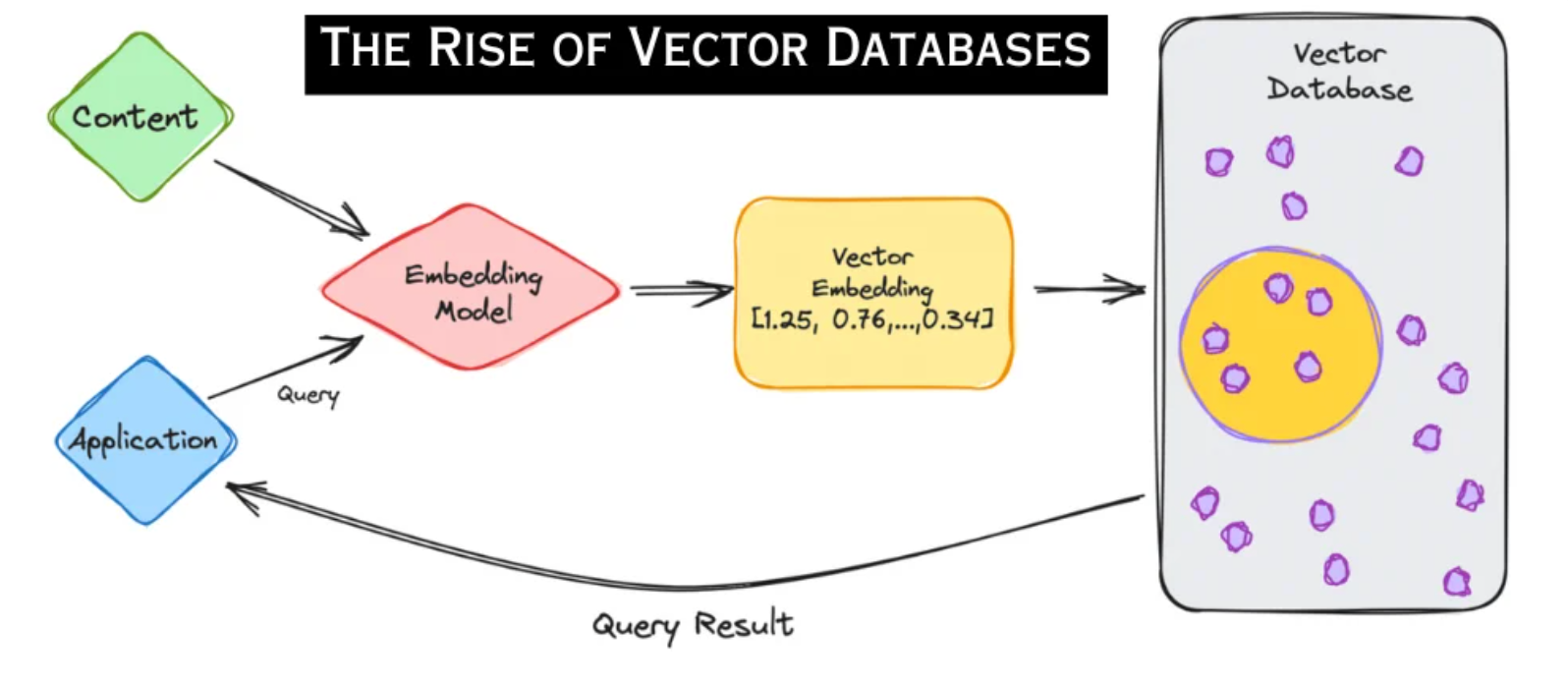
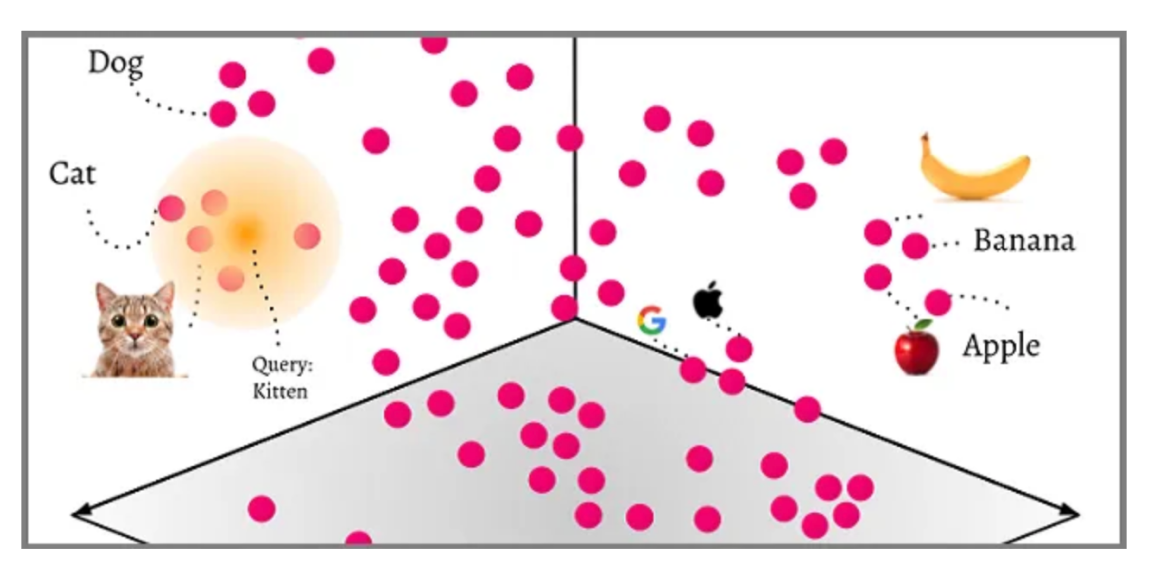
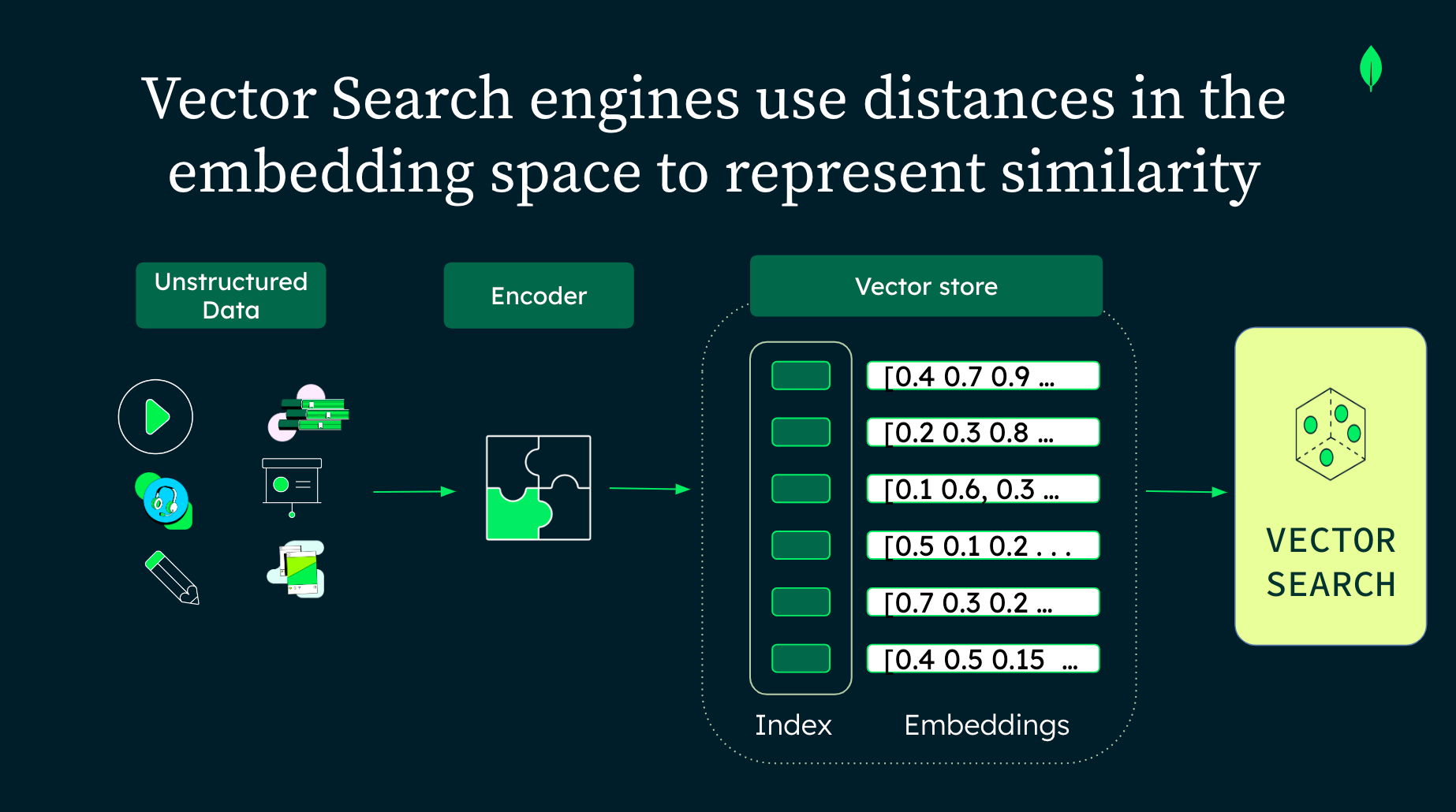
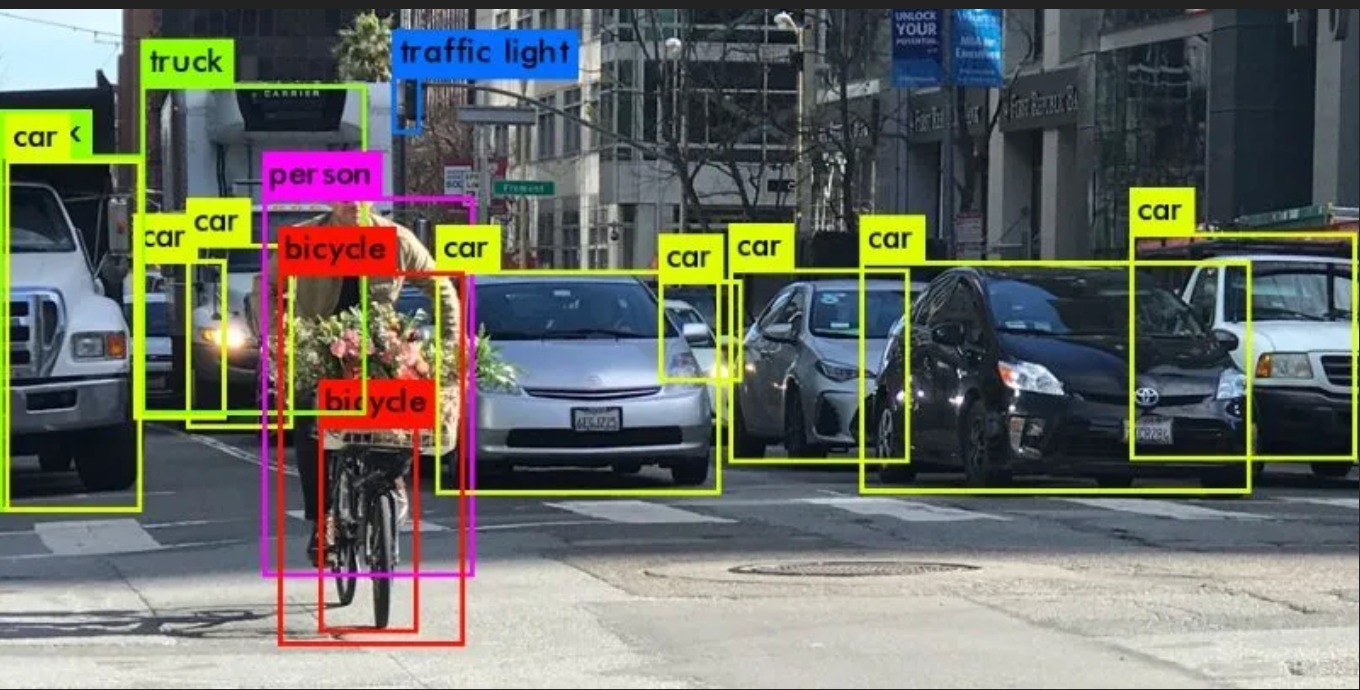
¿Cómo funcionan las bases de datos vectoriales?
La funcionalidad central de una base de datos vectorial es el principio de las incrustaciones. En esencia, un modelo vectorial o de incrustación traduce los datos a un formato coherente: vectores.
Si bien un vector es fundamentalmente un conjunto ordenado de números, una incrustación lo transforma en una representación de varios tipos de datos, incluidos texto, imágenes y audio.
Las transformaciones, el proceso de conversión de datos de un formato a otro, sitúan los vectores en un espacio vectorial multidimensional. Una de las características más llamativas de esta disposición espacial es que los puntos de datos con atributos o características similares gravitan naturalmente unos hacia otros, formando grupos.
Las incrustaciones vectoriales no son solo traducciones numéricas; encapsulan la esencia semántica más profunda y los matices contextuales de los datos originales. Esto los convierte en activos invaluables para una variedad de aplicaciones de IA, desde el procesamiento del lenguaje natural (NLP) hasta el análisis de sentimientos y la categorización de texto.
Consultar una base de datos vectorial es diferente a consultar una base de datos convencional. En lugar de buscar coincidencias precisas entre vectores idénticos, una base de datos vectoriales utiliza búsqueda de similitud para identificar vectores que residen cerca del vector de consulta determinado, dentro del espacio multidimensional. Este enfoque no solo se alinea más estrechamente con la naturaleza inherente de los datos, sino que también ofrece una velocidad y eficiencia que la búsqueda tradicional no puede coincidir.
Palabras, oraciones e incluso documentos enteros pueden transformarse en vectores que capturan su esencia. Por ejemplo, un método estándar de incrustación de palabras es Word2Vec. Con Word2Vec, las palabras con significados similares están representadas por vectores que están cerca en un espacio multidimensional. El ejemplo más famoso es: rey – hombre + mujer = reina. Agregar los vectores asociados con las palabras "rey" y "mujer" mientras restan "hombre" es igual al vector asociado con "queen".
Incluso con sus intrincados patrones y colores, las imágenes se pueden traducir en vectores. Por ejemplo, en un conjunto de datos repleto de imágenes de animales, una red neuronal convolucional (CNN) entrenada agruparía todas las imágenes de perros cerca unas de otras, claramente separadas de, por ejemplo, grupos de gatos o pájaros.
Al capturar la estructura de datos inherente y los patrones dentro de los datos, las incrustaciones vectoriales ofrecen representaciones enriquecidas semánticamente. Esta riqueza no solo facilita una comprensión más profunda de los datos, sino que también acelera los cálculos relacionados con la determinación de relaciones y las similitudes entre diferentes entidades.
¿Por qué es fundamental la búsqueda de vectores?
La búsqueda vectorial es fundamental para las bases de datos vectoriales debido a su método de recuperación de datos distintivo.
A diferencia de las bases de datos tradicionales que dependen de coincidencias exactas, en una base de datos vectorial, la búsqueda de vectores funciona con base en la similitud. Esta comprensión semántica significa que incluso si dos datos no son idénticos, pero son contextualmente o semánticamente similares, pueden coincidir.
Las búsquedas tradicionales por palabras clave son excelentes para localizar términos específicos en documentos o tablas. Sin embargo, se quedan cortos con datos no estructurados, como videos, libros, publicaciones en redes sociales, archivos PDF y archivos de audio.
La búsqueda vectorial llena este vacío al permitir búsquedas dentro de datos no estructurados. No solo busca coincidencias exactas, sino que identifica el contenido en función de la similitud semántica, comprendiendo las relaciones inherentes entre los términos de búsqueda.
La eficiencia de la búsqueda vectorial se hace evidente cuando se trata de datos de alta dimensión. Las bases de datos vectoriales son expertas en el manejo de puntos de datos que abarcan cientos o incluso miles de dimensiones. Los algoritmos optimizados para la búsqueda vectorial de vectores de alta dimensión, como la búsqueda aproximada del vecino más cercano (ANN), pueden identificar rápidamente los vectores más similares en este vasto espacio sin necesidad de escanear cada vector. Esta eficacia se traduce en búsquedas más rápidas y eficaces.
Desde el punto de vista de la experiencia del usuario, las ventajas de la búsqueda vectorial son múltiples. Las aplicaciones como los sistemas de recomendación o el reconocimiento de imágenes pueden proporcionar resultados basados en la similitud en lugar de coincidencias exactas. Por instancia, en un entorno de comercio electrónico, mostrar productos similares a la consulta de búsqueda de un usuario puede mejorar la satisfacción del cliente y aumentar las ventas. A medida que los conjuntos de datos se expanden, la escalabilidad de la búsqueda vectorial se hace evidente. Si bien las búsquedas de coincidencias exactas pueden volverse cada vez más lentas a medida que aumentan los datos, la búsqueda vectorial mantiene un rendimiento constante de las consultas en todo momento, lo que garantiza resultados oportunos incluso con grandes conjuntos de datos.
La flexibilidad que ofrece la búsqueda vectorial es otra ventaja notable. Se adapta a nuevos tipos de datos, estructuras de datos en evolución y requisitos de búsqueda cambiantes con ajustes mínimos.
Además, la flexibilidad tiene un valor incalculable en el panorama de la gestión de datos, que evoluciona rápidamente, en especial porque muchos de los modelos actuales de AI y aprendizaje automático, en particular los que están basados en el aprendizaje profundo, producen datos en forma vectorial. Una base de datos que pueda buscar de forma nativa a través de datos vectoriales se vuelve indispensable para aplicaciones avanzadas como el reconocimiento facial o el reconocimiento de voz.
Casos de uso para bases de datos vectoriales
El panorama económico mundial es complejo y competitivo, y los datos siguen siendo su núcleo. En el pasado, muchos han llamado a los datos el "nuevo aceite". En la era de la IA generativa, las incrustaciones vectoriales son el petróleo y las bases de datos vectoriales han surgido como sofisticadas refinerías, expertas en procesar datos de alta dimensión y ejecutar búsquedas de similitudes.
Para los ejecutivos, la IA generativa no es solo una palabra de moda; es una estrategia. Para los desarrolladores, el principal atractivo de las bases de datos vectoriales es la eficiencia. Las bases de datos tradicionales pueden requerir estructuras de consulta complejas para obtener datos relevantes, especialmente cuando se trata de grandes conjuntos de datos. Las bases de datos vectoriales simplifican esta tarea, ya que permiten a los desarrolladores recuperar datos en función de su similitud, lo que reduce tanto la complejidad del código como el tiempo necesario para la recuperación de datos.
Una muestra de casos de uso de bases de datos vectoriales
Reconocimiento de imágenes y vídeos: El contenido visual domina nuestra cultura visual, y las bases de datos vectoriales brillan intensamente en él. Son expertos en escudriñar vastos repositorios de imágenes y vídeos para localizar aquellos que guardan un parecido asombroso con una entrada determinada. No se trata sólo de cotejar píxel por píxel, sino de comprender los patrones y características subyacentes. Estas capacidades son cruciales para aplicaciones como el reconocimiento facial, la detección de objetos e incluso la detección de infracciones de derechos de autor en plataformas de medios.
Procesamiento del lenguaje natural y búsqueda de texto: Los sinónimos, las paráfrasis y el contexto pueden hacer que la coincidencia exacta de textos sea una tarea desalentadora. Sin embargo, las bases de datos vectoriales pueden distinguir la esencia semántica de frases u oraciones, lo que les permite identificar coincidencias que pueden no ser idénticas en términos de redacción, pero que son contextualmente similares. Esta habilidad cambia las reglas del juego para los chatbots, ya que garantiza que respondan adecuadamente a las consultas de los usuarios. Del mismo modo, los motores de búsqueda pueden ofrecer resultados más relevantes y mejorar la experiencia del usuario.
Sistemas de recomendación: Las bases de datos vectoriales desempeñan un papel fundamental en la personalización. Al comprender las preferencias del usuario y analizar patrones, estas bases de datos pueden sugerir canciones que resuenen con el gusto o los productos de un oyente que se alinean con las preferencias de un comprador. Se trata de medir la similitud y ofrecer contenido o productos que calen hondo en el usuario.
Aplicaciones emergentes: El horizonte de las bases de datos vectoriales se está expandiendo constantemente. En el sector de salud, están contribuyendo al descubrimiento de fármacos mediante el análisis de estructuras moleculares en busca de posibles propiedades terapéuticas. En el sector financiero, las bases de datos vectoriales están ayudando en la detección de anomalías, detectando patrones inusuales que podrían indicar actividades fraudulentas.
Con el ascenso de la IA generativa, las bases de datos vectoriales emergen como facilitadores vitales, ayudando a los desarrolladores a transformar los intrincados planos de AI en herramientas prácticas y basadas en el valor.
Atlas Vector Search de MongoDB: un cambio revolucionario
MongoDB Atlas Vector Search es la última adición a MongoDB. Permite a los clientes construir aplicaciones inteligentes potenciadas por búsqueda semántica e IA generativa sobre cualquier tipo de datos. Visite la Guía de inicio rápido de Atlas Vector Search y cree su primer índice en cuestión de minutos.
Históricamente, los equipos de desarrollo que buscaban una base de datos vectorial para tareas como la búsqueda de imágenes o de similitudes eficientes se enfrentaban a un dilema: optar por una base de datos vectorial complementaria, añadiendo otra herramienta a la pila tecnológica, o hacer malabarismos con una mezcla de herramientas de búsqueda y soluciones de código abierto. El uso de una búsqueda de texto completo para las capacidades semánticas a menudo significaba que los desarrolladores se atascaban con un extenso mapeo de sinónimos. Las limitaciones eran claras: si los usuarios no eran precisos en sus consultas, los resultados estaban lejos de ser relevantes.
Tales desafíos implicaron:
- Un sistema adicional para supervisar.
- La necesidad de habilidades especializadas.
- La tensión mental de actualizar constantemente las asignaciones de sinónimos.
- Una experiencia de usuario deficiente para consultas imprecisas.
- Tiempo valioso de ingeniería que se desvió de las tareas principales.
Atlas Vector Search simplifica el diseño de aplicaciones enriquecidas por la búsqueda semántica y la IA generativa, capaces de procesar una variedad de tipos de datos, desde videos hasta contenido de redes sociales. Aprovechando la solidez de MongoDB Atlas, Vector Search permite a los desarrolladores crear herramientas de búsqueda de vanguardia basadas en la relevancia en una plataforma confiable con una interfaz de consulta unificada.
Vector Search proporciona a MongoDB Atlas los conocimientos necesarios para comprender una consulta sin necesidad de definir sinónimos. Incluso cuando los usuarios no saben lo que buscan, la búsqueda de vectores puede devolver resultados relevantes en función del significado de la consulta. Por ejemplo, una búsqueda de "helado" arrojaría "sundae", incluso si el usuario no sabía que existían los sundae.
Cuando utilice Búsqueda de vectores, almacenará incrustaciones vectoriales junto con los datos y metadatos originales en Atlas. Esto garantiza que cualquier actualización o adición a sus datos vectoriales se sincronice al instante, agilizando la arquitectura y ofreciendo una experiencia unificada al desarrollador.
Con la búsqueda vectorial, indexará y consultará datos utilizando uno de los algoritmos de búsqueda vectorial más potentes: vecinos más próximos k aproximados (o "k-NN", que utiliza grafos de mundos pequeños navegables jerárquicos, o HNSW, para encontrar similitudes vectoriales).
Puede crear experiencias de búsqueda enormemente mejoradas que aborden casos de uso que las herramientas de búsqueda tradicionales no pueden, incluyendo:
- Búsqueda semántica: Esto permite búsquedas impulsadas por el contexto. Por ejemplo, una búsqueda de "helado" podría producir resultados como "sundae" sin sinónimos preestablecidos.
- Recomendaciones mejoradas: si un usuario busca una cortadora de césped, el sistema también podría sugerir artículos relacionados con el cuidado del césped.
- Búsquedas en diversos medios: tanto si se trata de buscar imágenes que coincidan con términos como “familias felices” como de examinar registros de audio en busca de frases concretas, Vector Search está a la altura.
- Búsqueda híbrida: combina los puntos fuertes de la búsqueda vectorial con la búsqueda tradicional de texto completo, enriqueciendo los resultados.
- Memoria a largo plazo para los LLM: esto proporciona un contexto de datos empresariales propios a los grandes modelos lingüísticos, perfeccionando así la precisión de sus resultados.
Atlas Vector Search es compatible con marcos de aplicaciones populares como LlamaIndex y LangChain. También se integra a la perfección con socios del ecosistema como Google Vertex AI, AWS, Azure y Databricks, lo que garantiza que los datos empresariales patentados mejoren el rendimiento y la precisión de las aplicaciones impulsadas por IA.
Atlas Vector Search: para aplicaciones inteligentes impulsadas por búsqueda semántica
Las bases de datos vectoriales, con su enfoque único para el almacenamiento y la recuperación de datos, están cambiando la forma en que pensamos sobre las bases de datos. Su capacidad para realizar búsquedas rápidas de similitudes los hace indispensables en el mundo actual basado en datos. Y cuando se combinan con la potencia y la flexibilidad de MongoDB Atlas, ofrecen una solución difícil de superar.
Atlas Vector Search permite casos de uso avanzados, como la búsqueda semántica, la búsqueda de imágenes y la búsqueda por similitud, que no se pueden abordar con la búsqueda tradicional de texto completo. Los desarrolladores pueden almacenar sus incrustaciones vectoriales en MongoDB, complementar su funcionalidad de búsqueda existente con modelos de aprendizaje automático y consultarlos para obtener resultados relevantes y contextuales. Los líderes de ingeniería se benefician de la tranquilidad que ofrece el uso de Atlas: una base de datos multicloud moderna y totalmente gestionada.
Ya sea que esté creando un sistema de recomendación, un motor de búsqueda o cualquier otra aplicación que requiera una coincidencia de datos rápida y precisa, considere aprovechar el poder combinado de las bases de datos vectoriales y MongoDB. El futuro está vectorizado, y MongoDB está aquí para ayudarle a navegarlo.