Overview
En esta guía, puedes aprender cómo almacenar y recuperar archivos grandes en MongoDB utilizando GridFS. GridFS es una especificación que describe cómo dividir archivos en fragmentos durante el almacenamiento y volver a ensamblarlos durante la recuperación. La implementación del controlador de GridFS gestiona las operaciones y la organización del almacenamiento de archivos.
Utilice GridFS si el tamaño de su archivo supera el límite de tamaño del documento BSON de 16 megabytes. Para obtener información más detallada sobre si GridFS es adecuado para su caso de uso, consulte la Página del manual del servidor de GridFS.
Navegue por las siguientes secciones para obtener más información sobre las operaciones de GridFS y su implementación:
Cómo funciona GridFS
GridFS organiza los archivos en un bucket, un grupo de colecciones de MongoDB que contienen los fragmentos de los archivos y la información descriptiva. Los buckets contienen las siguientes colecciones, denominadas según la convención definida en la especificación de GridFS:
La
chunksla colección almacena los fragmentos de archivos binarios.La colección
filesalmacena los metadatos del archivo.
Cuando creas un nuevo bucket de GridFS, el controlador crea las colecciones chunks y files, precedidas por el nombre de bucket por defecto fs, a menos que especifiques otro nombre. El controlador también crea un índice en cada colección para garantizar la recuperación eficiente de archivos y metadatos relacionados. El controlador solo crea el bucket GridFS en la primera operación de escritura si aún no existe. El controlador solo crea índices si no existen y cuando el bucket está vacío. Para más información sobre los índices de GridFS, consulte la página del manual del Servidor sobre Índices de GridFS.
Al almacenar archivos con GridFS, el controlador divide los archivos en fragmentos más pequeños, cada uno representado por un documento independiente en la colección chunks. También crea un documento en la colección files que contiene un ID de archivo único, un nombre de archivo y otros metadatos. Puede cargar el archivo desde la memoria o desde un flujo. El siguiente diagrama describe cómo GridFS divide los archivos al subirlos a un bucket:

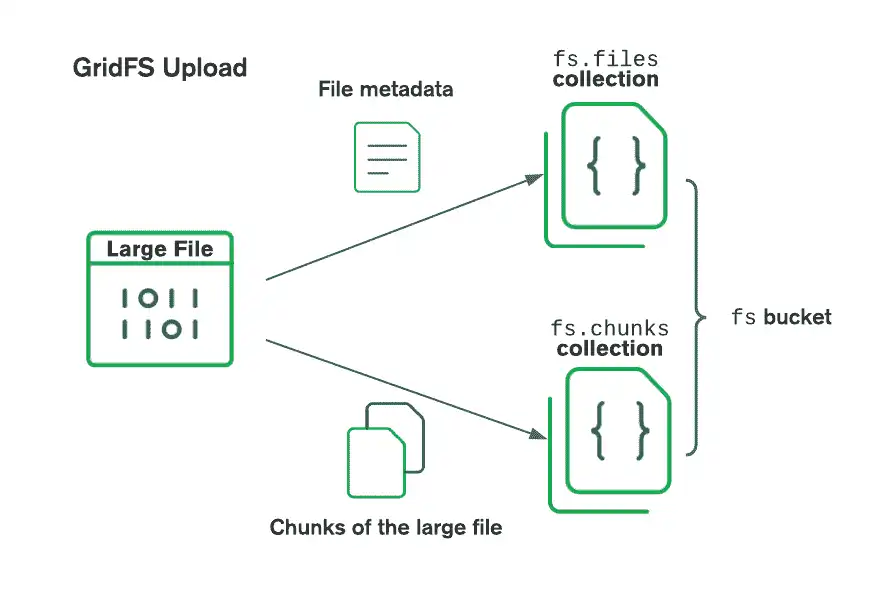
Al recuperar archivos, GridFS obtiene los metadatos de la colección files en el bucket especificado y usa la información para reconstruir el archivo a partir de documentos en la colección chunks. Puede leer el archivo en la memoria o enviarlo a una secuencia.
Crear un bucket de GridFS
Cree un bucket u obtenga una referencia a uno existente para comenzar a almacenar o recuperar archivos de GridFS. Cree una instancia de GridFSBucket, pasando una base de datos como parámetro. A continuación, puede utilizar la instancia de GridFSBucket para llamar a las operaciones de lectura y escritura en los archivos de su bucket:
const db = client.db(dbName); const bucket = new mongodb.GridFSBucket(db);
Pasa el nombre de tu bucket como segundo parámetro al método create() para crear o referenciar un bucket con un nombre personalizado distinto al nombre por defecto fs, como se muestra en el siguiente ejemplo:
const bucket = new mongodb.GridFSBucket(db, { bucketName: 'myCustomBucket' });
Para obtener más información, consulte la documentación de la API de GridFSBucket.
Cargar archivos
Utiliza el método openUploadStream() de GridFSBucket para crear un flujo de carga para un nombre de archivo dado. Puedes utilizar el método pipe() para conectar un flujo de lectura nodo.js al flujo de carga. El método openUploadStream() permite especificar información de configuración, como el tamaño de los fragmentos de archivos y otros pares campo/valor para almacenarlos como metadatos.
El siguiente ejemplo muestra cómo hacer un pipe de un flujo de lectura de Node.js, representado por la variable fs, al método openUploadStream() de una instancia GridFSBucket:
fs.createReadStream('./myFile'). pipe(bucket.openUploadStream('myFile', { chunkSizeBytes: 1048576, metadata: { field: 'myField', value: 'myValue' } }));
Consulte la documentación de la API openUploadStream() para obtener más información.
Recuperar información de archivos
En esta sección, puedes aprender a recuperar metadatos de archivos almacenados en la colección files del depósito de GridFS. Los metadatos contienen información sobre el archivo al que se refieren, incluyendo:
El
_iddel archivoEl nombre del archivo
La longitud/tamaño del archivo
La fecha y hora de carga
Un documento
metadataen el que puedes almacenar cualquier otra información
Llama al método find() en la instancia GridFSBucket para recuperar archivos de un bucket de GridFS. El método devuelve una instancia FindCursor desde la que puedes acceder a los resultados.
El siguiente ejemplo de código muestra cómo recuperar e imprimir metadatos de todos los archivos de un bucket de GridFS. Entre las diferentes maneras de recorrer los resultados recuperados del iterable FindCursor, el siguiente ejemplo utiliza la sintaxis for await...of para mostrarlos:
const cursor = bucket.find({}); for await (const doc of cursor) { console.log(doc); }
El método find() acepta varias especificaciones de consulta y se puede combinar con otros métodos como sort(), limit() y project().
Para obtener más información sobre las clases y métodos mencionados en esta sección, consulta los siguientes recursos:
Descargar archivos
Puedes descargar archivos de tu base de datos MongoDB utilizando el método openDownloadStreamByName() de GridFSBucket para crear una secuencia de descarga.
El siguiente ejemplo muestra cómo descargar un archivo referenciado por nombre de archivo, almacenado en el campo filename, a tu directorio de trabajo:
bucket.openDownloadStreamByName('myFile'). pipe(fs.createWriteStream('./outputFile'));
Nota
Si hay varios documentos con el mismo valor filename, GridFS transmitirá el archivo más reciente con el nombre dado (según lo determinado por el campo uploadDate).
Alternativamente, puedes usar el método openDownloadStream(), que toma el campo _id de un archivo como parámetro:
bucket.openDownloadStream(ObjectId("60edece5e06275bf0463aaf3")). pipe(fs.createWriteStream('./outputFile'));
Nota
La API de transmisión de GridFS no puede cargar fragmentos parciales. Cuando una secuencia de descarga necesita obtener un fragmento de MongoDB, lo carga completo en la memoria. El tamaño de fragmento por defecto de 255 kilobytes suele ser suficiente, pero se puede reducir el tamaño de fragmento para disminuir la sobrecarga de memoria.
Para más información sobre el método openDownloadStreamByName(), consulte su documentación de API.
Renombrar archivos
Utiliza el método rename() para actualizar el nombre de un archivo GridFS en su bucket. Debes especificar el archivo que deseas renombrar por su campo _id en lugar de su nombre de archivo.
Nota
El método rename() solo permite actualizar el nombre de un archivo a la vez. Para renombrar varios archivos, recupere del depósito una lista de archivos que coincidan con el nombre, extraiga el campo _id de los archivos que desea renombrar y pase cada valor en llamadas separadas al método rename().
El siguiente ejemplo muestra cómo actualizar el campo filename a "newFileName" haciendo referencia al campo _id de un documento:
bucket.rename(ObjectId("60edece5e06275bf0463aaf3"), "newFileName");
Para obtener más información sobre este método, consulte la rename() documentación de la API.
Borrar archivos
Utiliza el método delete() para remover un archivo de tu bucket. Debe especificar el archivo por su campo _id en lugar de por su nombre de archivo.
Nota
El método delete() solo soporta borrar un archivo por vez. Para borrar varios archivos, recupera los archivos del bucket, extrae el campo _id de los archivos que desea borrar y pasa cada valor en llamadas separadas al método delete().
El siguiente ejemplo le muestra cómo borrar un archivo haciendo referencia a su campo _id:
bucket.delete(ObjectId("60edece5e06275bf0463aaf3"));
Para más información sobre este método, consulta la documentación de la API borrar().
Borrar un bucket de GridFS
Utilice el método drop() para eliminar las colecciones files y chunks de un bucket, lo que elimina el bucket. El siguiente ejemplo de código muestra cómo eliminar un bucket de GridFS:
bucket.drop();
Para obtener más información sobre este método, consulte la documentación de la API drop().