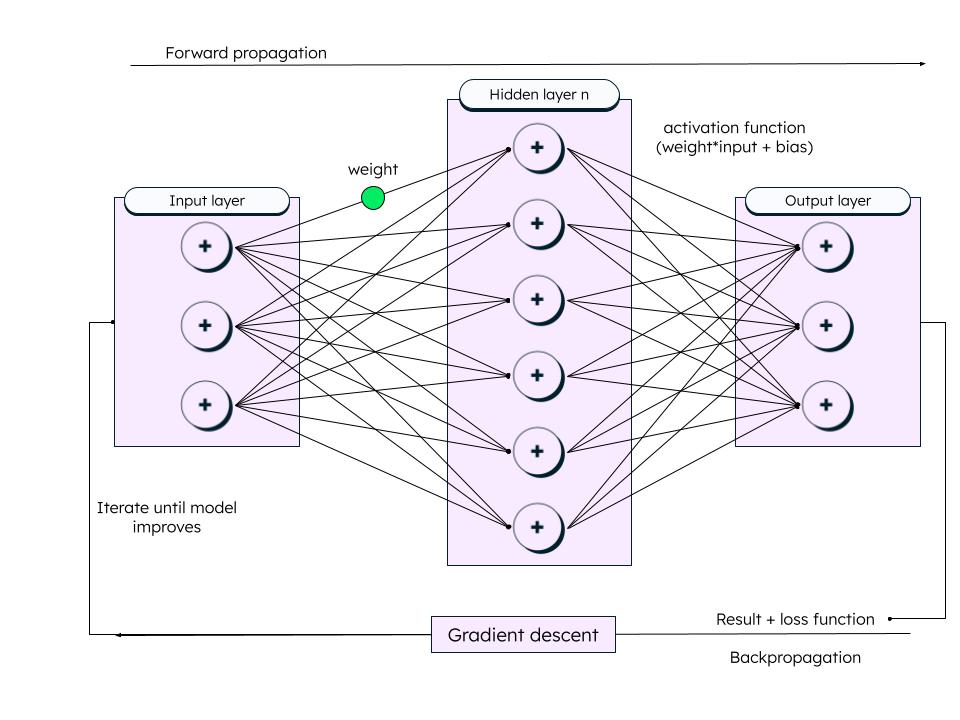
Training deep learning models involves adjusting internal parameters so the model can make accurate predictions. This is done using two key steps: forward propagation and backpropagation, supported by optimization techniques like gradient descent.
Forward propagation: To train deep learning models, the network takes in the training data and processes it through each layer. In a forward propagation deep learning process, every layer makes predictions based on its current weights, biases, and activation functions.
Backpropagation: Once a prediction is done through forward propagation, the neural network looks at its errors and adjusts its weights and biases to improve. This process of updating weights based on the error is called backpropagation. It uses a loss function to measure errors and an optimization algorithm (like gradient descent) to reduce these errors.
Iterative learning: The network goes through many such training cycles (epochs), continuously refining weights and biases. Over time, this iterative process improves accuracy and reduces prediction error.
Gradient descent: Gradient descent is an optimization algorithm used to minimize a model’s loss function by iteratively adjusting weights in the direction that reduces prediction error.
Deep learning models
Deep learning algorithms learn to produce accurate outputs through a training process. The model identifies complex patterns and features from large amounts of data. Deep learning models such as CNNs, RNNs, and transformers use training algorithms like gradient descent and backpropagation to learn patterns and make accurate predictions. MongoDB Atlas is often used to store and process large-scale datasets for deep learning workflows due to its flexible model and scalability.
Convolutional neural network (CNN)
CNNs are used for computer vision, image recognition, and object detection. A good example is how photo-tagging systems (like Google Photos) use CNN-based feature extraction to detect shapes, textures, and edges in images as part of broader facial recognition or image classification pipelines.
Generative adversarial network (GAN)
GANs are used to create realistic images and videos, such as generating human faces from random noise. They are valuable in research for generating additional training data and expanding small datasets. GANs are also widely used for image-to-image translation—for example, converting a photo into a sketch or turning a black-and-white image into a color one. Additionally, they can be applied in anomaly detection by learning what normal data looks like and flagging deviations.
Recurrent neural network (RNN)
RNNs are well-suited for sequential data such as time-series, text, and audio because they maintain a form of memory by using hidden states that retain information from previous inputs. The output from one layer feeds as input to the next layer. RNNs are used for sequential tasks like sentiment analysis and speech recognition, but their reliance on sequential processing makes them slower and prone to vanishing gradient issues. Modern architectures like transformers have largely supplanted RNNs for many NLP tasks. MongoDB time series collections are optimized for storing and querying sequential data, making it an excellent fit for applications like sensor monitoring.
Autoencoder
An autoencoder compresses input data into a lower-dimensional latent space and then reconstructs it as accurately as possible. This makes it valuable for dimensionality reduction, denoising, and anomaly detection tasks.
Transformer model
The transformer model uses a concept called self-attention to understand the context of a sentence by examining how each word relates to all other words, regardless of their position. It can process large amounts of data in parallel, making it faster and more efficient than older models. The transformer architecture is the foundation for large language models like ChatGPT, Copilot, and many others. While transformer models power modern language applications, MongoDB Atlas supports semantic search through its Vector Search feature, enabling developers to integrate model embeddings and build intelligent search experiences.
Deep learning model in real-world applications
While powerful, deep learning comes with its own challenges that can be daunting. Understanding these challenges is crucial for grasping the limitations and considerations necessary when working with deep learning models.
The ability of a deep learning algorithm to process and learn from large datasets makes it ideal for complex tasks that require pattern recognition, decision-making, and prediction.
In many cases, deep learning models are fine-tuned using transfer learning—where a model trained on a large, general dataset is adapted to a specific task with a smaller dataset. This approach is widely used in applications like medical image classification and natural language processing (NLP) tasks, where data may be limited or expensive to collect.
Below are some deep learning applications.
Computer vision, object detection, and facial recognition software
Deep learning technology is pivotal in teaching computers to interpret visual data. They power applications like facial recognition systems in security, photo tagging in social media, and medical imaging for disease diagnosis.
Natural language processing (NLP) systems
In natural language processing, deep learning methods enable machines to understand human language. Deep learning techniques are used for speech recognition, translation services, sentiment analysis, chatbots, and virtual assistants. You can leverage MongoDB Atlas to achieve these use cases with ease by embedding generative AI and advanced search into your applications.
Autonomous vehicles
Self-driving cars use deep learning for object detection, collision avoidance, and navigation. They process vast amounts of data from sensors and cameras placed in various locations so they can understand their surroundings and make driving decisions. MongoDB’s time series and geospatial data storage features help you store sensor data and GPS logs.
Speech recognition applications
Applications like voice-to-text and voice-activated systems use deep learning to understand and process human speech. This technology is why virtual assistants and various speech recognition software are so effective.
Recommendation systems
Online streaming entertainment platforms use deep learning to analyze user behavior and preferences to offer personalized content recommendations.
Medical imaging
Deep learning is widely used in medical imaging to automatically detect cancer cells in scans, helping doctors identify tumors with greater speed and accuracy than traditional machine learning techniques. MongoDB can be your healthcare database, bringing all the healthcare data and medical records in one place, for faster diagnosis and treatment.
Challenges in deep learning
Powerful deep learning comes with its own challenges that can be daunting. Understanding the below challenges is crucial for grasping the limitations and considerations necessary when working with deep learning models:
Complexity: Grasping the intricacies of deep learning models is complex. The way data moves through artificial neurons, layers, and the overall network requires a series of interconnected tasks.
Data requirements: Deep learning models thrive on massive amounts of data. However, having access to such vast datasets is only sometimes feasible. Moreover, even when data is available, not all machines are capable of processing it efficiently, which can be a significant hurdle.
Computational resources: The computational resources required for deep learning are substantial. These models often rely on graphical processing units (GPUs), which offer significantly more cores and processing power than standard central processing units (CPUs). This makes deep learning resource-intensive and potentially expensive.
Training time: Training neural network architectures is a time-consuming process. It can take hours, days, or even months, depending on the dataset's size and the network's complexity.
Bias and privacy concerns: Because deep learning models learn directly from data, they can replicate or amplify existing biases. Addressing fairness and privacy requires active data auditing, balanced datasets, and ongoing monitoring throughout model deployment.
Conclusion
Deep learning today presents a major leap forward, enabling powerful breakthroughs in pattern recognition, decision-making, and automation. Yet, it also highlights critical challenges, including the need for high-quality data, significant computational resources, and thoughtful consideration of ethical implications. As deep learning continues to evolve, it calls for responsible innovation and a balanced approach to its deployment.