Overview
En esta guía, puedes aprender cómo almacenar y recuperar archivos grandes en MongoDB utilizando GridFS. GridFS es una especificación que describe cómo dividir archivos en fragmentos durante el almacenamiento y volver a ensamblarlos durante la recuperación. La implementación del driver Rust de GridFS gestiona las operaciones y la organización del almacenamiento de archivos.
Utiliza GridFS si el tamaño de tu archivo excede el límite del tamaño del documento BSON de 16 MB. GridFS también te ayuda a acceder a archivos sin cargar el archivo completo en memoria. Para obtener información más detallada sobre si GridFS es adecuado para tu caso de uso, consulta la PáginaGridFS en el manual del servidor.
Para obtener más información sobre GridFS, navegue a las siguientes secciones de esta guía:
Cómo funciona GridFS
GridFS organiza los archivos en un bucket, que es un grupo de colecciones de MongoDB que contiene fragmentos de archivos e información descriptiva. Los cubos contienen las siguientes colecciones, nombradas de acuerdo con la convención definida en la especificación de GridFS:
chunksque almacena los fragmentos del archivo binariofiles, que almacena los metadatos del archivo
Cuando crea un nuevo depósito GridFS, el controlador Rust realiza las siguientes acciones:
Crea las colecciones
chunksyfiles, con el prefijo del nombre del bucket por defectofs, a menos que especifique un nombre diferenteCrea un índice en cada colección para garantizar la recuperación eficiente de archivos y metadatos relacionados
Puedes crear una referencia a un bucket GridFS siguiendo los pasos de la sección Referenciar un bucket GridFS de esta página. Sin embargo, el driver no crea un nuevo bucket GridFS y sus índices hasta que se realiza la primera operación de escritura. Para obtener más información sobre los índices de GridFS, consulta la página Índices de GridFS en el manual del servidor.
Al almacenar un archivo en un bucket de GridFS, el controlador de Rust crea los siguientes documentos:
Un documento en la colección
filesque almacena un ID de archivo único, un nombre de archivo y otros metadatos de archivoUno o más documentos en la colección
chunksque almacenan el contenido del archivo, que el driver divide en partes más pequeñas
El siguiente diagrama describe cómo GridFS divide los archivos al cargarlos a un bucket:

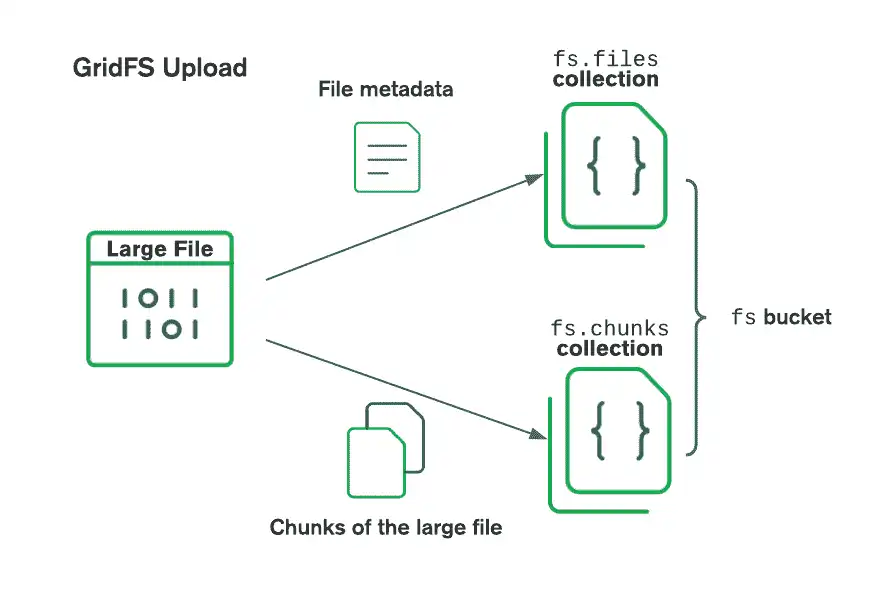
Al recuperar archivos, GridFS obtiene los metadatos de la colección files en el bucket especificado y usa la información para reconstruir el archivo a partir de documentos en la colección chunks. Puede leer el archivo en la memoria o enviarlo a una secuencia.
Referencia a un bucket GridFS
Antes de almacenar archivos en un bucket GridFS, cree una referencia o obtenga una referencia a un bucket existente.
El siguiente ejemplo llama al método gridfs_bucket() en una instancia de base de datos, que crea una referencia a un bucket GridFS nuevo o existente:
let bucket = my_db.gridfs_bucket(None);
Puede especificar un nombre de depósito personalizado configurando el campo bucket_name de la estructura GridFsBucketOptions.
Nota
Creando instancias de estructuras
El controlador de Rust implementa el patrón de diseño Builder para la creación de algunos tipos de struct, incluido GridFsBucketOptions. Puedes usar el método builder() para construir una instancia de cada tipo encadenando métodos de opción builder.
La siguiente tabla describe los métodos que puede utilizar para configurar los campos GridFsBucketOptions:
Método | Possible Values | Descripción |
|---|---|---|
bucket_name() | Any String value | Specifies a bucket name, which is set to fs by default |
| Cualquier valor | Especifica el tamaño de fragmento utilizado para dividir el archivo, que por defecto es de 255 KB |
write_concern() | WriteConcern::w(),WriteConcern::w_timeout(),WriteConcern::journal(),WriteConcern::majority() | Specifies the bucket's write concern, which is set to the database's write concern by default |
|
| Especifica la preocupación de lectura del depósito, que se establece en la preocupación de lectura de la base de datos de manera predeterminada |
selection_criteria() | SelectionCriteria::ReadPreference,SelectionCriteria::Predicate | Specifies which servers are suitable for a bucket operation, which is set to the database's selection criteria by default |
El siguiente ejemplo especifica opciones en una instancia GridFsBucketOptions para configurar un nombre de depósito personalizado y un límite de tiempo de cinco segundos para las operaciones de escritura:
let wc = WriteConcern::builder().w_timeout(Duration::new(5, 0)).build(); let opts = GridFsBucketOptions::builder() .bucket_name("my_bucket".to_string()) .write_concern(wc) .build(); let bucket_with_opts = my_db.gridfs_bucket(opts);
Cargar archivos
Puedes cargar un archivo en un bucket GridFS abriendo un flujo de carga y escribiendo tu archivo en el flujo. Llame el método open_upload_stream() en su instancia de bucket para abrir el flujo. Este método devuelve una instancia de GridFsUploadStream en la que puedes guardar el contenido del archivo. Para cargar el contenido del archivo en GridFsUploadStream, llama al método write_all() y pasa los bytes del archivo como parámetro.
Tip
Importar el módulo requerido
La estructura GridFsUploadStream implementa el atributo futures_io::AsyncWrite. Para usar los métodos de escritura AsyncWrite, como write_all(), importe el módulo AsyncWriteExt al archivo de su aplicación con la siguiente declaración de uso:
use futures_util::io::AsyncWriteExt;
El siguiente ejemplo utiliza un flujo de carga para cargar un archivo llamado "example.txt" a una cubeta de GridFS:
let bucket = my_db.gridfs_bucket(None); let file_bytes = fs::read("example.txt").await?; let mut upload_stream = bucket.open_upload_stream("example").await?; upload_stream.write_all(&file_bytes[..]).await?; println!("Document uploaded with ID: {}", upload_stream.id()); upload_stream.close().await?;
Descargar archivos
Puede descargar un archivo de un bucket de GridFS abriendo un flujo de descarga y leyendo desde él. Invoque el método open_download_stream() en la instancia del bucket, especificando el valor _id del archivo deseado como parámetro. Este método devuelve una instancia GridFsDownloadStream desde la que puede acceder al archivo. Para leer el archivo desde GridFsDownloadStream, invoque el método read_to_end() y pase un vector como parámetro.
Tip
Importar el módulo requerido
La estructura GridFsDownloadStream implementa la característica futures_io::AsyncRead. Para utilizar los métodos de lectura AsyncRead, como read_to_end(), importe el módulo AsyncReadExt a su archivo de aplicación con la siguiente declaración de uso:
use futures_util::io::AsyncReadExt;
El siguiente ejemplo utiliza un flujo de descarga para descargar un archivo con un valor _id de 3289 desde un depósito GridFS:
let bucket = my_db.gridfs_bucket(None); let id = ObjectId::from_str("3289").expect("Could not convert to ObjectId"); let mut buf = Vec::new(); let mut download_stream = bucket.open_download_stream(Bson::ObjectId(id)).await?; let result = download_stream.read_to_end(&mut buf).await?; println!("{:?}", result);
Nota
La API de streaming de GridFS no puede cargar fragmentos parciales. Cuando un flujo de descarga necesita extraer un fragmento de MongoDB, lo extrae completo a memoria. El tamaño predeterminado de fragmento de 255 KB suele ser suficiente, pero se puede reducir para reducir la sobrecarga de memoria.
Recuperar información de archivos
Puede recuperar información sobre los archivos almacenados en la colección files del bucket GridFS. Cada archivo se almacena como una instancia del tipo FilesCollectionDocument, que incluye los siguientes campos que representan información del archivo:
_id: el ID del archivolength: el tamaño del archivochunk_size_bytes: el tamaño de los fragmentos del archivoupload_date: la fecha y hora de carga del archivofilename: el nombre del archivometadata: un documento que almacena metadatos especificados por el usuario
Llama al método find() en una instancia de un bucket de GridFS para recuperar archivos del bucket. El método devuelve una instancia de cursor desde la cual puedes acceder a los resultados.
El siguiente ejemplo recupera e imprime la longitud de cada archivo en un depósito GridFS:
let bucket = my_db.gridfs_bucket(None); let filter = doc! {}; let mut cursor = bucket.find(filter).await?; while let Some(result) = cursor.try_next().await? { println!("File length: {}\n", result.length); };
Tip
Para obtener más información sobre el método find(), consulte la Guía para recuperar datos. Para obtener más información sobre cómo recuperar datos desde un cursor, consulta la guía Acceso a datos usando un cursor.
Renombrar archivos
Puedes actualizar el nombre de un archivo GridFS en tu bucket llamando al método rename() en una instancia del bucket. Transfiera el valor de _id del archivo de destino y el nuevo nombre del archivo como parámetros al método rename().
Nota
El método rename() solo permite actualizar el nombre de un archivo a la vez. Para renombrar varios archivos, recupere del depósito una lista de archivos que coincidan con el nombre, extraiga el campo _id de los archivos que desea renombrar y pase cada valor en llamadas separadas al método rename().
El siguiente ejemplo actualiza el campo filename del archivo que contiene un valor _id de 3289 a "new_file_name":
let bucket = my_db.gridfs_bucket(None); let id = ObjectId::from_str("3289").expect("Could not convert to ObjectId"); let new_name = "new_file_name"; bucket.rename(Bson::ObjectId(id), new_name).await?;
Borrar archivos
Puedes usar el método delete() para remover un archivo de tu bucket. Para remover un archivo, llama a delete() en tu instancia de bucket y pasa el valor del _id del archivo como parámetro.
Nota
El método delete() solo permite eliminar un archivo a la vez. Para eliminar varios, recupere los archivos del depósito, extraiga el campo _id de los archivos que desea eliminar y pase cada valor _id en llamadas separadas al método delete().
El siguiente ejemplo elimina el archivo en el que el valor del campo _id es 3289:
let bucket = my_db.gridfs_bucket(None); let id = ObjectId::from_str("3289").expect("Could not convert to ObjectId"); bucket.delete(Bson::ObjectId(id)).await?;
Borrar un bucket de GridFS
Puedes usar el método drop() para eliminar un bucket, lo que elimina las colecciones files y chunks. Para eliminar el bucket, llama a drop() en la instancia del bucket.
El siguiente ejemplo elimina un bucket de GridFS:
let bucket = my_db.gridfs_bucket(None); bucket.drop().await?;
Información Adicional
Documentación de la API
Para obtener más información sobre cualquiera de los métodos o tipos mencionados en esta guía, consulta la siguiente documentación API: