Overview
En esta guía, puedes aprender cómo almacenar y recuperar archivos grandes en MongoDB utilizando GridFS. GridFS es una especificación implementada por el driver de C++ que describe cómo dividir archivos en fragmentos al almacenarlos y reorganizarlos al recuperarlos. La implementación de GridFS en el driver es una abstracción que gestiona las operaciones y la organización del almacenamiento de archivos.
Utiliza GridFS si el tamaño de tus archivos excede el límite de tamaño del documento BSON de 16MB. Para obtener información más detallada sobre si GridFS es adecuado para su caso de uso, consulte GridFS en el manual del MongoDB Server.
Cómo funciona GridFS
GridFS organiza los archivos en un bucket, un grupo de colecciones de MongoDB que contienen los fragmentos de archivos e información que los describe. El bucket contiene las siguientes colecciones, nombradas según la convención definida en la especificación GridFS:
chunkscolección, que almacena los fragmentos de archivo binariofilescolección, que almacena los metadatos del archivo
El driver crea el bucket de GridFS, si no existe, cuando se guardan por primera vez datos en él. El bucket contiene las colecciones anteriores con el prefijo del nombre de bucket por defecto fs, a menos que especifiques un nombre diferente. Para asegurar la recuperación eficiente de los archivos y metadatos relacionados, el controlador crea un índice en cada colección. El driver asegura que estos índices existan antes de realizar operaciones de lectura y escritura en el bucket de GridFS.
Para obtener más información sobre los índices de GridFS, consulta Índices de GridFS en el manual del servidor MongoDB.
Cuando se utiliza GridFS para almacenar archivos, el driver divide los archivos en fragmentos más pequeños, cada uno representado por un documento independiente en la colección chunks. También crea un documento en la colección files que contiene un ID de archivo, nombre de archivo y otros metadatos del archivo. Puedes cargar el archivo pasando un flujo al controlador de C++ para que lo procese o crear un nuevo flujo y escribir directamente en él.
El siguiente diagrama muestra cómo GridFS divide los archivos cuando se cargan en un bucket.

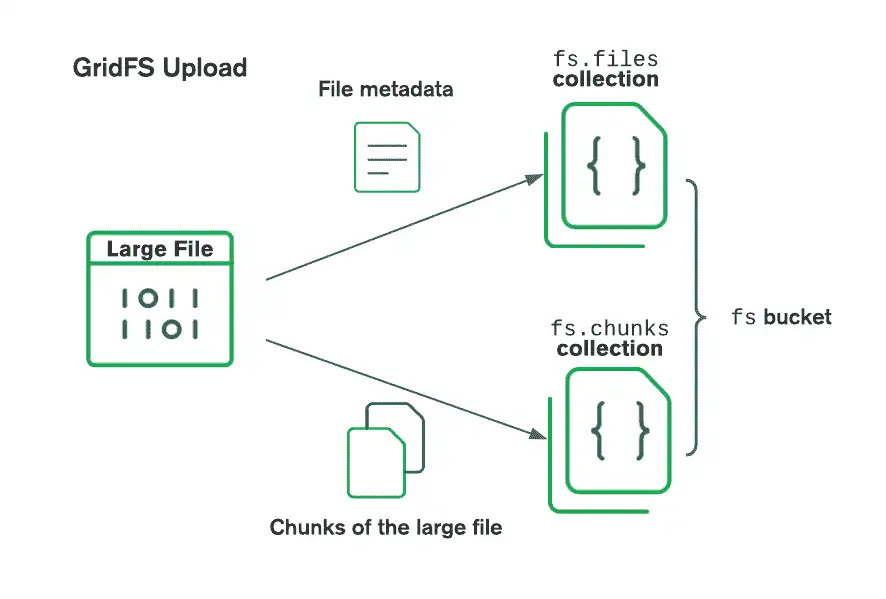
Al recuperar archivos, GridFS obtiene los metadatos de la colección files en el bucket especificado y utiliza la información para reconstruir el archivo a partir de los documentos en la colección chunks. Se puede leer el archivo escribiendo su contenido en un flujo existente o creando un nuevo flujo que apunte al archivo.
Crear un bucket de GridFS
Para empezar a almacenar o recuperar archivos de GridFS, llama al método gridfs_bucket() en tu base de datos. Este método accede a un bucket existente o crea uno nuevo si aún no existe.
El siguiente ejemplo llama al método gridfs_bucket() en la base de datos db:
auto bucket = db.gridfs_bucket();
Personaliza el cubo
Puedes personalizar la configuración del bucket de GridFS pasando una instancia de la clase mongocxx::options::gridfs::bucket como un argumento opcional al método gridfs_bucket(). La siguiente tabla describe los campos que puedes configurar en una instancia de mongocxx::options::gridfs::bucket:
Campo | Descripción |
|---|---|
| Specifies the bucket name to use as a prefix for the files and chunks collections.
The default value is "fs".Type: std::string |
| Specifies the chunk size that GridFS splits files into. The default value is 261120.Type: std::int32_t |
| Specifies the read concern to use for bucket operations. The default value is the
database's read concern. Type: mongocxx::read_concern |
| Specifies the read preference to use for bucket operations. The default value is the
database's read preference. Type: mongocxx::read_preference |
| Specifies the write concern to use for bucket operations. The default value is the
database's write concern. Type: mongocxx::write_concern |
El siguiente ejemplo crea un bucket llamado "myCustomBucket" configurando el campo bucket_name de una instancia mongocxx::options::gridfs::bucket:
mongocxx::options::gridfs::bucket opts; opts.bucket_name("myCustomBucket"); auto bucket = db.gridfs_bucket(opts);
Cargar archivos
Puede cargar archivos en un bucket de GridFS utilizando los siguientes métodos:
open_upload_stream(): Abre un nuevo flujo de subida en el que puedes guardar el contenido del archivo
upload_from_stream(): Carga el contenido de un flujo existente a un archivo de GridFS
Guardar en un flujo de carga
Utiliza el método open_upload_stream() para crear una secuencia de subida para un nombre de archivo determinado. El método open_upload_stream() permite especificar información de configuración en una instancia options::gridfs::upload, la cual se puede pasar como parámetro.
Este ejemplo utiliza una transmisión de carga para realizar las siguientes acciones:
Establece el campo
chunk_size_bytesde una instancia de opcionesAbre una secuencia grabable para un nuevo archivo GridFS llamado
"my_file"y aplica la opciónchunk_size_bytesLlama al método
write()para guardar datos enmy_file, a la que apunta el flujo.Llama al método
close()para cerrar el flujo que apunta amy_file
mongocxx::options::gridfs::upload opts; opts.chunk_size_bytes(1048576); auto uploader = bucket.open_upload_stream("my_file", opts); // ASCII for "HelloWorld" std::uint8_t bytes[10] = {72, 101, 108, 108, 111, 87, 111, 114, 108, 100}; for (auto i = 0; i < 5; ++i) { uploader.write(bytes, 10); } uploader.close();
Subir un flujo existente
Utilice el método upload_from_stream() para cargar el contenido de una secuencia a un nuevo archivo GridFS. El método upload_from_stream() permite especificar información de configuración en una instancia options::gridfs::upload, que puede pasar como parámetro.
Este ejemplo realiza las siguientes acciones:
Abre un archivo ubicado en
/path/to/input_filecomo un flujo en modo de lectura binariaLlama al método
upload_from_stream()para cargar el contenido del flujo en un archivo GridFS llamado"new_file"
std::ifstream file("/path/to/input_file", std::ios::binary); bucket.upload_from_stream("new_file", &file);
Recuperar información de archivos
En esta sección, puedes aprender a recuperar metadatos de archivos almacenados en la colección files del depósito de GridFS. Los metadatos contienen información sobre el archivo al que se refieren, incluyendo:
El
_iddel archivoEl nombre del archivo
La longitud/tamaño del archivo
La fecha y hora de carga
Un documento
metadataen el que puedes almacenar otra información
Para recuperar archivos de un bucket de GridFS, se debe llamar al método mongocxx::gridfs::bucket::find() en el bucket. El método devuelve una instancia de mongocxx::cursor desde la cual puede acceder a los resultados. Para saber más sobre los cursores, consulta el
Guíade acceso a datos desde un cursor.
Ejemplo
El siguiente ejemplo de código muestra cómo recuperar e imprimir los metadatos de archivos de un bucket GridFS. Utiliza un bucle for para recorrer el cursor devuelto y mostrar el contenido de los archivos subidos en los ejemplos Subir Archivos:
auto cursor = bucket.find({}); for (auto&& doc : cursor) { std::cout << bsoncxx::to_json(doc) << std::endl; }
{ "_id" : { "$oid" : "..." }, "length" : 13, "chunkSize" : 261120, "uploadDate" : { "$date" : ... }, "filename" : "new_file" } { "_id" : { "$oid" : "..." }, "length" : 50, "chunkSize" : 1048576, "uploadDate" : { "$date" : ... }, "filename" : "my_file" }
El find() método acepta varias especificaciones de consulta. Puede usar su mongocxx::options::find parámetro para especificar el orden de clasificación, el número máximo de documentos a devolver y el número de documentos que se omitirán antes de devolver. Para ver una lista de las opciones disponibles, consulte la documentación de la API.
Descargar archivos
Puede descargar archivos de un bucket GridFS utilizando los siguientes métodos:
open_download_stream(): Abre un nuevo stream de descargar desde el que puedes leer el contenido del archivo
download_to_stream(): escribe el archivo completo en un flujo de descarga existente
Leer desde un flujo de descarga
Puedes descargar archivos de tu base de datos MongoDB utilizando el método open_download_stream() para crear un flujo de descarga.
Este ejemplo utiliza un flujo de descarga para realizar las siguientes acciones:
Recupera el valor
_iddel archivo GridFS llamado"new_file"Pasa el valor
_idal métodoopen_download_stream()para abrir el archivo como un flujo legibleCrea un vector
bufferpara almacenar el contenido del archivoLlama al método
read()para leer el contenido del archivo desde el flujodownloaderal vector
auto doc = db["fs.files"].find_one(make_document(kvp("filename", "new_file"))); auto id = doc->view()["_id"].get_value(); auto downloader = bucket.open_download_stream(id); std::vector<uint8_t> buffer(downloader.file_length()); downloader.read(buffer.data(), buffer.size());
Descargar en una transmisión existente
Puedes descargar el contenido de un archivo GridFS a un flujo existente llamando al método download_to_stream() en tu contenedor.
Este ejemplo realiza las siguientes acciones:
Abre un archivo ubicado en
/path/to/output_filecomo un flujo en modo binario de escrituraRecupera el valor
_iddel archivo GridFS llamado"new_file"Pasa el valor
_idadownload_to_stream()para descargar el archivo al flujo
std::ofstream output_file("/path/to/output_file", std::ios::binary); auto doc = db["fs.files"].find_one(make_document(kvp("filename", "new_file"))); auto id = doc->view()["_id"].get_value(); bucket.download_to_stream(id, &output_file);
Borrar archivos
Utilice el método delete_file() para eliminar el documento de colección de un archivo y los fragmentos asociados de su bucket. Esto elimina el archivo. Debe especificar el archivo por su campo _id en lugar de por su nombre.
El siguiente ejemplo muestra cómo borrar un archivo llamado "my_file" pasando su valor _id a delete_file():
auto doc = db["fs.files"].find_one(make_document(kvp("filename", "my_file"))); auto id = doc->view()["_id"].get_value(); bucket.delete_file(id);
Nota
Revisiones de archivos
El método delete_file() solo admite la eliminación de un archivo a la vez. Si deseas borrar cada versión de archivo, o archivos con diferentes tiempos de carga que comparten el mismo nombre de archivo, recopila los valores de _id de cada versión. A continuación, pasa cada valor de _id en llamadas separadas al método delete_file().
Documentación de la API
Para obtener más información sobre cómo usar el controlador de C++ para almacenar y recuperar archivos grandes, consulta la siguiente documentación de la API: