Overview
En esta guía, puedes aprender cómo almacenar y recuperar archivos grandes en MongoDB utilizando GridFS. GridFS es una especificación implementada por el driver de Java que describe cómo dividir los archivos en fragmentos al almacenarlos y cómo volver a ensamblarlos al recuperarlos. La implementación del driver de GridFS es una abstracción que gestiona las operaciones y la organización del almacenamiento de archivos en tu aplicación Java.
Utilice GridFS si el tamaño de sus archivos supera el límite de tamaño de documento BSON de 16MB. Para saber si GridFS es adecuado para su caso de uso, consulte la Referencia de GridFS en el manual de MongoDB Server.
Las siguientes secciones describen las operaciones de GridFS y demuestran cómo realizar estas acciones con el driver:
Tip
Configuración de Tiempo de Espera
Puede usar la configuración de tiempo de espera de operación del lado del cliente (CSOT) para limitar el tiempo que el servidor tarda en finalizar las operaciones de GridFS. Para obtener más información sobre el uso de esta configuración con GridFS, consulte SecciónGridFS de la guía Limitar el tiempo de ejecución del servidor.
Cómo funciona GridFS
GridFS organiza los archivos en un bucket, un grupo de colecciones de MongoDB que contienen los fragmentos de archivos e información que los describe. El bucket contiene las siguientes colecciones, nombradas según la convención definida en la especificación GridFS:
La
chunksla colección almacena los fragmentos de archivos binarios.La colección
filesalmacena los metadatos del archivo.
Cuando creas un nuevo bucket de GridFS, el driver crea las colecciones anteriores, anteponiendo el nombre de bucket por defecto fs, a menos que especifiques un nombre diferente. El controlador también crea un índice en cada colección para garantizar una recuperación eficiente de los archivos y los metadatos relacionados. El controlador solo crea el bucket GridFS en la primera operación de escritura si aún no existe. El controlador solo crea índices si no existen y cuando el bucket está vacío. Para obtener más información sobre los índices de GridFS, consulte la página del manual del servidor en Índices de GridFS.
Al almacenar archivos con GridFS, el driver divide los archivos en fragmentos más pequeños, cada uno representada por un documento independiente en la colección chunks. También crea un documento en la colección files que contiene un id de archivo, nombre de archivo y otros metadatos del archivo. Puedes subir el archivo desde la memoria o desde un flujo de datos. Consulte el siguiente diagrama para ver cómo GridFS divide los archivos al cargarlos en un bucket.

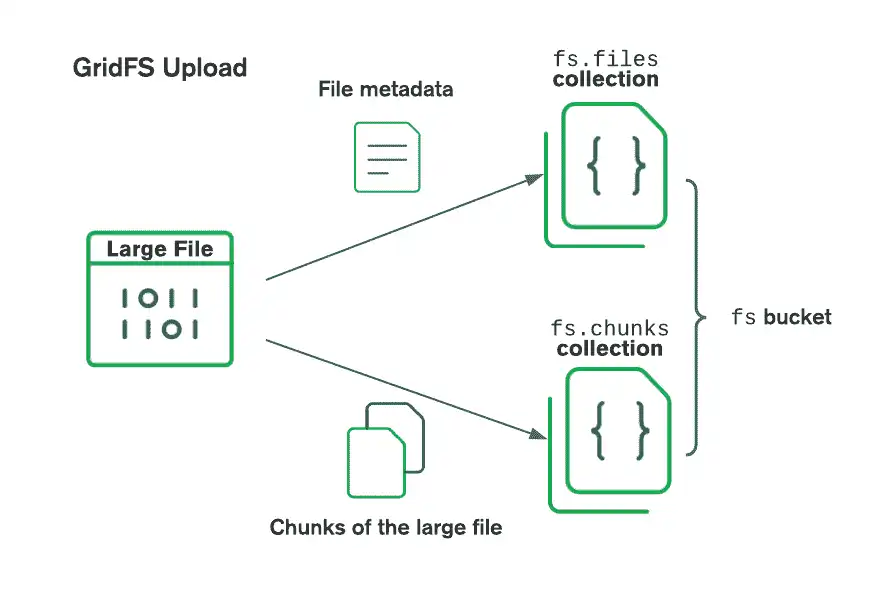
Al recuperar archivos, GridFS obtiene los metadatos de la colección files en el bucket especificado y usa la información para reconstruir el archivo a partir de documentos en la colección chunks. Puede leer el archivo en la memoria o enviarlo a una secuencia.
Crear un bucket de GridFS
Para almacenar o recuperar archivos de GridFS, crea un bucket o consigue una referencia a uno existente en una base de datos MongoDB. Llama al método asistente GridFSBuckets.create() con una instancia de MongoDatabase como parámetro para crear una instancia de GridFSBucket. Puedes usar la instancia GridFSBucket para llamar a operaciones de lectura y guardado en los archivos de tu bucket.
MongoDatabase database = mongoClient.getDatabase("mydb"); GridFSBucket gridFSBucket = GridFSBuckets.create(database);
Para crear o hacer referencia a un bucket con un nombre personalizado diferente al nombre por defecto fs, pasa tu nombre de bucket como segundo parámetro al método create() como se muestra a continuación:
GridFSBucket gridFSBucket = GridFSBuckets.create(database, "myCustomBucket");
Nota
Cuando llames a create(), MongoDB no crea el bucket si no existe. En su lugar, MongoDB crea el bucket si es necesario, como cuando cargas tu primer archivo.
Para obtener más información sobre las clases y métodos mencionados en esta sección, consulta la siguiente documentación de la API:
Almacenar archivos
Para almacenar un archivo en un bucket de GridFS, puedes subirlo desde una instancia de InputStream o escribir sus datos en un GridFSUploadStream.
Para cualquiera de los procesos de subida, puedes especificar información de configuración, como el tamaño de fragmentos del archivo y otros pares campo/valor para almacenar como metadatos. Configure esta información en una instancia de GridFSUploadOptions como se muestra en el siguiente snippet:
GridFSUploadOptions options = new GridFSUploadOptions() .chunkSizeBytes(1048576) // 1MB chunk size .metadata(new Document("myField", "myValue"));
Consulta la GridFSUploadOptions Documentación de la API para más información.
Importante
Utilizar un nivel de confirmación de escritura (write concern) de mayoría
Al almacenar archivos en un bucket de GridFS, asegúrese de usar la preocupación de escritura WriteConcern.MAJORITY. Si especifica una preocupación de escritura diferente, las elecciones del conjunto de réplicas que se producen durante la carga de un archivo de GridFS podrían interrumpir el proceso y provocar la pérdida de algunos fragmentos de archivo.
Para obtener más información sobre los niveles de confirmación de escritura (write concerns), consulta la página Nivel de confirmación de escritura (Write Concern) en el manual del servidor.
Subir un archivo utilizando un flujo de entrada
Esta sección te muestra cómo subir un archivo a un bucket de GridFS usando un flujo de entrada. El siguiente ejemplo de código muestra cómo se puede usar un FileInputStream para leer datos de un archivo en el sistema de archivos y cargarlos en GridFS realizando las siguientes operaciones:
Leer desde el sistema de archivos utilizando un
FileInputStream.Establece el tamaño de los fragmentos usando
GridFSUploadOptions.Configure un campo de metadatos personalizado denominado
typecon el valor "fichero zip".Carga un archivo llamado
project.zip, especificando el nombre del archivo GridFS como "myProject.zip".
String filePath = "/path/to/project.zip"; try (InputStream streamToUploadFrom = new FileInputStream(filePath) ) { // Defines options that specify configuration information for files uploaded to the bucket GridFSUploadOptions options = new GridFSUploadOptions() .chunkSizeBytes(1048576) .metadata(new Document("type", "zip archive")); // Uploads a file from an input stream to the GridFS bucket ObjectId fileId = gridFSBucket.uploadFromStream("myProject.zip", streamToUploadFrom, options); // Prints the "_id" value of the uploaded file System.out.println("The file id of the uploaded file is: " + fileId.toHexString()); }
Este ejemplo de código imprime el id del archivo subido una vez que se guarda con éxito en GridFS.
Para más información, consulta la Documentación de la API en uploadFromStream().
Cargar un archivo usando un flujo de salida
Esta sección muestra cómo subir un archivo a un bucket de GridFS escribiendo en un flujo de salida. El siguiente ejemplo de código muestra cómo escribir en un GridFSUploadStream para enviar datos a GridFS mediante las siguientes operaciones:
Lee un archivo llamado "project.zip" desde el sistema de archivos a una matriz de bytes.
Establece el tamaño de los fragmentos usando
GridFSUploadOptions.Configure un campo de metadatos personalizado denominado
typecon el valor "fichero zip".Escribe los bytes en un
GridFSUploadStreamy asigna el nombre de archivo "myProject.zip". El flujo lee los datos en un búfer hasta alcanzar el límite especificado en la configuraciónchunkSizey los inserta como un nuevo fragmento en la colecciónchunks.
Path filePath = Paths.get("/path/to/project.zip"); byte[] data = Files.readAllBytes(filePath); // Defines options that specify configuration information for files uploaded to the bucket GridFSUploadOptions options = new GridFSUploadOptions() .chunkSizeBytes(1048576) .metadata(new Document("type", "zip archive")); try (GridFSUploadStream uploadStream = gridFSBucket.openUploadStream("myProject.zip", options)) { // Writes file data to the GridFS upload stream uploadStream.write(data); uploadStream.flush(); // Prints the "_id" value of the uploaded file System.out.println("The file id of the uploaded file is: " + uploadStream.getObjectId().toHexString()); // Prints a message if any exceptions occur during the upload process } catch (Exception e) { System.err.println("The file upload failed: " + e); }
Este ejemplo de código imprime el id del archivo subido una vez que se guarda con éxito en GridFS.
Nota
Si la carga de tu archivo no es exitosa, la operación genera una excepción y cualquier fragmento cargado se convierte en un fragmento huérfano. Un fragmento huérfano es un documento en una colección de GridFS chunks que no hace referencia a ningún ID de archivo en la colección de GridFS files. Los fragmentos de archivo pueden volverse fragmentos huérfanos cuando una operación de carga o eliminación se interrumpe. Para remover fragmentos huérfanos, primero debes identificarlos mediante operaciones de lectura y luego guardarlos mediante operaciones de escritura.
Para obtener más información, consulte la Documentación de la API en GridFSUploadStream.
Recuperar información de archivos
En esta sección, puedes aprender a recuperar metadatos de archivos almacenados en la colección files del depósito de GridFS. Los metadatos contienen información sobre el archivo al que se refieren, incluyendo:
El id del archivo
El nombre del archivo
La longitud/tamaño del archivo
La fecha y hora de carga
Un documento
metadataen el que puedes almacenar cualquier otra información
Para recuperar archivos de un bucket de GridFS, llama al método find() en la instancia GridFSBucket. El método devuelve un GridFSFindIterable desde el que puedes acceder a los resultados.
El siguiente ejemplo de código muestra cómo recuperar e imprimir metadatos de archivos de todos tus archivos en un contenedor de GridFS. Entre las diferentes formas en las que puedes recorrer los resultados recuperados del GridFSFindIterable, el ejemplo utiliza una interfaz funcional Consumer para imprimir los siguientes resultados:
gridFSBucket.find().forEach(new Consumer<GridFSFile>() { public void accept(final GridFSFile gridFSFile) { System.out.println(gridFSFile); } });
El siguiente ejemplo de código muestra cómo recuperar e imprimir los nombres de todos los archivos que coinciden con los campos especificados en el filtro de consulta. El ejemplo también invoca sort() y limit() en el valor GridFSFindIterable devuelto para especificar el orden y el número máximo de resultados:
Bson query = Filters.eq("metadata.type", "zip archive"); Bson sort = Sorts.ascending("filename"); // Retrieves 5 documents in the bucket that match the filter and prints metadata gridFSBucket.find(query) .sort(sort) .limit(5) .forEach(new Consumer<GridFSFile>() { public void accept(final GridFSFile gridFSFile) { System.out.println(gridFSFile); } });
Dado que metadata es un documento incrustado, el filtro de query especifica el campo type dentro del documento utilizando la notación de puntos. Consulta la guía del manual del servidor sobre cómo Query sobre documentos incrustados/anidados para más información.
Para obtener más información sobre las clases y métodos mencionados en esta sección, consulte los siguientes recursos:
Documentación de la API deGridFSFindIterable
GridFSBucket.find() Documentación de API
Descargar archivos
Puedes descargar un archivo directamente desde GridFS a un flujo, o puedes guardarlo en la memoria desde un flujo. Puedes especificar el archivo a recuperar utilizando ya sea el id del archivo o el nombre del archivo.
Revisiones de archivos
Cuando tu bucket contiene varios archivos que comparten el mismo nombre, GridFS elige por defecto la versión más reciente del archivo. Para diferenciar entre cada archivo que comparte el mismo nombre, GridFS asigna a los archivos que comparten el mismo nombre de archivo un número de revisión, ordenado por tiempo de carga.
El número de revisión del archivo original es "0" y el siguiente número de revisión más reciente es "1". También puede especificar valores negativos que corresponden a la fecha de la revisión. El valor de revisión "-1" hace referencia a la revisión más reciente y "-2" a la siguiente.
El siguiente snippet de código muestra cómo puedes especificar la segunda revisión de un archivo en una instancia de GridFSDownloadOptions:
GridFSDownloadOptions downloadOptions = new GridFSDownloadOptions().revision(1);
Para obtener más información sobre la enumeración de revisiones, consulta la documentación de la API para GridFSDownloadOptions.
Descargar un archivo a un flujo de salida
Puedes descargar un archivo de un bucket de GridFS a un flujo de salida. El siguiente ejemplo de código muestra cómo llamar al método downloadToStream() para descargar la primera revisión del archivo "myProject.zip" a un OutputStream.
GridFSDownloadOptions downloadOptions = new GridFSDownloadOptions().revision(0); // Downloads a file to an output stream try (FileOutputStream streamToDownloadTo = new FileOutputStream("/tmp/myProject.zip")) { gridFSBucket.downloadToStream("myProject.zip", streamToDownloadTo, downloadOptions); streamToDownloadTo.flush(); }
Para obtener más información sobre este método, consulte la downloadToStream() Documentación de la API.
Descargar un archivo en un flujo de entrada
Puedes descargar un archivo en un bucket de GridFS a la memoria utilizando un flujo de entrada. Puedes llamar al método openDownloadStream() en el contenedor GridFS para abrir un GridFSDownloadStream, un flujo de entrada desde el que puedes leer el archivo.
En el siguiente ejemplo de código se muestra cómo descargar un archivo referenciado por la variable fileId en memoria e imprimir su contenido como una cadena:
ObjectId fileId = new ObjectId("60345d38ebfcf47030e81cc9"); // Opens an input stream to read a file containing a specified "_id" value and downloads the file try (GridFSDownloadStream downloadStream = gridFSBucket.openDownloadStream(fileId)) { int fileLength = (int) downloadStream.getGridFSFile().getLength(); byte[] bytesToWriteTo = new byte[fileLength]; downloadStream.read(bytesToWriteTo); // Prints the downloaded file's contents as a string System.out.println(new String(bytesToWriteTo, StandardCharsets.UTF_8)); }
Para más información sobre este método, consulte la función openDownloadStream(). Documentación de la API.
Renombrar archivos
Puedes actualizar el nombre de un archivo GridFS en tu bucket llamando al método rename(). Debes especificar el archivo a renombrar por su id de archivo en lugar de su nombre.
Nota
El método rename() solo admite la actualización del nombre de un archivo a la vez. Para renombrar varios archivos, recupere una lista de archivos que coincidan con el nombre del archivo del bucket, extraiga los valores de id de archivo de los archivos que desea renombrar y pase cada id de archivo en llamadas separadas al método rename().
El siguiente ejemplo de código muestra cómo actualizar el nombre del archivo al que hace referencia la variable fileId a "mongodbTutorial.zip":
ObjectId fileId = new ObjectId("60345d38ebfcf47030e81cc9"); // Renames the file that has a specified "_id" value to "mongodbTutorial.zip" gridFSBucket.rename(fileId, "mongodbTutorial.zip");
Para obtener más información sobre este método, consulte la documentación de la API rename().
Borrar archivos
Puedes remover un archivo de tu bucket GridFS llamando al método delete(). Debes especificar el archivo por su ID de archivo, no por su nombre de archivo.
Nota
El método delete() solo soporta borrar un archivo por vez. Para borrar varios archivos, recupere los archivos del bucket, extraiga los valores de ID de archivo de los archivos que desea borrar y pase cada ID de archivo en llamadas separadas al método delete().
El siguiente ejemplo de código le muestra cómo eliminar el archivo al que hace referencia la variable fileId:
ObjectId fileId = new ObjectId("60345d38ebfcf47030e81cc9"); // Deletes the file that has a specified "_id" value from the GridFS bucket gridFSBucket.delete(fileId);
Para obtener más información sobre este método, consulta la borrar() Documentación de API.
Borrar un bucket de GridFS
El siguiente ejemplo de código muestra cómo eliminar el bucket GridFS predeterminado en la base de datos llamada "mydb". Para hacer referencia a un bucket con nombre personalizado, consulta la sección de esta guía sobre cómo crear un bucket personalizado.
MongoDatabase database = mongoClient.getDatabase("mydb"); GridFSBucket gridFSBucket = GridFSBuckets.create(database); gridFSBucket.drop();
Para obtener más información sobre este método, consulte la documentación de la API drop().
Información Adicional
Archivo ejecutable GridFSTour.java del repositorio de origen del driver