Al diseñar sistemas MongoDB que utilizan MongoDB Search y MongoDB Vector Search, existen dos tipos comunes de implementación:
Una arquitectura co-localizada donde
mongody los procesosmongotcomparten el mismo host. Esta arquitectura es adecuada para el desarrollo y para cargas de trabajo pequeñas de búsqueda o búsqueda vectorial.Un modelo de infraestructura dedicado donde
mongodymongotse ejecutan en máquinas separadas, cada una de ellas dimensionada según lo requiera la carga de trabajo. Esta infraestructura se recomienda para aplicaciones que requieren alta disponibilidad, particionado, o cargas de trabajo sustanciales de búsqueda o vectoriales con altas demandas de consultas de búsqueda e indexación.
Esta sección describe ambos tipos de implementación. También describe las implicaciones de implementar mongot en clústeres de MongoDB fragmentados.
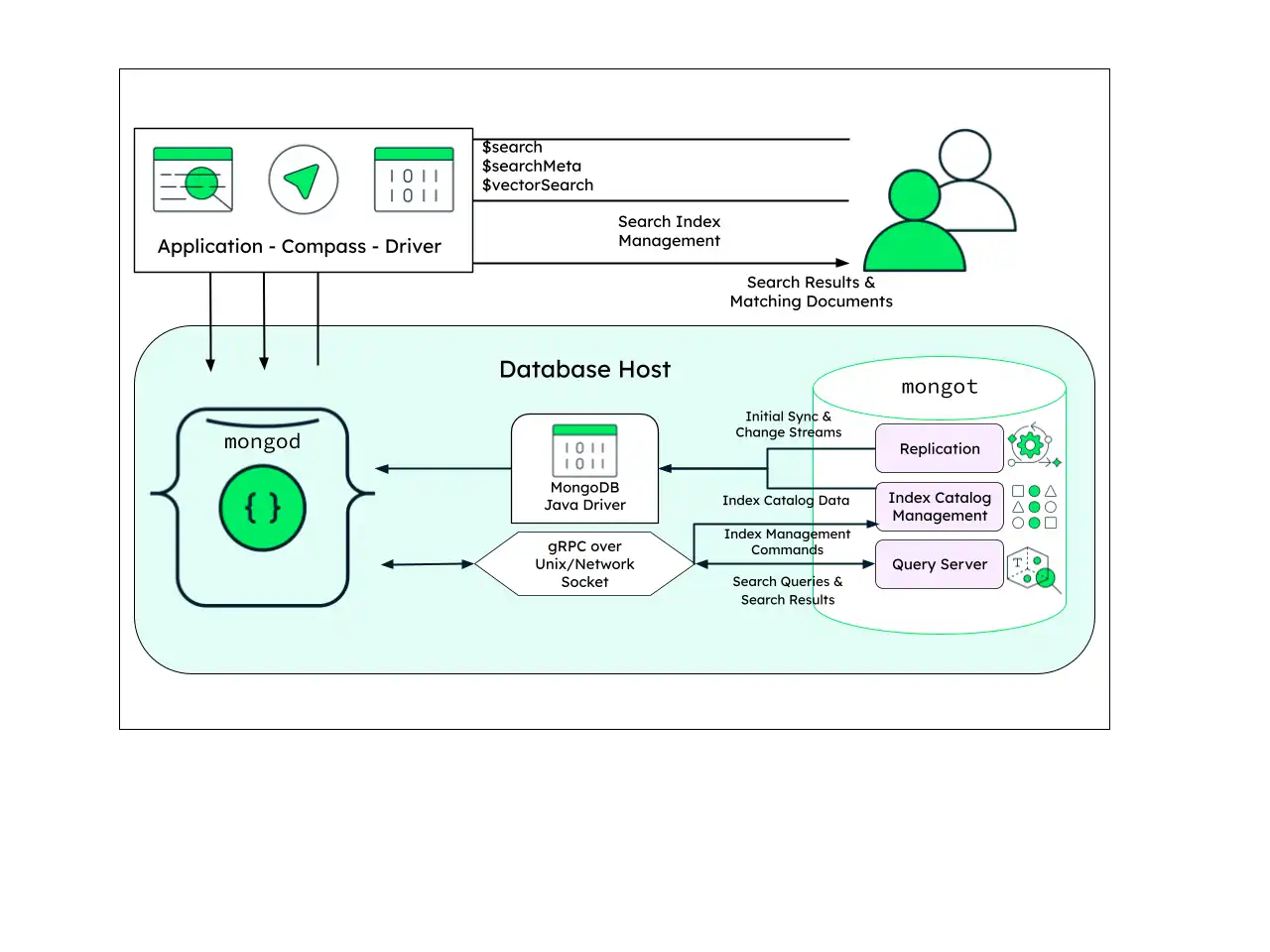
Arquitectura Co-Ubicada
Esta es la arquitectura más simple, recomendada para entornos de desarrollo o cualquier situación que requiera iteración rápida. Destaca en la creación rápida de prototipos y requiere la menor cantidad de configuración.
La implementación consta de una sola máquina que ejecuta tanto los procesos mongod como mongot. Toda la comunicación puede realizarse a través de las direcciones localhost, y todas las funcionalidades de autenticación y seguridad pueden desactivarse o hacerse más permisivas.
Para la mayoría de las cargas de trabajo de búsqueda pequeñas, puedes expandir esta arquitectura a un set de réplicas multinodo. Utiliza precaución al implementar una arquitectura en co-ubicación, y supervisa señales de contención de recursos.

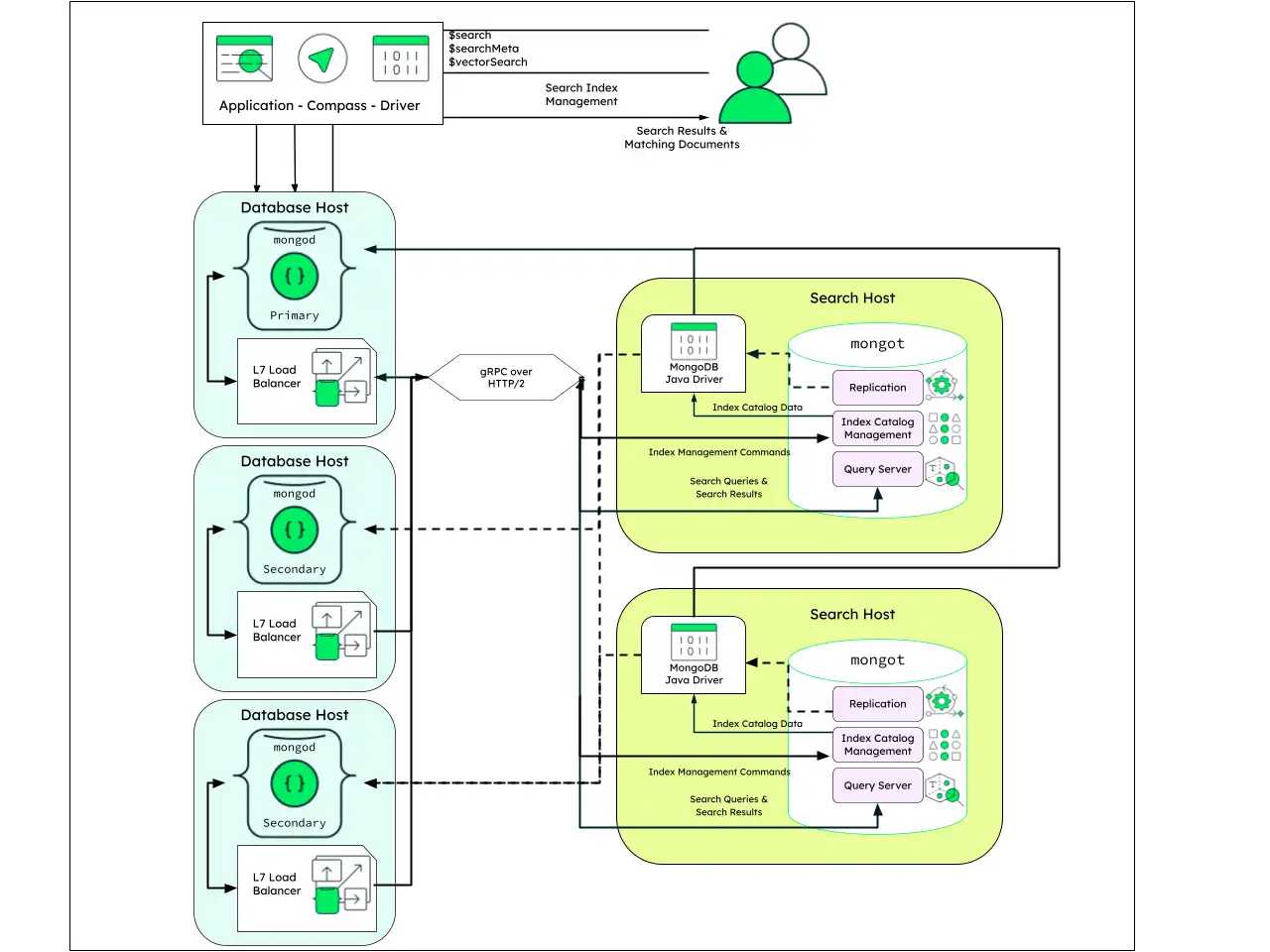
Infraestructura dedicada
Esta es una arquitectura de propósito general, recomendada para entornos de producción. La infraestructura dedicada admite tanto la escalabilidad horizontal como vertical tanto para los nodos de la base de datos como para los nodos de búsqueda.
La implementación consiste en al menos tres máquinas ejecutando mongod en una configuración de set de réplicas, y al menos dos máquinas ejecutando mongot. Para proporcionar alta disponibilidad al consultar Search, los nodos mongod requieren un balanceador de carga a nivel de aplicación. Considera un balanceador de carga como Envoy y usa una estrategia de balanceo de carga como round-robin por solicitud.
No se requiere balanceo de carga en la dirección opuesta. mongot elige automáticamente un nodo mongod con el cual comunicarse para la replicación de datos y los datos del catálogo de índices según su configuración.
Nota
Almacenamiento del índice de búsqueda
Cada mongot mantiene índices que se compilan a partir de los datos obtenidos continuamente de la base de datos. Las definiciones de índices (metadatos) se almacenan en la propia base de datos.
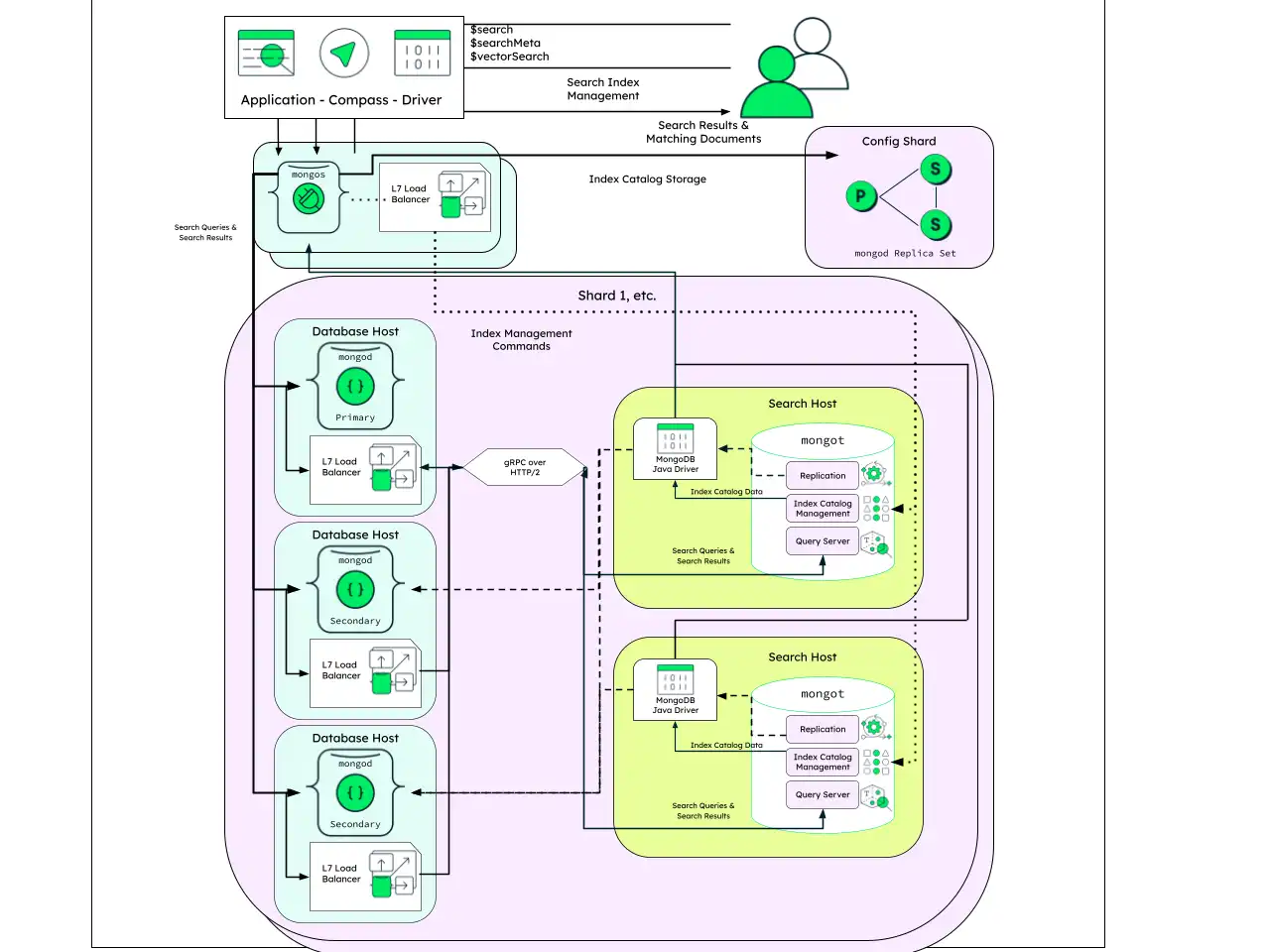
Topología fragmentada
Esta arquitectura es similar a la arquitectura de infraestructura dedicada, pero la configuración del set de réplicas se duplica en cada partición individual.
Nota
Aunque solo debes configurar mongot para replicar desde una partición, mongot aún requiere que se configure la dirección del router para acceder al catálogo de índices.
Con la arquitectura de topología particionada, mongot solo pertenece a una única partición a la vez. Como resultado, los balanceadores de carga dentro de cada partición deben configurarse únicamente para dirigir el tráfico a esa partición individual.
Si agregas fragmentos a una colección con un índice MongoDB Search existente, se produce una sincronización inicial en los fragmentos recién agregados para ese índice MongoDB Search. El índice de MongoDB Search de cada partición contiene únicamente los documents de la colección que existen en esa partición.
Importante
Almacenamiento del Índice de Búsqueda en Clústeres Fragmentados
En un clúster particionado, los índices de búsqueda se distribuyen a través de los procesos mongot asociados con cada partición. Tenga esto en cuenta al planificar sus políticas de copia de seguridad y recuperación, ya que deberá considerar tanto los datos de la base de datos como los datos del índice de búsqueda almacenados en los nodos mongot de cada partición.
Para obtener más información, consulte partición una colección global.
Advertencia
Si divide en particiones una colección que ya tiene un índice de MongoDB Search, puedes experimentar un breve período de resultados de búsqueda incompletos mientras se está construyendo el índice en una partición.
Además, si se añade una partición a una colección particionada que contenga un índice de búsqueda de MongoDB, las consultas de búsqueda realizadas sobre esa colección podrían devolver resultados incompletos hasta que se complete el proceso de sincronización inicial en las particiones añadidas. Para aprender más, consulte solución de problemas de sincronización inicial.