SNCF CONNECT AND TECH: MIGRATION ORACLE VERS MONGODB DE LA BASE COMMANDE SNCF CONNECT

SNCF Connect est le service tout-en-un des mobilités durables, conçu et développé par SNCF Connect & Tech, qui permet de gérer ses déplacements de bout en bout en proposant aux voyageurs de rechercher leurs itinéraires, retrouver leurs titres et billets de transport (train, bus, transports en commun) ainsi que les infos trafic sur les trains et différentes lignes de transports. L’application est dans la poche d’un Français sur trois.
Le présent projet a été initié en 2022 dans le dessein de répondre à une impérieuse nécessité d’évolutivité.
En effet, le modèle initial de la base en forme normale classique, s’avérait inapte à intégrer de nouvelles fonctionnalités métier, entravant ainsi la capacité d’adaptation de l’application.
De surcroît, la complexité de maintenance induite par la distribution du fonctionnel, pour des raisons de performance, entre le code applicatif et procédures stockées, constituait un sérieux défi de maintenabilité et d’évolutivité, même pour des administrateurs de bases de données expérimentés.
L’adoption du modèle document, et donc une migration profonde, s’imposèrent comme une évidence.
L’expérience accumulée au sein de la société en matière d’utilisation de MongoDB depuis 2014, avec l’avènement du premier projet intégrant MongoDB Atlas en 2019, a permis d’aborder avec confiance la matérialisation de la décision stratégique d’une migration de la base de commandes vers MongoDB Atlas.
La migration de la base au cœur d’un système aussi sensible - d’une importance critique - a nécessité une série de mesures techniques prévoyant notamment la reprise de l’historique des données depuis l’ancienne base vers MongoDB.
Concernant les performances, une série de tests techniques a été planifiée à chaque étape du projet, mettant l’accent sur la robustesse des API, la fiabilité du processus en batch, ainsi que l’exploitabilité de la base MongoDB.
Cet article a pour but de faire d’en partager les clés de réussite.
Quelle criticité pour la base commande ?
La criticité de cette base porte sur son contenu et l’activité cliente.
L’activité cliente représente 190M de billets vendus en 2022, 209M en 2024 avec plus de 550 000 billets vendus chaque jour.
Pour l’application, être performante c’est pouvoir absorber les différentes ouvertures des ventes.
L’ODV de Noël (oct. 2023) est le plus gros temps fort commercial de l’année sur SNCF Connect, les Français sont toujours au rendez-vous car c’est l’occasion de préparer les vacances et déplacements de fin d’année pour eux en bénéficiant d’un large choix d’horaires et des meilleurs prix, sans compter les nouvelles destinations que nous ouvrons pour satisfaire le plus grand nombre. Nous avons atteint jusqu’à 1 million de connexions par minute (nous étions déjà à 300 000 connexions par minute l’année dernière au pic).
La récente ODV Printemps (24 janvier 2024) étant juste derrière l’ODV Noël avec plus d’1,3M de billets vendus (+29% vs 2022) en une seule journée et des audiences en forte hausse. Pour l’ODV Hiver (14 novembre 2023), 1 million de billets a été vendu en une seule journée.
Quelles étapes pour le projet de migration ?
La conception a permis de partager les exigences techniques (RTO & RPO, purge, backup en continu ...), sécurité, le contenu du modèle de documents et d’échanger sur les choix techniques pour la reprise de données avec MongoDB.
Il y a eu quatre étapes principales d’implémentation en production :
- Oracle primaire / MongoDB secondaire en écriture
- Oracle primaire / MongoDB secondaire en lecture et écriture
- MongoDB Primaire / Oracle Secondaire
- MongoDB Solo
Elles ont été précédées par l’implémentation de la reprise de l’historique.
Comment la reprise d’historique Oracle a-t-elle été implémentée ?
Pour rattraper les 130 millions de commandes depuis l’ancienne base vers MongoDB, un processus asynchrone progressivement enrichi a été élaboré dans ce dessein, assurant une exécution régulée, un suivi en temps réel via la solution Instana, ainsi que la possibilité de reprise en cas d'interruption.
L’architecture mise en place, développée en Kotlin et reposant sur une base de données H2, a intégré des mécanismes de Throttling via la bibliothèque Resilience4j. Ces choix nous ont permis de garantir une qualité de service optimale en régulant les flux de données entre l’ancienne base et MongoDB, tout en adaptant dynamiquement les capacités de traitement selon les fluctuations de charge et de contenir fortement notamment les effets de bord.
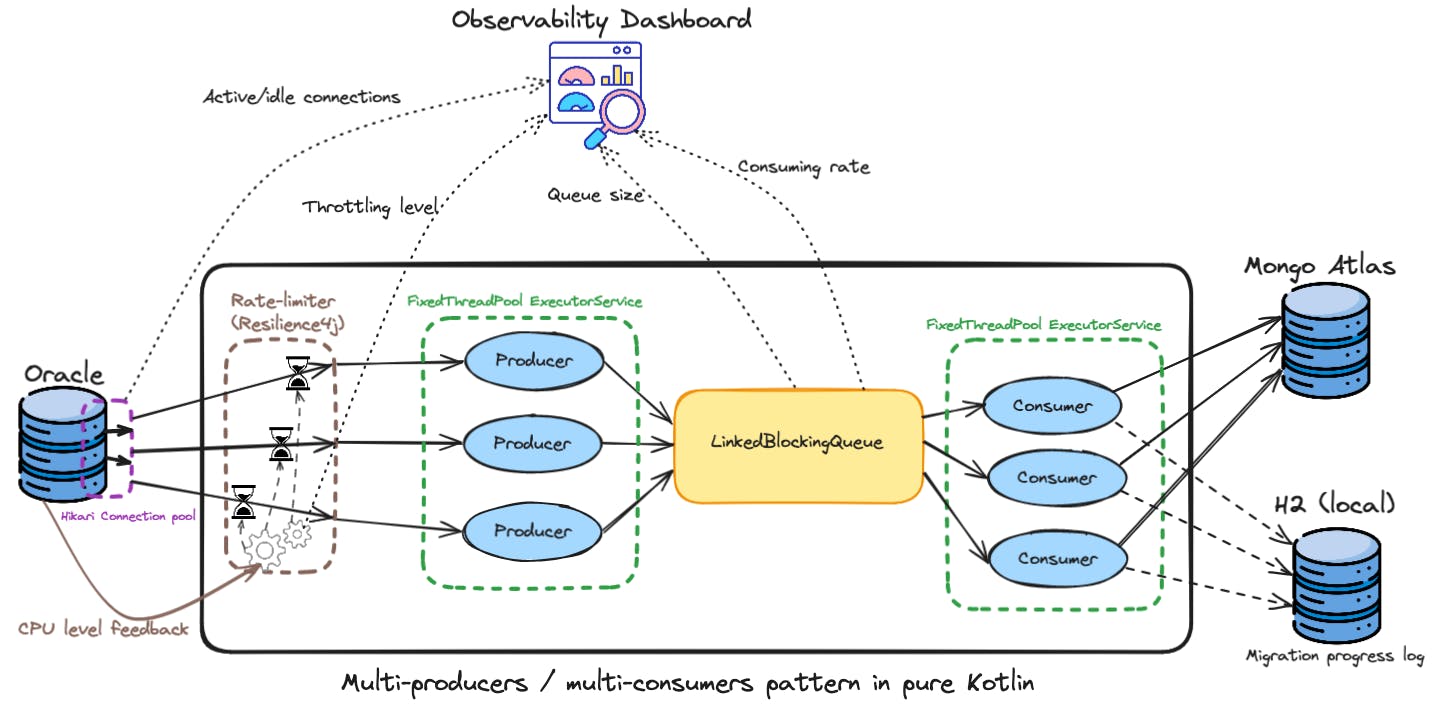
Pour garantir la qualité de service (QoS), il :
- S’exécutait sur une infrastructure dédiée
- Limitait les lectures de commande par seconde dans Oracle en utilisant un point d’entrée capé
- Limitait les écritures par seconde dans MongoDB en mode bulk de 1000 commandes
- S’autorégulait suivant la consommation CPU du cluster Oracle.
Ces limitations se faisaient en définissant :
- Le nombre de threads de lecture sur Oracle
- Le nombre de threads d’écriture sur MongoDB
- La taille de la file de commandes entre les threads de lecture et ceux d’écriture. Il s’agissait de définir la taille qui ne bloque pas la lecture et ne prend pas trop de mémoire RAM du batch.
- Le seuil de la consommation CPU Oracle à surveiller.
Il y avait deux modes pour la migration des données vers MongoDB Atlas.
Le mode reprise d’historique complet prenait 18,5 heures.
L’ultime rattrapage des modifications de commande depuis les dernières 48h, avant la bascule finale a pris 30 minutes sans activité cliente (page de maintenance sur le site).
Comment les performances ont-elles été vérifiées ?
Une série de tests techniques a été planifiée à chaque étape du projet, mettant l’accent sur la robustesse des API, la fiabilité du processus en batch, ainsi que l’exploitabilité de la base MongoDB.
Ces tests nous ont d’ailleurs confortés dans le choix de MongoDB qui n’a jamais été́ pris en défaut.
Ils ont permis de vérifier que les performances étaient là à chaque étape.
Par exemple, les tests ont permis de vérifier que l’écriture MongoDB était négligeable (en temps) pour la latence des API métiers et d’être défensif dans la configuration cliente en cas de problème (timeout ...), avant d’activer le mode synchrone (écriture Oracle puis écriture MongoDB) en production.


Quels index sur MongoDB pour les performances ?
L’optimisation des performances de la base MongoDB a reposé́ tout d’abord dans le respect des guides d’implémentation, mais aussi tout particulièrement sur une stratégie rigoureuse et systématique de gestion des index. Ces derniers, divisés en deux catégories (techniques et métiers), ont été minutieusement conçus et testés pour répondre aux besoins spécifiques de l’application, tout en minimisant l’impact sur les opérations en écriture.
Comme toujours, le travail sur la gestion des index a été orchestré de manière itérative, alignée sur les évolutions du code et des besoins métiers. La création d’une base de données iso-production, anonymisée, permettant d’effectuer des tests réalistes et de valider les choix d’indexation, est un prérequis indispensable au succès de tels projets.
Grâce à MongoDB, l’utilisation d’index permet non seulement d’optimiser les temps de réponse des requêtes de lecture telles que « db.collection.find() » ou la phase « $match » d’une agrégation, mais également d’améliorer la vitesse des mises à jour sélectives, comme dans le cas de l’instruction « db.collection.updateMany() ». En effet, certaines opérations plus complexes, telles que les agrégations prenant plus d’une seconde, ne sont tolérées qu’au niveau d’un nœud réplica spécifique.
Cela s’explique notamment par le fait qu’un balayage complet de la collection (COLSCAN) peut durer jusqu’à deux heures en raison de la taille conséquente de cette dernière.
Les index dégradent légèrement les performances des requêtes en écriture, à cause de la mise à jour de l’index à faire en plus. Cependant, c’est généralement imperceptible en conditions normales d’utilisation.
Toutefois, dans le cadre d’opérations particulières, telles qu’un import massif de données, il est possible de constater un allongement sensible des temps de traitement.
Du côté des index techniques (41,6Go) figurent :
- Les Identifiants des entités (dont certaines imbriquées en sous-documents)
- La date de la commande
Ils servent principalement à structurer et organiser les collections selon des critères internes à la plateforme. L’un d’eux (~5Go) est un index TTL qui sert pour la purge.
Les requêtes applicatives ne ramènent qu’une ou deux commandes en moyenne. Nous avons déterminé qu’il serait plus efficace d’effectuer les tris de commandes in-memory (en Java) plutôt que par un index sur la date de commande. Cependant nous en avons tout de même créé un afin de faciliter le débogage et la résolution ciblées d'anomalies.
Du côté des index métier (33,4Go), plusieurs scénarios d’utilisation méritent d’être soulignés :
- Le cas connu par tous nos clients, afin de retrouver les billets par n° de dossier et nom de commanditaire ()
- Plusieurs index pour avoir des critères de recherche étendus nécessaires au support client
- Un index pour un batch
Il y a donc de nombreux index composés, incluant même des champs de type tableau. L’inclusion de la variable « Locale » dans ces structures permet de discerner facilement si une commande appartient à la base de données française ou européenne, assurant ainsi une segmentation claire entre ces deux sous-ensembles distincts.
Le besoin métier principal consiste à fournir une recherche efficiente par identifiants dossier et nom du commanditaire.
Afin de permettre à la relation clients de rechercher les commandes sur d’autres critères, il a fallu créer d’autres index, assez nombreux. C’est une fonctionnalité́ qui a un impact important en taille d’index (45% de la taille totale des index).
La collation Unicode a été un souci particulier :
- Lorsque des index ont la collation activée, les requêtes doivent absolument l’avoir aussi. À cause de ça, et afin de simplifier le code de requêtage, il a été décidé que toutes les requêtes utilisées par le support auraient la collation Unicode. Ceci nous a obligé à activer la collation sur des index qui n’en avaient pas besoin afin d’éviter de complexifier le code qui construisait dynamiquement la requête.
- Les regex ne suivent pas les mêmes règles. Les requêtes du type « préfixe du champ X de type string » obligent une requête avec l’opérateur $regex. Mais l’option « ignoreCase » ne permet pas de faire aussi bien que la collation Unicode. Il a donc été décidé de créer des copies des champs qui devaient supporter la recherche par expression régulière. Par exemple, le champ « nom du commanditaire » existe en version indexée avec collation Unicode, et en version « all upper-case » sans collation pour permettre une recherche avec $regex sans tenir compte de la casse.
Comment a été conçue la purge ?
Un index TTL a été positionné sur le champ « Date de Dernière Modification » des Commandes, afin qu’elles soient automatiquement purgées après le TTL.
Un trigger sur les évènements delete de ces mêmes collections capte les Commandes purgées et lance une Atlas Function (Javascript) pour les entrées associées.
Comment la bascule a été prévue techniquement ?
Avec cette criticité et volumétrie d’activité un « rollback » en cas d’urgence a été implémenté.
Il s’agissait d’avoir les informations en cas de problème lors de la bascule sur MongoDB primaire.
Une collection faisait le mapping entre les identifiants Oracle (séquence historique) et les identifiants MongoDB (UUID).
En cas de rollback, il est en effet nécessaire de traduire les identifiants des documents créés dans MongoDB afin que leur copie Oracle soit retrouvée.
Point d’attention particulier, même les id de sous-documents devaient être mappés car ils sont représentés par des tables spécifiques sous Oracle.
Quelles phases de sécurisation supplémentaires ?
Une des clés de succès a été de compléter l’équipe de delivery par des interlocuteurs du support, de la fraude et de la relation clients.
Pendant la phase de double run (Oracle primaire / MongoDB secondaire), ce dispositif couplé à un outil d’analyse de « diff » a permis de classifier les différences de contenu entre Oracle et MongoDB, générées par l’activité cliente.
Cet outil a permis de suivre l’évolution journalière des écarts Oracle / MongoDB selon leur typologie ainsi que l’impact des correctifs sur leur volumétrie.
Il a permis d’accélérer l’analyse impact et correctif associé le cas échéant.
Cela a été un indicateur de suivi pour donner le Go pour la bascule (MongoDB primaire) des clients qui a été sans impact.
Qu’est qu’un diff ?
Un « diff » désigne la modélisation d’un écart entre l’objet Java persisté par la couche de persistance de MongoDB et celle d’Oracle. Les diffs sont persistées dans une collection MongoDB spécifique.
Ils contiennent un document JSON Patch (RFC 6902), ainsi que les données pour relier le cas technique à un use case métier (création de commande, opération d’après-vente, etc.)
Pour illustrer, un des cas découverts dans les diffs, puis corrigé, portait sur la différence de casse sur le nom du commanditaire.
Ceci est géré de deux manières dans MongoDB.
Premièrement une collation de force 1 (ignore la casse et les diacritiques) est spécifiée sur les indexes incluant le nom, ainsi que dans les requêtes l’incluant.
Cela a permis de conserver la casse spécifiée par le client tout en assurant les recherches ignorant la casse et les accents.
Afin d’assurer les recherches préfixe du nom, il a fallu créer une copie du champ nom.
Les expressions régulières ont leur propre option pour ignorer la casse qui n’est pas compatible avec la collation Unicode.
Les recherches préfixes ont donc été implémentées sur un champ « nom en majuscule sans accents », indexé sans collation, au moyen de l’opérateur $regex.
Notre projet de migration de la base de commandes a été un franc succès, témoignant de l’engagement et de l’expertise des équipes impliquées. Grâce à une planification minutieuse, une équipe pluridisciplinaire, une collaboration avec les experts MongoDB, et une vigilance constante quant aux performances et à la sécurité, les équipes SNCF Connect & Tech ont pu garantir et offrir une transition transparente et une continuité de service sans faille pour l’ensemble des utilisateurs de SNCF Connect.
Nous exprimons nos sincères remerciements à toutes les personnes ayant contribué à la réussite de ce projet, tant du côté du développement, des DBAs, du support, de la fraude et de la relation clients.