Comment fonctionnent les bases de données vectorielles ?
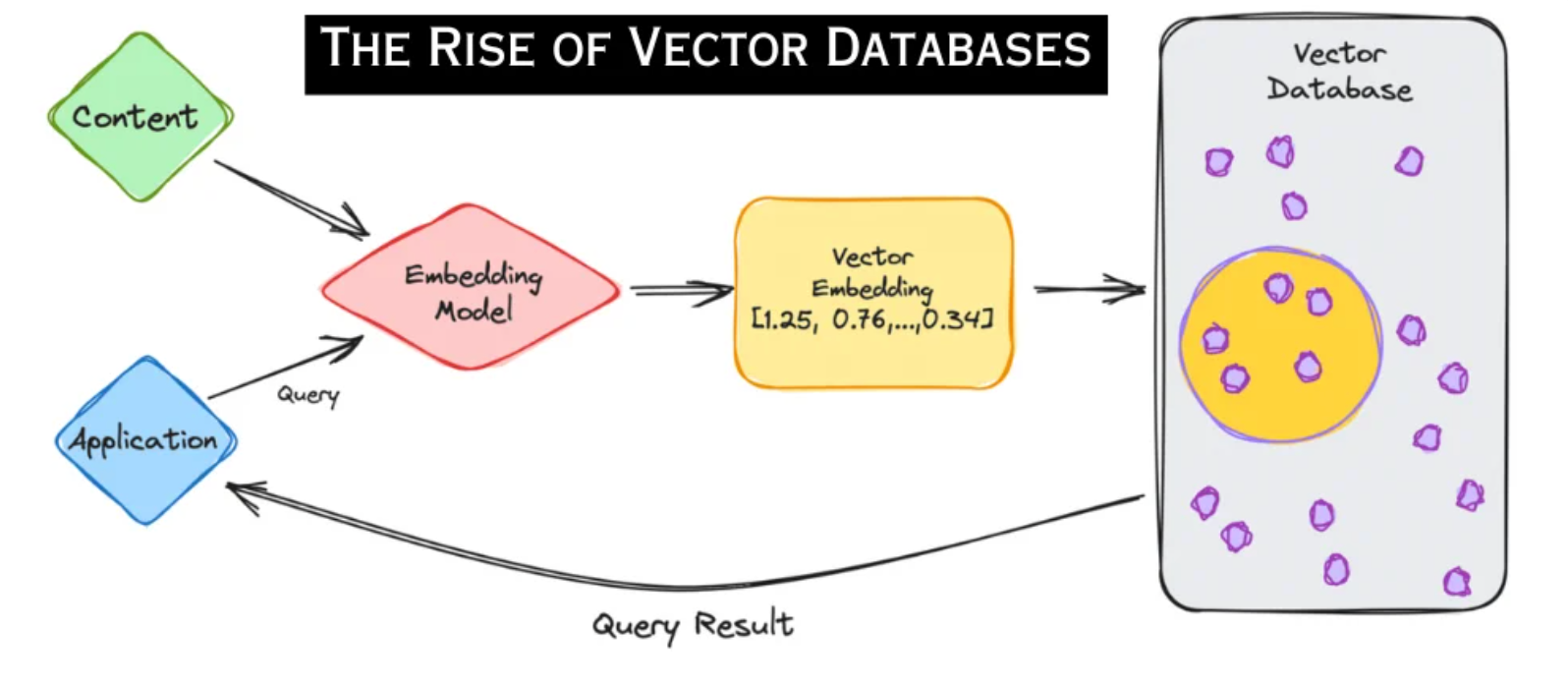
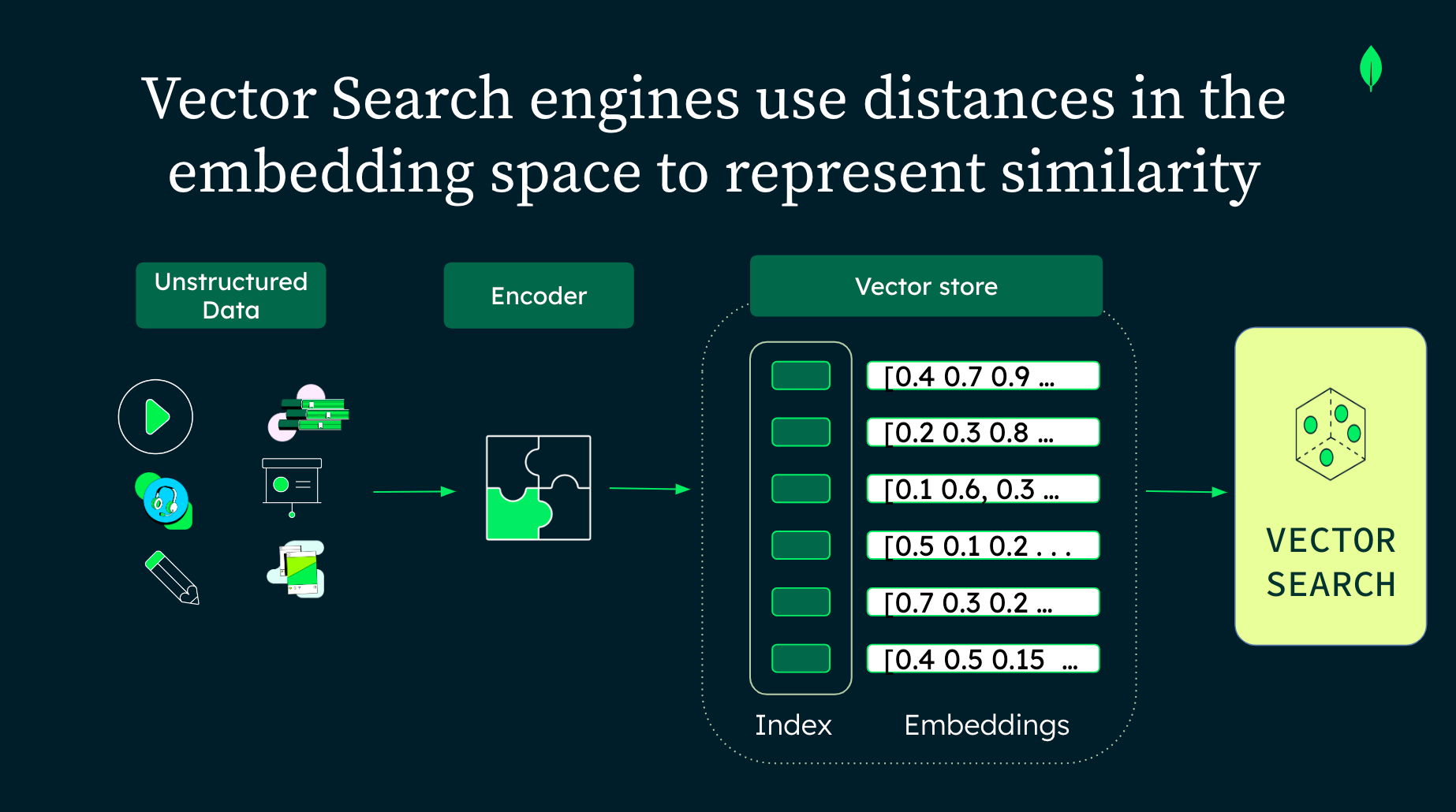
Le principe des embeddings est au cœur de la fonctionnalité d’une base de données vectorielle. Essentiellement, un modèle vectoriel ou d’embedding traduit les données dans un format cohérent : des vecteurs.
Alors qu’un vecteur est fondamentalement un ensemble ordonné de nombres, un embedding le transforme en une représentation de divers types de données, notamment du texte, des images et de l’audio.
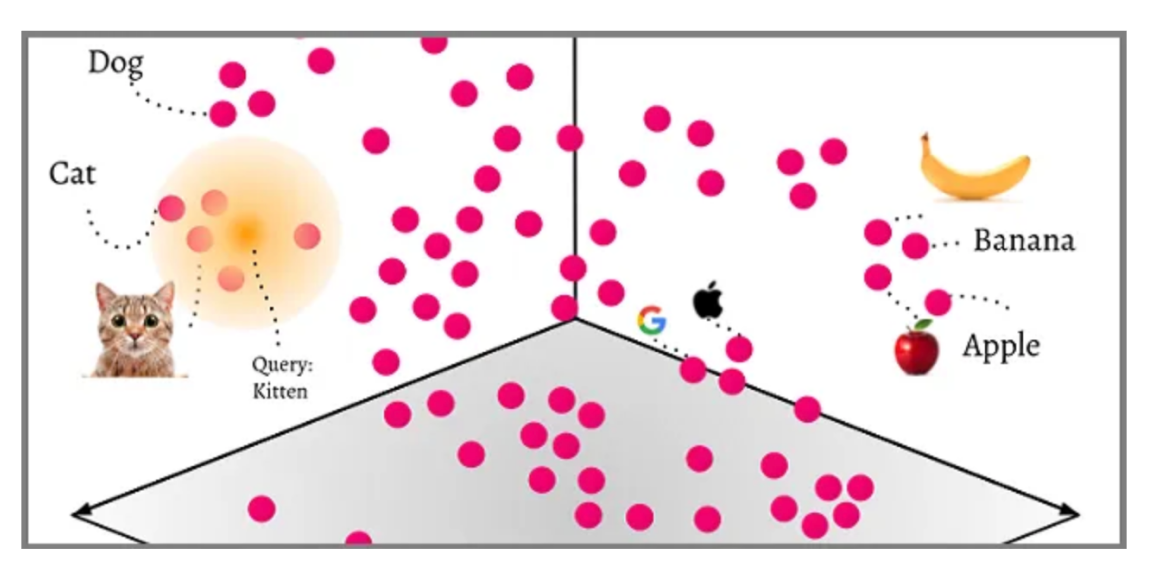
Les transformations – le processus de conversion des données d’un format à un autre – situent les vecteurs dans un espace vectoriel multidimensionnel. L’une des caractéristiques les plus frappantes de cette disposition spatiale est que les points de données ayant des attributs ou des caractéristiques similaires gravitent naturellement les uns vers les autres, formant des clusters.
Les embeddings vectoriels ne sont pas de simples traductions numériques ; ils encapsulent l’essence sémantique profonde et les nuances contextuelles des données d’origine. Ce sont donc des atouts inestimables pour une gamme d’applications d’IA – du traitement du langage naturel (NLP) à l’analyse des sentiments et à la catégorisation de texte.
L’interrogation d’une base de données vectorielle diffère de celle d’une base de données conventionnelle. Au lieu de rechercher des correspondances précises entre des vecteurs identiques, une base de données vectorielle utilise la recherche de similarité pour identifier les vecteurs qui se trouvent à proximité du vecteur de requête donné, dans l’espace multidimensionnel. Cette approche non seulement s’aligne plus étroitement sur la nature inhérente des données, mais elle offre également une vitesse et une efficacité que la recherche traditionnelle ne peut égaler.
Des mots, des phrases et même des documents entiers peuvent être transformés en vecteurs qui capturent leur essence. Prenons l’exemple de Word2Vec, une méthode standard de word embedding (plongement lexical). Avec Word2Vec, les mots ayant des significations similaires sont représentés par des vecteurs proches dans un espace multidimensionnel. L’exemple le plus connu est « roi - homme + femme = reine ». L’addition des vecteurs associés aux mots « roi » et « femme », tout en soustrayant « homme », équivaut au vecteur associé à « reine ».
Même avec leurs motifs et couleurs complexes, les images peuvent être converties en vecteurs. Par exemple, dans un ensemble de données rempli d’images d’animaux, un réseau neuronal convolutif (CNN) entraîné regrouperait toutes les images de chiens à proximité les unes des autres, en les distinguant nettement des groupes de chats ou d’oiseaux.
En capturant la structure de données inhérente et les schémas au sein des données, les embeddings vectoriels offrent des représentations enrichies sur le plan sémantique. Cette richesse ne facilite pas seulement une compréhension plus approfondie des données, mais accélère également les calculs liés à la détermination des relations et à l’évaluation des similarités entre différentes entités.
Pourquoi la recherche vectorielle est-elle cruciale ?
La recherche vectorielle est essentielle pour les bases de données vectorielles en raison de sa méthode particulière de récupération des données.
Contrairement aux bases de données classiques qui reposent sur des correspondances exactes, dans une base de données vectorielle, la recherche vectorielle fonctionne sur la base de la similarité. Cette compréhension sémantique signifie que même si deux ensembles de données ne sont pas identiques mais similaires sur le plan contextuel ou sémantique, ils peuvent être mis en correspondance.
Les recherches par mot-clé traditionnelles excellent lorsqu’il s’agit de repérer des termes spécifiques dans des documents ou des tables. Cependant, elles ne parviennent pas à traiter les données non structurées, telles que les vidéos, les livres, les publications sur les réseaux sociaux, les fichiers PDF et les fichiers audio.
La recherche vectorielle comble cette lacune en permettant des recherches dans des données non structurées. En plus de la recherche des correspondances exactes, elle identifie le contenu en fonction de la similarité sémantique, en comprenant les relations inhérentes entre les termes de recherche.
L’efficacité de la recherche vectorielle est manifeste lorsqu’on a affaire à des données à haute dimension. Les bases de données vectorielles sont capables de traiter des points de données couvrant des centaines, voire des milliers de dimensions. Les algorithmes optimisés pour la recherche vectorielle de vecteurs à haute dimension, tels que la recherche approximative du plus proche voisin (ANN), peuvent rapidement identifier les vecteurs les plus similaires dans cet espace vaste sans qu’il soit nécessaire d’analyser chaque vecteur. Cette efficacité se traduit par des recherches plus rapides et plus efficaces en termes de ressources.
Du point de vue de l’expérience utilisateur, les avantages de la recherche vectorielle sont nombreux. Des applications telles que les systèmes de recommandations ou la reconnaissance d’images peuvent fournir des résultats basés sur la similarité plutôt que sur des correspondances exactes. Par exemple, dans un contexte de e-commerce, afficher des produits similaires à la requête de recherche d’un utilisateur peut améliorer la satisfaction client et augmenter les ventes. À mesure que les ensembles de données s’étendent, l’évolutivité de la recherche vectorielle devient manifeste. Alors que les recherches de correspondances exactes peuvent ralentir progressivement avec la croissance des données, la recherche vectorielle maintient des performances de requête cohérentes tout au long du processus, garantissant des résultats rapides même avec de vastes ensembles de données.
La flexibilité offerte par la recherche vectorielle est un autre avantage notable. Elle s’adapte aux nouveaux types de données, aux structures de données évolutives et aux exigences de recherche changeantes avec un minimum d’ajustements.
De plus, sa flexibilité est inestimable dans le contexte de la gestion des données en évolution rapide, d’autant que de nombreux modèles d’IA et de machine learning actuels, en particulier ceux basés sur l’apprentissage profond, produisent des données sous forme vectorielle. Une base de données capable de rechercher de manière native dans des données vectorielles devient indispensable pour des applications avancées telles que la reconnaissance faciale ou vocale.
Cas d’utilisation des bases de données vectorielles
Le paysage économique mondial est complexe et concurrentiel, et les données restent un enjeu majeur. Elles étaient autrefois qualifiées de « nouveau pétrole ». À l’ère de l’IA générative, les embeddings vectoriels sont le pétrole et les bases de données vectorielles sont devenues des raffineries sophistiquées, capables de traiter des données à haute dimension et d’exécuter des recherches de similarité.
Pour les cadres dirigeants, l’IA générative n’est pas seulement un mot à la mode ; c’est une stratégie. Pour les développeurs, l’attrait principal des bases de données vectorielles est l’efficacité. Les bases de données traditionnelles peuvent nécessiter des structures de requête complexes pour obtenir des données pertinentes, surtout lorsqu’il s’agit de vastes ensembles de données. Les bases de données vectorielles simplifient ce processus, permettant aux développeurs de récupérer des données en fonction de leur similarité, réduisant ainsi à la fois la complexité du code et le temps nécessaire à la récupération des données.
Quelques exemples de cas d’utilisation de bases de données vectorielles
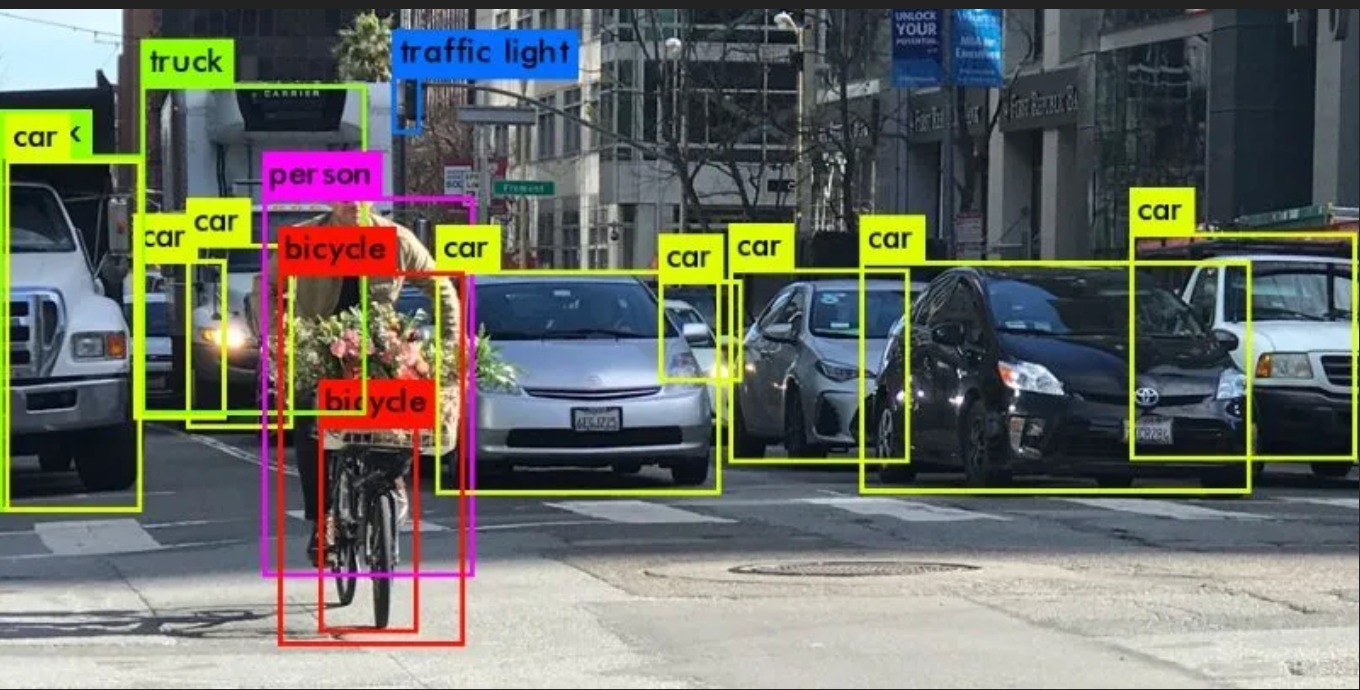
Reconnaissance d’images et de vidéos : les contenus visuels dominent notre culture visuelle, et les bases de données vectorielles y excellent. Elles sont capables de passer au crible de vastes référentiels d’images et de vidéos pour repérer celles qui présentent une ressemblance frappante avec une entrée donnée. Il ne s’agit pas seulement d’effectuer une mise en correspondance pixel par pixel, mais de comprendre les schémas et les caractéristiques sous-jacents. Ces capacités sont cruciales pour des applications comme la reconnaissance faciale, la détection d’objets et même la détection de violations de droits d’auteur sur les plateformes multimédias.
Traitement du langage naturel et recherche textuelle : les synonymes, les reformulations et le contexte peuvent considérablement compliquer la recherche de correspondances exactes de texte. Toutefois, les bases de données vectorielles sont capables de discerner l’essence sémantique des expressions ou des phrases, ce qui leur permet d’identifier des correspondances dont la formulation n’est pas identiques, mais qui sont similaires sur le plan contextuel. Cette prouesse change la donne pour les chatbots qui peuvent alors répondre de manière appropriée aux requêtes des utilisateurs. De même, les moteurs de recherche peuvent fournir des résultats plus pertinents, améliorant ainsi l’expérience utilisateur.
Systèmes de recommandations : les bases de données vectorielles jouent un rôle central dans la personnalisation. En comprenant les préférences des utilisateurs et en analysant les schémas, ces bases de données peuvent suggérer des chansons qui correspondent aux goûts d’un auditeur ou des produits qui s’alignent sur les préférences d’un acheteur. L’objectif est d’évaluer la similarité et de fournir du contenu ou des produits susceptibles de séduire l’utilisateur.
Applications émergentes : l’horizon des bases de données vectorielles ne cesse de s’élargir. Dans le secteur de la santé, elles aident à la découverte de médicaments en analysant les structures moléculaires pour identifier des propriétés thérapeutiques potentielles. Dans le secteur financier, elles contribuent à la détection des anomalies en repérant des schémas inhabituels pouvant indiquer des activités frauduleuses.
Avec l’essor de l’IA générative, les bases de données vectorielles apparaissent comme des outils incontournables, aidant les développeurs à transformer des plans d’IA complexes en outils pratiques et axés sur la valeur.
MongoDB Atlas Vector Search : une avancée majeure
MongoDB Atlas Vector Search est la dernière nouveauté de MongoDB. La solution permet aux clients de créer des applications intelligentes optimisées par la recherche sémantique et l’IA générative, quel que soit le type de données. Consultez le guide de démarrage rapide Atlas Vector Search et créez votre premier index en quelques minutes.
Historiquement, les équipes de développement à la recherche d’une base de données vectorielle pour des tâches comme la recherche d’images ou de similarités efficaces étaient confrontées à un dilemme : opter pour une base de données vectorielle complémentaire, ajouter un autre outil à la pile technologique ou jongler avec différents outils de recherche et de solutions open source. L’utilisation d’une recherche en texte intégral pour les capacités sémantiques conduisait souvent les développeurs à s’enliser dans un mappage infini de synonymes. Les limites étaient claires : si les requêtes utilisateur manquaient de précision, les résultats étaient loin d’être pertinents.
De tels défis signifiaient :
- Un système supplémentaire à superviser
- Le besoin de compétences spécialisées
- La charge mentale liée aux mises à jour constantes des mappages de synonymes
- Une expérience utilisateur médiocre lors de requêtes imprécises
- Du temps précieux d’ingénierie détourné des tâches essentielles
Atlas Vector Search simplifie la conception d’applications enrichies par la recherche sémantique et l’IA générative, capables de traiter un large éventail de types de données, allant des vidéos aux contenus des réseaux sociaux. En exploitant la robustesse de MongoDB Atlas, Vector Search permet aux développeurs de concevoir des outils de recherche de pointe basés sur la pertinence, sur une plateforme fiable dotée d’une interface de requête unifiée.
Vector Search fournit à MongoDB Atlas les connaissances nécessaires pour comprendre une requête sans avoir besoin de définir des synonymes. Même lorsque les utilisateurs ne savent pas ce qu’ils recherchent, Vector Search est capable de fournir des résultats pertinents basés sur la signification de la requête. Par exemple, une recherche sur « ice cream » renverra « sundae », même si l’utilisateur ignore que les sundaes existent.
Lorsque vous utilisez Vector Search, vous stockez des embeddings vectoriels à côté des données et métadonnées d’origine dans Atlas. Ainsi, toutes les mises à jour ou tous les ajouts apportés à vos données vectorielles sont instantanément synchronisés, ce qui rationalise l’architecture et offre une expérience unifiée aux développeurs.
Avec Vector Search, vous allez indexer et interroger des données en utilisant l’un des algorithmes de recherche vectorielle les plus puissants : la recherche des k plus proches voisins (ou « k-NN », qui utilise des graphiques hiérarchiques navigables du petit monde, ou HNSW, pour trouver la similarité des vecteurs).
Vous pouvez créer des expériences de recherche considérablement améliorées qui répondent à des cas d'utilisation que les outils de recherche traditionnels ne peuvent pas traiter, notamment :
- Recherche sémantique : permet d’effectuer des recherches basées sur le contexte. Par exemple, une recherche sur « ice cream » peut renvoyer des résultats tels que « sundae » sans aucun synonyme prédéfini.
- Recommandations améliorées : si un utilisateur recherche une tondeuse à gazon, le système peut également suggérer des articles liés à l’entretien de la pelouse.
- Recherches multimédias variées : qu’il s’agisse de rechercher des images correspondant à des termes comme « bonheur en famille » ou de parcourir des journaux audio à la recherche de phrases spécifiques, Vector Search est à la hauteur de la tâche.
- Recherche hybride : cette méthode combine les points forts de la recherche vectorielle avec la recherche traditionnelle en texte intégral, enrichissant ainsi les résultats.
- Mémoire à long terme pour les grands modèles de langage : fournit un contexte de données métier propriétaire aux LLM, ce qui permet d’affiner la précision de leur sortie.
Atlas Vector Search est compatible avec des frameworks d’application populaires tels que LlamaIndex et LangChain. Il s’intègre également de manière transparente aux partenaires de l’écosystème tels que Google Vertex AI, AWS, Azure et Databricks, garantissant que les données métier propriétaires améliorent les performances et la précision des applications alimentées par l’IA.
Atlas Vector Search : pour des applications intelligentes basées sur la recherche sémantique
Les bases de données vectorielles, avec leur approche unique du stockage et de la récupération des données, changent notre façon de penser les bases de données. Leur capacité à effectuer des recherches de similarité rapides les rend indispensables dans le monde d’aujourd’hui axé sur les données. Combinées à la puissance et à la flexibilité de MongoDB Atlas, elles offrent une solution difficile à égaler.
Atlas Vector Search permet de gérer des cas d’utilisation avancés, tels que la recherche sémantique, la recherche d’images et la recherche de similarité, qui ne peuvent pas être traités par la recherche en texte intégral classique. Les développeurs peuvent stocker leurs embeddings vectoriels dans MongoDB, compléter leur fonctionnalité de recherche existante avec des modèles de machine learning et les interroger pour obtenir des résultats contextuels pertinents. Les responsables de l’ingénierie bénéficient de la tranquillité d’esprit que procure l’utilisation d’Atlas : une base de données moderne et multicloud entièrement gérée.
Que vous développiez un système de recommandations, un moteur de recherche ou toute autre application nécessitant une mise en correspondance rapide et précise des données, tirez parti de la puissance combinée des bases de données vectorielles et de MongoDB. L’avenir est vectorisé, et MongoDB est là pour vous aider à y prendre pied.