Overview
En esta guía, puedes aprender cómo almacenar y recuperar archivos grandes en MongoDB utilizando GridFS. GridFS es una especificación implementada por la librería MongoDB PHP que describe cómo dividir archivos en fragmentos al almacenarlos y volver a ensamblarlos al recuperarlos. La implementación de la librería de GridFS es una abstracción que gestiona las operaciones y la organización del almacenamiento de archivos.
Utiliza GridFS si el tamaño de los archivos supera el límite del tamaño del documento BSON de 16MB. Para obtener información más detallada sobre si GridFS es adecuado para tu caso de uso, consulta GridFS en el manual del MongoDB Server.
Cómo funciona GridFS
GridFS organiza los archivos en un bucket, un grupo de colecciones de MongoDB que contienen los fragmentos de archivos e información que los describe. El bucket contiene las siguientes colecciones, nombradas según la convención definida en la especificación GridFS:
La
chunksla colección almacena los fragmentos de archivos binarios.La colección
filesalmacena los metadatos del archivo.
Cuando creas un nuevo bucket de GridFS, la librería crea las colecciones anteriores, con el prefijo del nombre del bucket por defecto fs, a menos que especifiques un nombre diferente. Además, la librería crea un índice en cada colección para garantizar una recuperación eficiente de los archivos y los metadatos relacionados. La librería crea el bucket GridFS, si no existe, solo cuando se realiza la primera operación de escritura. La librería crea índices solo si no existen y cuando el bucket está vacío. Para obtener más información sobre los índices de GridFS, consulta Índices de GridFS en el manual de MongoDB Server.
Al usar GridFS para almacenar archivos, la biblioteca los divide en fragmentos más pequeños, cada uno representado por un documento independiente en la chunks colección. También crea un documento en la files colección que contiene el ID, el nombre y otros metadatos del archivo. Puede cargar el archivo pasando un flujo a la biblioteca PHP de MongoDB para su consumo o creando un nuevo flujo y escribiendo en él directamente. Para obtener más información sobre los flujos, consulte Flujos.
en el manual de PHP.
Consulta el siguiente diagrama para ver cómo GridFS divide los archivos cuando se suben a un bucket:

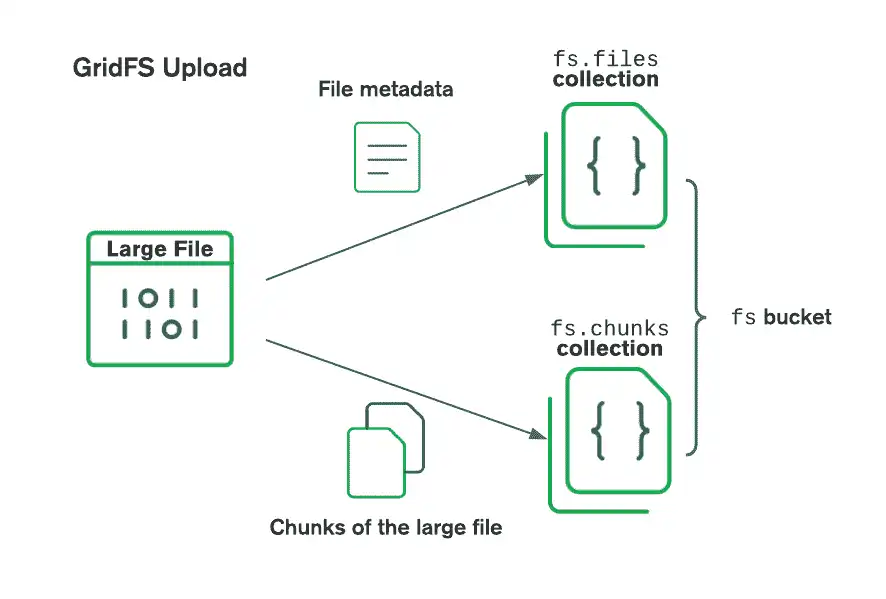
Al recuperar archivos, GridFS obtiene los metadatos de la colección files en el bucket especificado y usa la información para reconstruir el archivo a partir de documentos en la colección chunks. Puedes leer el archivo escribiendo su contenido en un flujo existente o creando uno nuevo que apunte al archivo.
Crear un bucket de GridFS
Para almacenar o recuperar archivos de GridFS, llama al método MongoDB\Database::selectGridFSBucket() en tu base de datos. Este método accede a un bucket existente o crea uno nuevo si aún no existe.
El siguiente ejemplo llama al método selectGridFSBucket() en la base de datos db:
$bucket = $client->db->selectGridFSBucket();
Personaliza el cubo
Se puede personalizar la configuración del contenedor GridFS pasando un arreglo que especifica los valores de las opciones al método selectGridFSBucket(). La siguiente tabla describe algunas opciones que puedes configurar en el arreglo:
Opción | Descripción |
|---|---|
| Specifies the bucket name to use as a prefix for the files and chunks collections.
The default value is 'fs'.Type: string |
| Specifies the chunk size that GridFS splits files into. The default value is 261120.Type: integer |
| Specifies the read concern to use for bucket operations. The default value is the
database's read concern. Type: MongoDB\Driver\ReadConcern |
| Specifies the read preference to use for bucket operations. The default value is the
database's read preference. Type: MongoDB\Driver\ReadPreference |
| Specifies the write concern to use for bucket operations. The default value is the
database's write concern. Type: MongoDB\Driver\WriteConcern |
El siguiente ejemplo crea un depósito llamado 'myCustomBucket' pasando una matriz a selectGridFSBucket() que establece la opción bucketName:
$customBucket = $client->db->selectGridFSBucket( ['bucketName' => 'myCustomBucket'], );
Cargar archivos
Puede cargar archivos en un bucket de GridFS utilizando los siguientes métodos:
MongoDB\GridFS\Bucket::openUploadStream(): Abre un nuevo flujo de carga al que se pueden guardar los contenidos del archivoMongoDB\GridFS\Bucket::uploadFromStream(): Carga el contenido de una transmisión existente a un archivo GridFS
Guardar en un flujo de carga
Utiliza el método openUploadStream() para crear un flujo de subida para un nombre de archivo determinado. El método openUploadStream() permite especificar la información de configuración en un arreglo de opciones, que se puede pasar como parámetro.
Este ejemplo utiliza una transmisión de carga para realizar las siguientes acciones:
Abre un flujo escribible para un nuevo archivo GridFS llamado
'my_file'Establece la opción
metadataen un parámetro de arreglo al métodoopenUploadStream()Llama al método
fwrite()para guardar datos en'my_file', a la que apunta el flujo.Llama al método
fclose()para cerrar el flujo que apunta a'my_file'
$stream = $bucket->openUploadStream('my_file', [ 'metadata' => ['contentType' => 'text/plain'], ]); fwrite($stream, 'Data to store'); fclose($stream);
Subir un flujo existente
Utiliza el método uploadFromStream() para cargar el contenido de un flujo a un nuevo archivo GridFS. El método uploadFromStream() permite especificar la información de configuración en un arreglo de opciones, que se puede pasar como parámetro.
Este ejemplo realiza las siguientes acciones:
Llama al método
fopen()para abrir un archivo ubicado en/path/to/input_filecomo un stream en modo de lectura binaria (rb)Llama al método
uploadFromStream()para cargar el contenido del flujo en un archivo GridFS llamado'new_file'
$file = fopen('/path/to/input_file', 'rb'); $bucket->uploadFromStream('new_file', $file);
Recuperar información de archivos
En esta sección, puedes aprender a recuperar metadatos de archivos almacenados en la colección files del depósito de GridFS. Los metadatos contienen información sobre el archivo al que se refieren, incluyendo:
El
_iddel archivoEl nombre del archivo
La longitud/tamaño del archivo
La fecha y hora de carga
Un documento
metadataen el que puedes almacenar cualquier otra información
Para recuperar archivos de un bucket de GridFS, llama al método MongoDB\GridFS\Bucket::find() en la instancia MongoDB\GridFS\Bucket. El método devuelve una instancia de MongoDB\Driver\Cursor desde la que puede acceder a los resultados. Para obtener más información sobre los objetos Cursor en la MongoDB PHP Library, consulte la Guíade acceso a datos desde un cursor.
Ejemplo
El siguiente ejemplo de código muestra cómo recuperar e imprimir metadatos de archivos en un bucket de GridFS. Utiliza un bucle foreach para iterar sobre el cursor devuelto y mostrar el contenido de los archivos cargados en los ejemplos de Cargar Archivos:
$files = $bucket->find(); foreach ($files as $fileDocument) { echo toJSON($fileDocument), PHP_EOL; }
{ "_id" : { "$oid" : "..." }, "chunkSize" : 261120, "filename" : "my_file", "length" : 13, "uploadDate" : { ... }, "metadata" : { "contentType" : "text/plain" } } { "_id" : { "$oid" : "..." }, "chunkSize" : 261120, "filename" : "new_file", "length" : 13, "uploadDate" : { ... } }
El find() método acepta varias especificaciones de consulta. Puede usar su $options parámetro para especificar el orden de clasificación, el número máximo de documentos a devolver y el número de documentos que se omitirán antes de devolver. Para ver una lista de las opciones disponibles, consulte la documentación de la API.
Nota
El ejemplo anterior llama al método toJSON() para imprimir los metadatos del archivo como JSON Extendido, definido en el siguiente código:
function toJSON(object $document): string { return MongoDB\BSON\Document::fromPHP($document)->toRelaxedExtendedJSON(); }
Descargar archivos
Puede descargar archivos de un bucket GridFS utilizando los siguientes métodos:
MongoDB\GridFS\Bucket::openDownloadStreamByName()oMongoDB\GridFS\Bucket::openDownloadStream(): Abre un nuevo flujo de descarga desde el que puede leer el contenido del archivoMongoDB\GridFS\Bucket::downloadToStream(): Guardar el archivo completo en un flujo de descarga existente
Leer desde un flujo de descarga
Puedes descargar archivos de tu base de datos MongoDB utilizando el método MongoDB\GridFS\Bucket::openDownloadStreamByName() para crear un flujo de descarga.
Este ejemplo utiliza un flujo de descarga para realizar las siguientes acciones:
Selecciona un archivo GridFS llamado
'my_file', subido en el ejemplo Write to an Upload Stream, y lo abre como un flujo legible.Llama al método
stream_get_contents()para leer el contenido de'my_file'Imprime el contenido del archivo
Llama al método
fclose()para cerrar el flujo de descarga que apunta a'my_file'
$stream = $bucket->openDownloadStreamByName('my_file'); $contents = stream_get_contents($stream); echo $contents, PHP_EOL; fclose($stream);
"Data to store"
Nota
Si hay varios documentos con el mismo nombre de archivo, GridFS transmitirá el archivo más reciente con el nombre dado (según lo determinado por el campo uploadDate).
Alternativamente, puedes usar el método MongoDB\GridFS\Bucket::openDownloadStream(), que toma el campo _id de un archivo como parámetro:
$stream = $bucket->openDownloadStream(new ObjectId('66e0a5487c880f844c0a32b1')); $contents = stream_get_contents($stream); fclose($stream);
Nota
La API de transmisión de GridFS no puede cargar fragmentos parciales. Cuando una secuencia de descarga necesita obtener un fragmento de MongoDB, lo carga completo en la memoria. El tamaño de fragmento predeterminado de 255kilobytes suele ser suficiente, pero puedes reducir el tamaño de fragmento para reducir la sobrecarga de memoria o aumentar el tamaño de fragmento al trabajar con archivos más grandes. Para obtener más información sobre cómo configurar el tamaño del fragmento, consulta la sección Personalizar el depósito de esta página.
Descargar una revisión de archivo
Cuando su bucket contiene varios archivos con el mismo nombre, GridFS selecciona la versión más reciente del archivo de forma predeterminada. Para diferenciar cada archivo con el mismo nombre, GridFS les asigna un número de revisión, ordenado por fecha de carga.
El número de revisión del archivo original es 0 y el siguiente número de revisión más reciente es 1. También puede especificar valores negativos que correspondan a la fecha de la revisión. El valor de revisión -1 hace referencia a la revisión más reciente y -2 a la siguiente.
Puedes indicar a GridFS que descargue una revisión específica de un archivo pasando un arreglo de opciones al método openDownloadStreamByName() y especificando la opción revision. El siguiente ejemplo lee el contenido del archivo original llamado 'my_file' en lugar de la revisión más reciente:
$stream = $bucket->openDownloadStreamByName('my_file', ['revision' => 0]); $contents = stream_get_contents($stream); fclose($stream);
Descargar en una transmisión existente
Puedes descargar el contenido de un archivo GridFS a un flujo existente llamando al método MongoDB\GridFS\Bucket::downloadToStream() en tu contenedor.
Este ejemplo realiza las siguientes acciones:
Llama al método
fopen()para abrir un archivo ubicado en/path/to/output_filecomo un flujo en modo de escritura binaria (wb)Descarga un archivo GridFS que tiene un valor
_iddeObjectId('66e0a5487c880f844c0a32b1')al flujo
$file = fopen('/path/to/output_file', 'wb'); $bucket->downloadToStream( new ObjectId('66e0a5487c880f844c0a32b1'), $file, );
Renombrar archivos
Utilice el método MongoDB\GridFS\Bucket::rename() para actualizar el nombre de un archivo GridFS en su bucket. Pase los siguientes parámetros al método rename():
_idvalor del archivo que se desea renombrarNombre del archivo nuevo
El siguiente ejemplo muestra cómo actualizar el campo filename a 'new_file_name' haciendo referencia al valor _id de un archivo:
$bucket->rename(new ObjectId('66e0a5487c880f844c0a32b1'), 'new_file_name');
Alternativamente, puedes usar el método MongoDB\GridFS\Bucket::renameByName() para renombrar un archivo de GridFS y todas sus revisiones de archivo. Pasa los siguientes parámetros al método renameByName():
filenamevalor que quieres cambiarNombre del archivo nuevo
El siguiente ejemplo cambia el nombre de todos los archivos que tienen un valor de filename igual a 'my_file':
$bucket->renameByName('my_file', 'new_file_name');
Borrar archivos
Utilice el método MongoDB\GridFS\Bucket::delete() para eliminar el documento de colección de un archivo GridFS y los fragmentos asociados de su bucket. Esto elimina el archivo. Pase el valor _id del archivo que desea eliminar como parámetro al método delete().
El siguiente ejemplo le muestra cómo borrar un archivo haciendo referencia a su campo _id:
$bucket->delete(new ObjectId('66e0a5487c880f844c0a32b1'));
Alternativamente, puedes usar el método MongoDB\GridFS\Bucket::deleteByName() para borrar un archivo GridFS y todas sus revisiones de archivos. Pasa el valor filename del archivo que deseas borrar como parámetro al método deleteByName(), como se muestra en el siguiente código:
$bucket->deleteByName('my_file');
Documentación de la API
Para aprender más sobre el uso de la librería MongoDB PHP para almacenar y recuperar archivos grandes, consulte la siguiente documentación de la API: