Overview
En esta guía, puede aprender la siguiente información fundamental sobre Apache Kafka y Kafka Connect:
¿Qué son Apache Kafka y Kafka Connect?
Qué problemas resuelven Apache Kafka y Kafka Connect
Por qué Apache Kafka y Kafka Connect son útiles
Cómo se mueven los datos a través de un pipeline de Apache Kafka y Kafka Connect
Apache Kafka
Apache Kafka es un sistema de mensajería publish/subscribe de código abierto. Apache Kafka proporciona un sistema flexible, tolerante a fallos y escalable horizontalmente para mover datos a través de almacenes de datos y aplicaciones. Un sistema es tolerante a fallos si puede seguir funcionando incluso cuando ciertos componentes del sistema dejan de funcionar. Un sistema es escalable horizontalmente si se puede ampliar para gestionar cargas de trabajo más grandes añadiendo más máquinas, en lugar de mejorar el hardware de una máquina.
Para obtener más información sobre Apache Kafka, consulta los siguientes recursos:
Conexión Kafka
Kafka Connect es un componente de Apache Kafka que soluciona el problema de conectar Apache Kafka a almacenes de datos como MongoDB. Kafka Connect soluciona este problema proporcionando los siguientes recursos:
Un tiempo de ejecución tolerante a fallos para transferir datos desde y hacia los almacenes de datos.
Un marco para que la comunidad de Apache Kafka comparta soluciones para conectar Apache Kafka a diferentes almacenes de datos.
El framework Kafka Connect define una API para que los desarrolladores creen conectores reutilizables. Los conectores permiten que las implementaciones de Kafka Connect interactúen con un almacén de datos específico como fuente o receptor de datos. El conector Kafka de MongoDB es uno de estos conectores.
Para obtener más información sobre Kafka Connect, consulte los siguientes recursos:
Documentación oficial de Apache Kafka, Guía de conexión de Kafka
Cómo construir tu primer Connector para Kafka Connect de la Fundación Apache Software
Tip
Utilizar Kafka Connect en lugar de clientes Producer/Consumer al conectar a almacenes de datos
Si bien podría escribir su propia aplicación para conectar Apache Kafka a un almacén de datos específico usando clientes productores y consumidores, es posible que Kafka Connect sea más adecuado para usted. Aquí hay algunas razones para usar Kafka Connect:
Kafka Connect tiene una arquitectura distribuida tolerante a errores para garantizar una pipeline confiable.
Existe un gran número de conectores mantenidos por la Community para conectar Apache Kafka a almacenes de datos populares como MongoDB, PostgreSQL y MySQL mediante el marco de Kafka Connect. Esto reduce la cantidad de código repetitivo que debe escribir y mantener para gestionar las conexiones a la base de datos, el manejo de errores, la integración de la fila de letra muerta y otros problemas relacionados con la conexión de Apache Kafka a un almacén de datos.
Tienes la opción de usar un clúster gestionado de Kafka Connect de Confluent.
Diagrama
El siguiente diagrama muestra cómo fluye la información a través de una pipeline de datos de ejemplo construida con Apache Kafka y Kafka Connect. El pipeline de ejemplo utiliza un clúster de MongoDB como fuente de datos y un clúster de MongoDB como destino de datos.

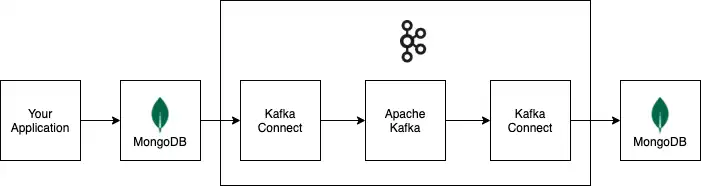
Todos los conectores y tiendas de datos en la pipeline del ejemplo son opcionales. Puede reemplazarlos por los conectores y almacenes de datos que necesita para su implementación.