Overview
En esta guía, aprenderá a almacenar y recuperar archivos grandes en MongoDB usando GridFS. GridFS es una especificación que describe cómo dividir archivos en fragmentos al almacenarlos y reensamblarlos al recuperarlos. La implementación de GridFS en el controlador de Scala es una abstracción que gestiona las operaciones y la organización del almacenamiento de archivos.
Utiliza GridFS si el tamaño de los archivos supera el límite del tamaño del documento BSON de 16MB. Para obtener información más detallada sobre si GridFS es adecuado para tu caso de uso, consulta GridFS en el manual del MongoDB Server.
Las siguientes secciones describen las operaciones de GridFS y cómo realizarlas.
Cómo funciona GridFS
GridFS organiza los archivos en un bucket, un grupo de colecciones de MongoDB que contienen los fragmentos de archivos e información que los describe. El bucket contiene las siguientes colecciones, nombradas según la convención definida en la especificación GridFS:
La
chunksla colección almacena los fragmentos de archivos binarios.La colección
filesalmacena los metadatos del archivo.
Cuando crees un nuevo bucket GridFS, el driver crea las colecciones fs.chunks y fs.files, a menos que especifiques un nombre diferente en el constructor GridFSBucket(). El controlador también crea un índice en cada colección para asegurar una recuperación eficiente de los archivos y metadatos relacionados. El driver crea el bucket GridFS, si no existe, solo cuando se realiza la primera operación de escritura. El controlador crea índices solo si no existen y cuando el bucket está vacío. Para obtener más información sobre los índices GridFS, consulta Índices GridFS en el manual de MongoDB Server.
Al almacenar archivos con GridFS, el controlador divide los archivos en fragmentos más pequeños, cada uno representado por un documento independiente en la colección chunks. También crea un documento en la files colección que contiene un ID de archivo, nombre de archivo y otros metadatos del archivo. Puedes cargar el archivo desde la memoria o desde un flujo. Consulta el siguiente diagrama para ver cómo GridFS divide los archivos al cargarlos en un bucket.

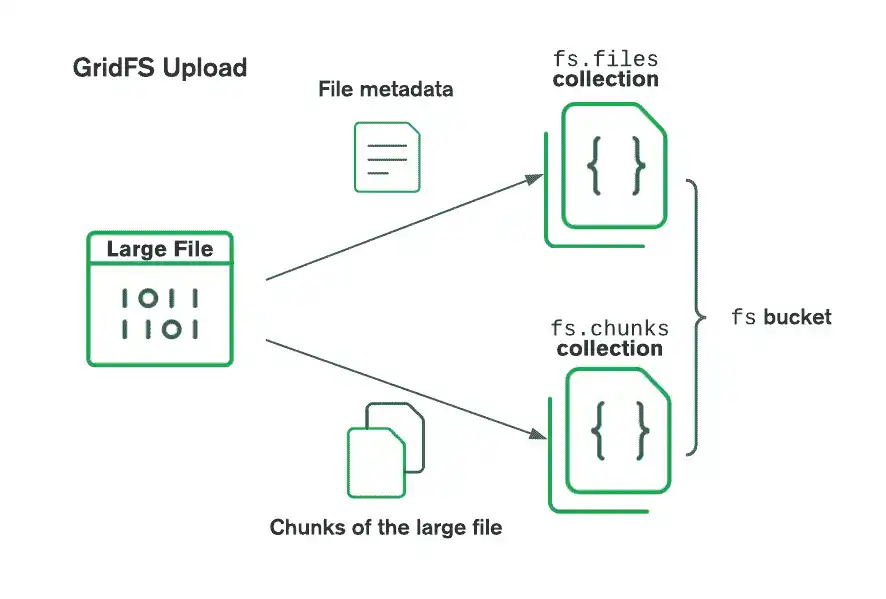
Al recuperar archivos, GridFS obtiene los metadatos de la colección files en el bucket especificado y usa la información para reconstruir el archivo a partir de documentos en la colección chunks. Puede leer el archivo en la memoria o enviarlo a una secuencia.
Crear un bucket de GridFS
Para almacenar o recuperar archivos de GridFS, cree un contenedor GridFS llamando al constructor GridFSBucket() y pasando una instancia MongoDatabase. Puede usar la instancia GridFSBucket para ejecutar operaciones de lectura y escritura en los archivos de su contenedor.
val bucket = GridFSBucket(database)
Para crear o hacer referencia a un depósito con un nombre personalizado distinto del nombre predeterminado fs, pase el nombre del depósito como segundo parámetro al constructor GridFSBucket(), como se muestra en el siguiente ejemplo:
val filesBucket = GridFSBucket(database, "files")
Tip
Configuración de Tiempo de Espera
Puedes usar el ajuste de tiempo de espera de operación del lado del cliente (CSOT) para limitar la cantidad de tiempo en el que el servidor puede finalizar operaciones GridFS en tu bucket. Para aprender más sobre el uso de esta configuración con GridFS, consulta la SecciónGridFS de la guía Limitar el tiempo de ejecución del servidor.
Cargar archivos
El método GridFSBucket.uploadFromObservable() lee el contenido de un Observable[ByteBuffer] y lo guarda en la instancia de GridFSBucket.
Puede utilizar el tipo GridFSUploadOptions para configurar el tamaño del fragmento o incluir metadatos adicionales.
El siguiente ejemplo carga el contenido de un Observable[ByteBuffer] en GridFSBucket:
// Get the input stream val observableToUploadFrom = Observable( Seq(ByteBuffer.wrap("MongoDB Tutorial".getBytes(StandardCharsets.UTF_8))) ) // Create some custom options val options = new GridFSUploadOptions() .chunkSizeBytes(358400) .metadata(Document("type" -> "presentation")) // Upload the file val fileIdObservable = filesBucket.uploadFromObservable("mongodb-tutorial", observableToUploadFrom, options) val fileId = Await.result(fileIdObservable.toFuture(), Duration(10, TimeUnit.SECONDS)) println(s"File uploaded with id: ${fileId.toHexString}")
Recuperar información de archivos
En esta sección, puedes aprender a recuperar metadatos de archivos almacenados en la colección files del depósito de GridFS. Los metadatos contienen información sobre el archivo al que se refieren, incluyendo:
El
_iddel archivoEl nombre del archivo
La longitud/tamaño del archivo
La fecha y hora de carga
Un documento
metadataen el que puedes almacenar cualquier otra información
Para conocer más sobre los campos que puedes recuperar de la colección files, consulta la documentación de Colección de Archivos GridFS en el manual de MongoDB Server.
Para recuperar archivos de un bucket de GridFS, llame al método find() en la instancia GridFSBucket. El siguiente ejemplo de código recupera e imprime los metadatos de todos los archivos de un bucket de GridFS:
val filesObservable = filesBucket.find() val results = Await.result(filesObservable.toFuture(), Duration(10, TimeUnit.SECONDS)) results.foreach(file => println(s" - ${file.getFilename}"))
Para obtener más información sobre cómo consultar MongoDB, consulte Recuperar datos.
Descargar archivos
El método downloadToObservable() devuelve un Observable[ByteBuffer] que lee el contenido desde MongoDB.
Para descargar un archivo por su _id de archivo, pasa el _id al método. El siguiente ejemplo descarga un archivo por su archivo _id:
val downloadObservable = filesBucket.downloadToObservable("<example file ID>") val downloadById = Await.result(downloadObservable.toFuture(), Duration(10, TimeUnit.SECONDS))
Si no conoces el _id del archivo pero sabes el nombre del archivo, entonces puedes pasar el nombre del archivo al método downloadToObservable(). El siguiente ejemplo descarga un archivo llamado mongodb-tutorial:
val downloadObservable = filesBucket.downloadToObservable("mongodb-tutorial") val downloadById = Await.result(downloadObservable.toFuture(), Duration(10, TimeUnit.SECONDS))
Nota
Si hay varios documentos con el mismo valor filename, GridFS recuperará el archivo más reciente con el nombre dado (según lo determine el campo uploadDate).
Renombrar archivos
Utiliza el método rename() para actualizar el nombre de un archivo GridFS en su bucket. Debes especificar el archivo que deseas renombrar por su campo _id en lugar de su nombre de archivo.
El siguiente ejemplo renombra un archivo a mongodbTutorial:
val renameObservable = filesBucket.rename("<example file ID>", "mongodbTutorial") Await.result(renameObservable.toFuture(), Duration(10, TimeUnit.SECONDS))
Nota
El método rename() solo admite la actualización del nombre de un archivo a la vez. Para cambiar el nombre de varios archivos, recupere una lista de archivos que coincidan con el nombre de archivo desde el bucket, extraiga el campo _id de los archivos a los que desea cambiar el nombre y pase cada valor en llamadas por separado al método rename().
Borrar archivos
Utiliza el método delete() para remover el documento de la colección de un archivo y los fragmentos asociados de tu bucket. Debe especificar el archivo por su campo _id en lugar de por su nombre de archivo.
El siguiente ejemplo elimina un archivo por su _id:
val deleteObservable = filesBucket.delete("<example file ID>") Await.result(deleteObservable.toFuture(), Duration(10, TimeUnit.SECONDS))
Nota
El método delete() solo soporta borrar un archivo a la vez. Para borrar varios archivos, recuperar los archivos del bucket, extraiga el campo _id de los archivos que desea borrar y pase cada valor en llamadas separadas al método delete().
Documentación de la API
Para aprender más sobre cómo usar GridFS para almacenar y recuperar archivos grandes, consulta la siguiente documentación de la API: