Un modello di trasformatore è un progresso fondamentale nel mondo dell'intelligenza artificiale e dell'elaborazione del linguaggio naturale. Rappresenta un tipo di modello di apprendimento profondo che ha svolto un ruolo trasformativo in vari compiti legati al linguaggio. I trasformatori sono progettati per comprendere e generare il linguaggio umano concentrandosi sulle relazioni tra le parole all'interno delle frasi.
Una delle caratteristiche dei modelli trasformatori è l'utilizzo di una tecnica chiamata "self-attention." Questa tecnica permette a questi modelli di elaborare ogni parola di una frase tenendo conto del contesto fornito dalle altre parole della stessa frase. Questa consapevolezza contestuale rappresenta una svolta significativa rispetto ai modelli linguistici precedenti ed è una delle ragioni principali del successo dei trasformatori.
I modelli di trasformatori sono diventati la spina dorsale di molti modelli linguistici moderni di grandi dimensioni. Utilizzando i transformer models, gli developers e i researchers sono stati in grado di creare AI systems più sofisticati e consapevoli del contesto, che interagiscono con il natural language in modi sempre più simili a quelli umani, portando in ultima analisi a miglioramenti significativi nelle user experiences e nelle AI applications.
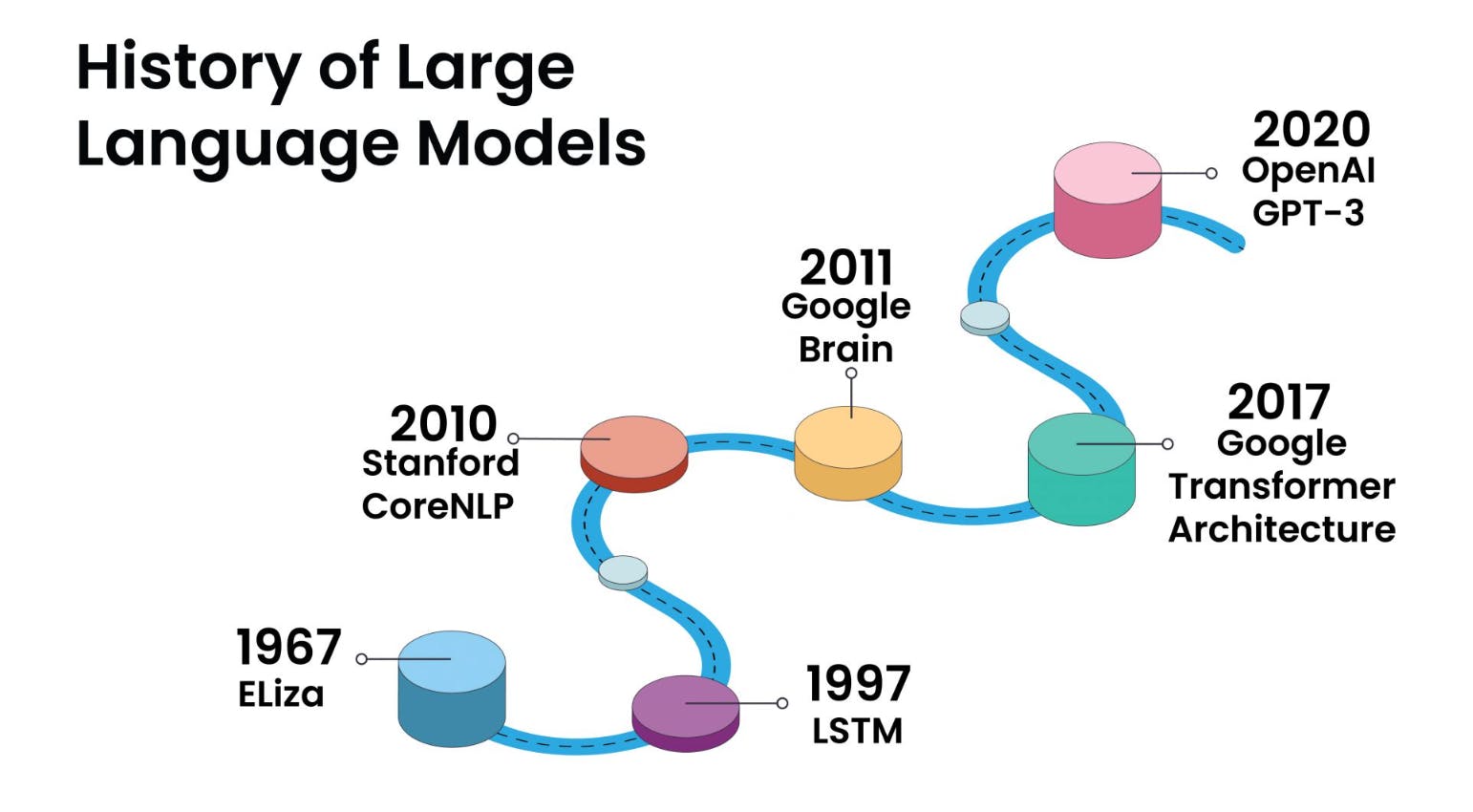
Come funzionano i modelli linguistici di grandi dimensioni?
I modelli linguistici di grandi dimensioni funzionano utilizzando tecniche di apprendimento profondo per elaborare e generare il linguaggio umano.
- Data collection: Il primo passo per l'addestramento degli LLM consiste nel raccogliere un'enorme quantità di testo e codice da Internet. Questo set di dati comprende un'ampia gamma di contenuti scritti dall'uomo, fornendo ai LLM una base linguistica diversificata.
- Dati di pre-addestramento: Durante la fase di pre-addestramento, i LLM sono esposti a questo vasto set di dati. Imparano a prevedere la parola successiva in una frase, il che li aiuta a capire le relazioni statistiche tra parole e frasi. Questo processo permette loro di afferrare la grammatica, la sintassi e anche una certa comprensione del contesto.
- Fine-tuning dei dati: Dopo il pre-addestramento, gli LLM vengono messi a punto per compiti specifici. Ciò comporta l'esposizione a un set di dati più ristretto relativo all'applicazione desiderata, come la traduzione, l'analisi del sentiment o la generazione di testi. La messa a punto affina la capacità di svolgere questi compiti in modo efficace.
- Comprensione contestuale: I LLM considerano le parole che precedono e seguono una determinata parola in una frase, consentendo loro di generare un testo coerente e contestualmente rilevante. Questa consapevolezza contestuale è ciò che distingue gli LLM dai modelli linguistici precedenti.
- Adattamento ai compiti: Grazie alla messa a punto, gli LLM possono adattarsi a un'ampia gamma di compiti. Possono rispondere a domande, generare testi simili a quelli umani, tradurre lingue, riassumere documenti e altro ancora. Questa adattabilità è uno dei principali punti di forza dei LLM.
- Impiego: Una volta addestrati, gli LLM possono essere impiegati in varie applicazioni e sistemi. Alimentano chatbot, motori di generazione di contenuti, motori di ricerca e altre applicazioni di AI, migliorando le user experiences.
In sintesi, i LLM funzionano apprendendo prima le complessità del linguaggio umano attraverso un pre-addestramento su enormi insiemi di dati. Poi mettono a punto le loro capacità per compiti specifici, sfruttando la comprensione del contesto. Questa adattabilità li rende strumenti versatili per un'ampia gamma di applicazioni di elaborazione del linguaggio naturale.
Inoltre, è importante notare che la selezione di un LLM specifico per il vostro caso d'uso, così come i processi di pre-training del modello, la messa a punto e altre personalizzazioni, avvengono indipendentemente da Atlas (e quindi al di fuori di Atlas Vector Search).
Qual è la differenza tra un modello linguistico di grandi dimensioni (LLM) e l'elaborazione del linguaggio naturale (NLP)?
L'elaborazione del linguaggio naturale (NLP) è un settore dell'informatica dedicato a facilitare le interazioni tra computer e linguaggio umano, comprendendo sia la comunicazione parlata che quella scritta. Il suo campo di applicazione comprende la capacità dei computer di comprendere, interpretare e manipolare il linguaggio umano, con applicazioni quali la traduzione automatica, il riconoscimento vocale, la sintesi del testo e la risposta alle domande.
D'altra parte, i modelli linguistici di grandi dimensioni (LLM) emergono come una categoria specifica di modelli NLP. Questi modelli sono sottoposti a un rigoroso addestramento su vasti archivi di testo e codice, che consente loro di discernere intricate relazioni statistiche tra parole e frasi. Di conseguenza, le LLM mostrano la capacità di generare testi coerenti e contestualmente rilevanti. I LLM possono essere utilizzati per una serie di compiti, tra cui la generazione di testi, la traduzione e la risposta a domande.
Esempi di LLM nelle applicazioni del mondo reale
Miglioramento del servizio clienti
Immaginiamo un'azienda che vuole migliorare l'esperienza del servizio clienti: sfrutterà le capacità di un modello linguistico di grandi dimensioni per creare un chatbot in grado di rispondere alle domande dei clienti sui loro prodotti e servizi. Questo chatbot viene sottoposto a un processo di addestramento utilizzando ampi set di dati costituiti dalle domande dei clienti, dalle risposte corrispondenti e da una documentazione dettagliata sui prodotti. Ciò che distingue questo chatbot è la sua profonda comprensione delle intenzioni dei clienti, che gli consente di fornire risposte precise e informative.
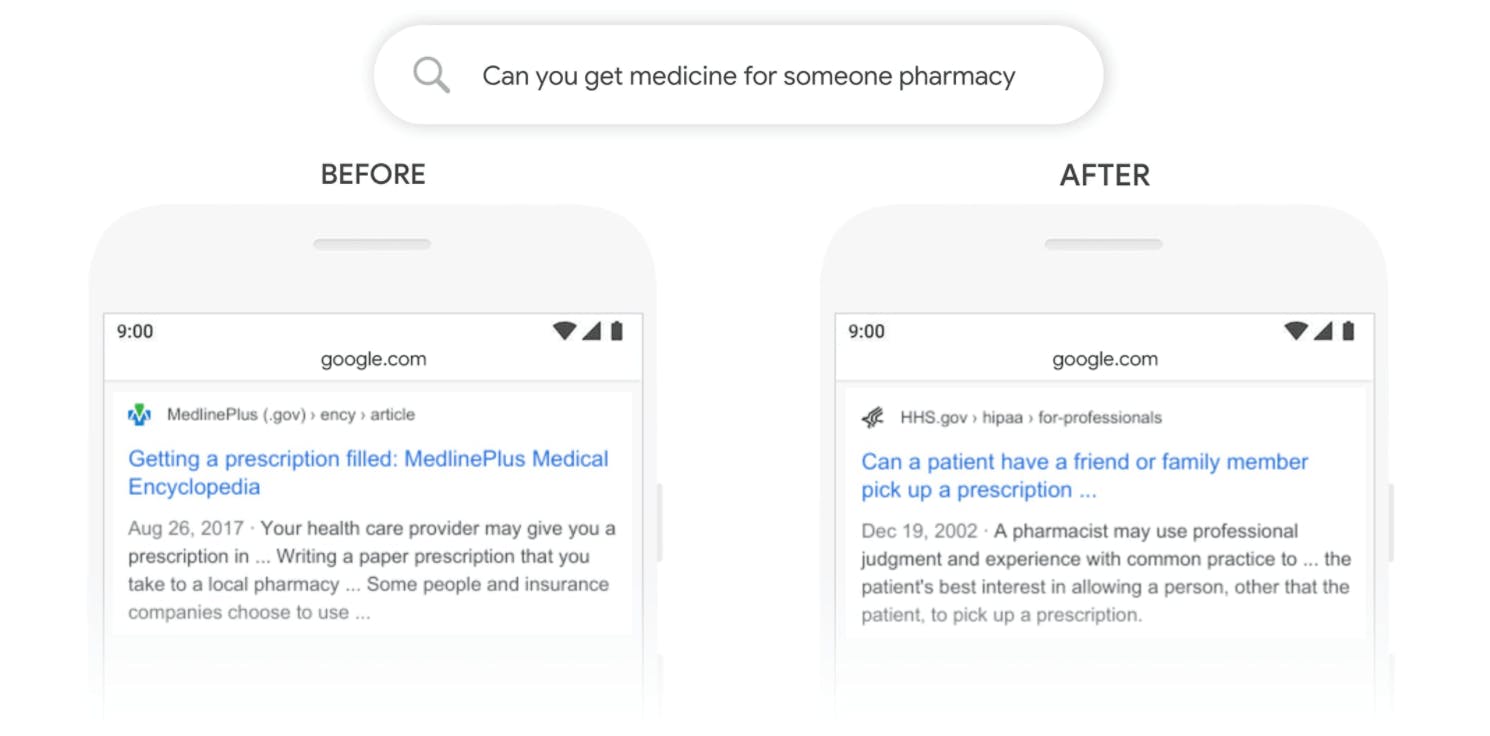
Motori di ricerca più intelligenti
I motori di ricerca fanno parte della nostra vita quotidiana e gli LLM li alimentano, rendendoli più intuitivi. Questi modelli sono in grado di capire ciò che si sta cercando, anche se non è stato formulato perfettamente, e di recuperare i risultati più pertinenti da vasti database, migliorando l'esperienza di ricerca online.
Raccomandazioni personalizzate
Quando si fanno acquisti online o si guardano video su piattaforme di streaming, spesso si vedono raccomandazioni di prodotti o contenuti che potrebbero piacere. Alla base di queste raccomandazioni intelligenti ci sono gli LLM, che analizzano il comportamento passato degli utenti per suggerire cose che corrispondono ai loro gusti, rendendo le esperienze online più personalizzate e su misura.
Generazione di contenuti creativi
Gli LLM non sono solo elaboratori di dati, ma anche menti creative. Dispongono di algoritmi di deep learning in grado di generare contenuti, dai post dei blog alle descrizioni dei prodotti, fino alle poesie. Questo non solo fa risparmiare tempo, ma aiuta anche le aziende a creare contenuti coinvolgenti per il loro pubblico.
Incorporando gli LLM, le aziende migliorano le interazioni con i clienti, le funzionalità di ricerca, le raccomandazioni sui prodotti e la creazione di contenuti, trasformando in ultima analisi il panorama tecnologico.
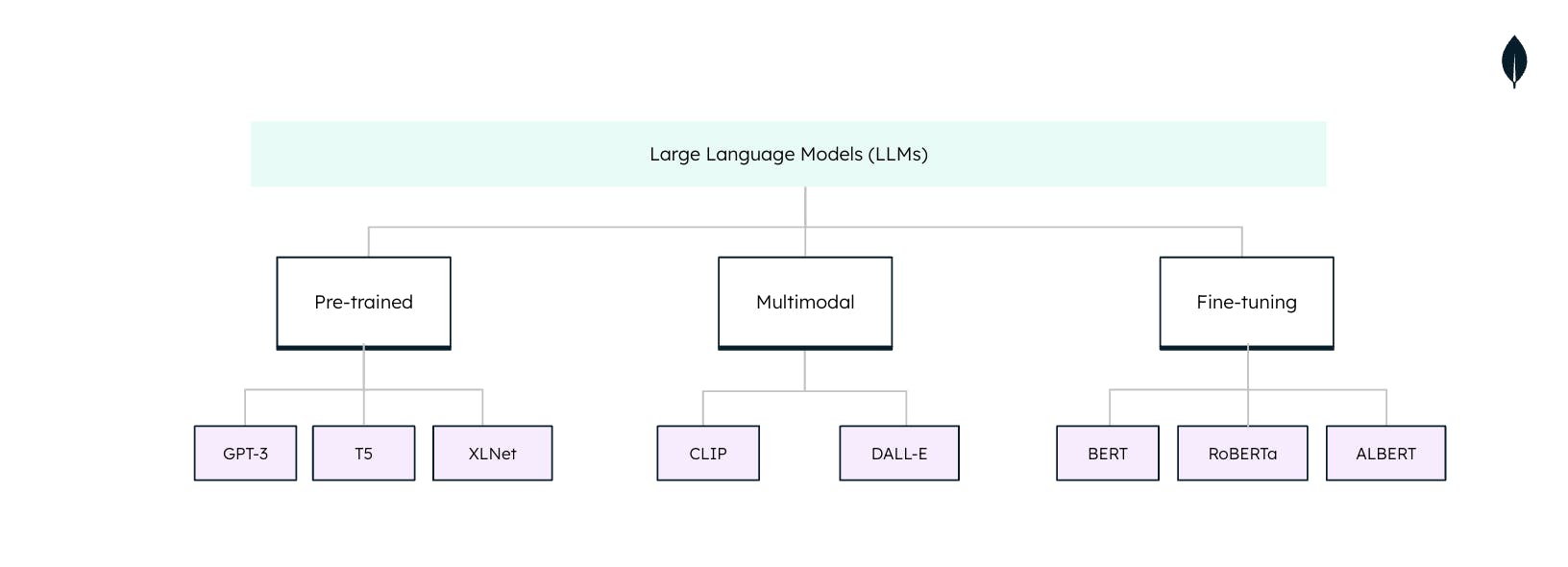
Tipi di modelli linguistici di grandi dimensioni
Non tutti i modelli linguistici di grandi dimensioni (LLM) sono adatti quando vengono utilizzati per attività di elaborazione del linguaggio naturale (NLP). Ciascun LLM è personalizzato per compiti e applicazioni specifiche. La comprensione di queste tipologie è essenziale per sfruttare appieno il potenziale degli LLM: