Overview
En esta guía, puedes aprender cómo almacenar y recuperar archivos grandes en MongoDB utilizando GridFS. GridFS es una especificación que describe cómo dividir archivos en fragmentos al almacenarlos y cómo reconstruir esos archivos al recuperarlos. La implementación de GridFS del driver Ruby es una abstracción que gestiona las operaciones y la organización del almacenamiento de archivos.
Utiliza GridFS si el tamaño de los archivos supera el límite del tamaño del documento BSON de 16MB. Para obtener información más detallada sobre si GridFS es adecuado para tu caso de uso, consulta GridFS en el manual del MongoDB Server.
Las siguientes secciones describen las operaciones de GridFS y cómo realizarlas.
Cómo funciona GridFS
GridFS organiza los archivos en un bucket, un grupo de colecciones de MongoDB que contienen los fragmentos de archivos e información que los describe. El bucket contiene las siguientes colecciones, nombradas según la convención definida en la especificación GridFS:
La
chunksla colección almacena los fragmentos de archivos binarios.La colección
filesalmacena los metadatos del archivo.
Cuando creas un nuevo bucket de GridFS, el driver crea las colecciones fs.chunks y fs.files, a menos que especifiques un nombre diferente en las opciones del método Mongo::Database#fs. El controlador también crea un índice en cada colección para asegurar una recuperación eficiente de los archivos y metadatos relacionados. El driver crea el bucket GridFS, si no existe, solo cuando se realiza la primera operación de escritura. El controlador crea índices solo si no existen y cuando el bucket está vacío. Para obtener más información sobre los índices GridFS, consulta Índices GridFS en el manual de MongoDB Server.
Al almacenar archivos con GridFS, el controlador divide los archivos en fragmentos más pequeños, cada uno representado por un documento independiente en la colección chunks. También crea un documento en la colección files que contiene el ID, el nombre y otros metadatos del archivo. Puede cargar el archivo desde la memoria o desde un flujo de datos. El siguiente diagrama muestra cómo GridFS divide los archivos al cargarlos en un bucket.

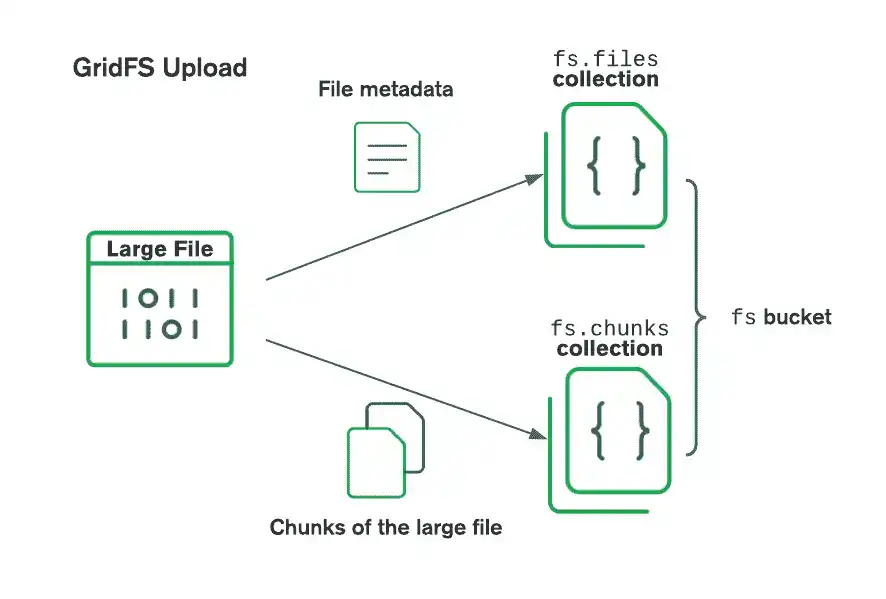
Al recuperar archivos, GridFS obtiene los metadatos de la colección files en el bucket especificado y usa la información para reconstruir el archivo a partir de documentos en la colección chunks. Puede leer el archivo en la memoria o enviarlo a una secuencia.
Crear un bucket de GridFS
Para almacenar o recuperar archivos de GridFS, crea un bucket de GridFS llamando al método fs en una instancia de Mongo::Database. Puede utilizar la instancia FSBucket para realizar operaciones de lectura y guardar en los archivos de tu bucket.
bucket = database.fs
Para crear o hacer referencia a un bucket con un nombre diferente al nombre por defecto fs, pasa el nombre del bucket como un parámetro opcional al método fs, como se muestra en el siguiente ejemplo:
custom_bucket = database.fs(database, bucket_name: 'files')
Cargar archivos
El método upload_from_stream lee el contenido de un flujo de carga y lo guarda en la instancia GridFSBucket.
Puede pasar un Hash como parámetro opcional para configurar el tamaño del fragmento o incluir metadatos adicionales.
El siguiente ejemplo carga un archivo en FSBucket y especifica metadatos para el archivo cargado:
metadata = { uploaded_by: 'username' } File.open('/path/to/file', 'rb') do |file| file_id = bucket.upload_from_stream('test.txt', file, metadata: metadata) puts "Uploaded file with ID: #{file_id}" end
Recuperar información de archivos
En esta sección, puedes aprender a recuperar metadatos de archivos almacenados en la colección files del depósito de GridFS. Los metadatos contienen información sobre el archivo al que se refieren, incluyendo:
El
_iddel archivoEl nombre del archivo
El tamaño del archivo
La fecha y hora de carga
Un documento
metadataen el que puedes almacenar cualquier otra información
Para conocer más sobre los campos que puedes recuperar de la colección files, consulta la documentación de Colección de Archivos GridFS en el manual de MongoDB Server.
Para recuperar archivos de un bucket de GridFS, llame al método find en la instancia FSBucket. El siguiente ejemplo de código recupera e imprime los metadatos de todos los archivos de un bucket de GridFS:
bucket.find.each do |file| puts "Filename: #{file.filename}" end
Para obtener más información sobre cómo consultar MongoDB, consulta Buscar documentos.
Descargar archivos
El método download_to_stream descarga el contenido de un archivo.
Para descargar un archivo por su archivo _id, pase el _id al método. El método download_to_stream escribe el contenido del archivo en el objeto proporcionado. El siguiente ejemplo descarga un archivo por su archivo _id:
file_id = BSON::ObjectId('your_file_id') File.open('/path/to/downloaded_file', 'wb') do |file| bucket.download_to_stream(file_id, file) end
Si tienes el nombre de un archivo, pero no su _id, puedes utilizar el método download_to_stream_by_name. El siguiente ejemplo descarga un archivo llamado mongodb-tutorial:
File.open('/path/to/downloaded_file', 'wb') do |file| bucket.download_to_stream_by_name('mongodb-tutorial', file) end
Nota
Si hay varios documentos con el mismo valor de filename, GridFS recupera el archivo más reciente con ese nombre (según lo determine el campo uploadDate).
Borrar archivos
Utiliza el método delete para remover el documento de la colección de un archivo y los fragmentos asociados de tu bucket. Debe especificar el archivo por su campo _id en lugar de por su nombre de archivo.
El siguiente ejemplo elimina un archivo por su _id:
file_id = BSON::ObjectId('your_file_id') bucket.delete(file_id)
Nota
El método delete solo soporta borrar un archivo a la vez. Para borrar varios archivos, recuperar los archivos del bucket, extraiga el campo _id de los archivos que desea borrar y pase cada valor en llamadas separadas al método delete.
Documentación de la API
Para aprender más sobre cómo usar GridFS para almacenar y recuperar archivos grandes, consulta la siguiente documentación de la API: