Overview
En esta guía, puedes aprender cómo almacenar y recuperar archivos grandes en MongoDB utilizando la especificación GridFS. GridFS divide los archivos grandes en fragmentos y almacena cada fragmento como un documento separado. Cuando usted query GridFS por un archivo, el driver ensambla los fragmentos según sea necesario. La implementación del driver de GridFS es una abstracción que gestiona las operaciones y la organización del almacenamiento de archivos.
Utilice GridFS si el tamaño de sus archivos supera el límite de tamaño de documento BSON de 16 MB. GridFS también le permite acceder a los archivos sin cargarlos completamente en la memoria. Para saber si GridFS es adecuado para su caso de uso, consulte GridFS en el manual del servidor.
Cómo funciona GridFS
GridFS organiza los archivos en un bucket, un grupo de colecciones de MongoDB que contienen los fragmentos de archivos e información que los describe. El bucket contiene las siguientes colecciones:
chunksque almacena los fragmentos del archivo binariofiles, que almacena los metadatos del archivo
Cuando creas un nuevo bucket GridFS, el driver crea las colecciones anteriores. El nombre de bucket por defecto fs antepone los nombres de las colecciones, a menos que se especifique un nombre de bucket diferente. El driver crea el nuevo contenedor GridFS durante la primera operación de guardar.
El controlador también crea un índice en cada colección para garantizar la recuperación eficiente de los archivos y metadatos relacionados. El controlador crea índices si no existen y cuando el contenedor está vacío. Para obtener más información sobre los índices de GridFS, consulte Índices de GridFS en el manual del servidor.
Al almacenar archivos con GridFS, el controlador divide los archivos en fragmentos más pequeños, cada uno representado por un documento independiente en la colección chunks. También crea un documento en la colección files que contiene el ID, el nombre y otros metadatos del archivo. El siguiente diagrama muestra cómo GridFS divide los archivos cargados:

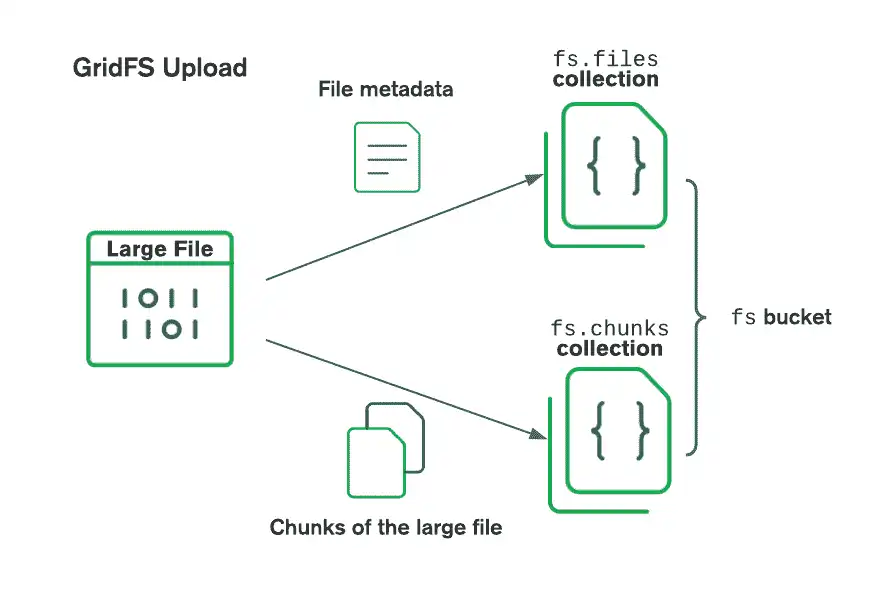
Al recuperar archivos, GridFS obtiene los metadatos de la colección files en el depósito especificado y luego utiliza esa información para reconstruir el archivo a partir de los documentos de la colección chunks. Puede leer el archivo en memoria o exportarlo a una secuencia.
Operaciones GridFS
Las siguientes secciones describen cómo realizar operaciones GridFS:
Crear un bucket de GridFS
Para almacenar o recuperar archivos de GridFS, crea un bucket de almacenamiento o consigue una referencia a un bucket de almacenamiento existente en una base de datos MongoDB. Para crear una instancia de GridFSBucket, llama al método GridFSBucket() en una instancia de Database, como se muestra en el siguiente código:
db := client.Database("myDB") bucket := db.GridFSBucket()
Nota
Si ya existe un depósito GridFS, el método GridFSBucket() devuelve una referencia al depósito en lugar de crear una instancia nueva.
De forma predeterminada, el controlador asigna el nombre del bucket a fs. Para crear un bucket con un nombre personalizado, llame al método SetName() en una instancia BucketOptions, como se muestra en el siguiente código:
db := client.Database("myDB") bucketOpts := options.GridFSBucket().SetName("myCustomBucket") bucket := db.GridFSBucket(bucketOpts)
Cargar archivos
Puede cargar un archivo a un bucket de GridFS utilizando uno de los siguientes métodos:
UploadFromStream()que se lee desde un flujo de entradaOpenUploadStream(), que escribe en un flujo de salida
Para cualquiera de los procesos de carga, puedes especificar información de configuración creando una instancia UploadOptions. Para ver una lista completa de opciones, consulta la documentación de la API de opciones de carga.
Subir con un flujo de entrada
Para cargar un archivo con un flujo de entrada, utilice el método UploadFromStream() e incluya los siguientes parámetros:
Nombre de archivo
io.Readerinstancia, incluyendo tu archivo abierto como parámetrooptsparámetro para modificar el comportamiento deUploadFromStream()
El siguiente ejemplo de código lee de un archivo llamado file.txt, crea un parámetro opts para establecer los metadatos del archivo y carga el contenido en un bucket de GridFS:
file, err := os.Open("home/documents/file.txt") uploadOpts := options.GridFSUpload().SetMetadata(bson.D{{"metadata tag", "first"}}) objectID, err := bucket .UploadFromStream( "file.txt", io.Reader(file), uploadOpts ) if err != nil { panic(err) } fmt.Printf("New file uploaded with ID %s", objectID)
New file uploaded with ID ...
Subir con un flujo de salida
Para cargar un archivo con un flujo de salida, utilice el método OpenUploadStream() e incluya los siguientes parámetros:
Nombre de archivo
optsparámetro para modificar el comportamiento deOpenUploadStream()
El siguiente ejemplo de código abre un flujo de carga en un bucket de GridFS y configura la cantidad de bytes en cada fragmento en el parámetro de opciones. A continuación, llama al método Write() en el contenido de file.txt para guardar su contenido en la transmisión:
file, err := os.Open("home/documents/file.txt") if err != nil { panic(err) } // Defines options that specify configuration information for files // uploaded to the bucket uploadOpts := options.GridFSUpload().SetChunkSizeBytes(200000) // Writes a file to an output stream uploadStream, err := bucket.OpenUploadStream("file.txt", uploadOpts) if err != nil { panic(err) } fileContent, err := io.ReadAll(file) if err != nil { panic(err) } var bytes int if bytes, err = uploadStream.Write(fileContent); err != nil { panic(err) } fmt.Printf("New file uploaded with %d bytes written", bytes) // Calls the Close() method to write file metadata if err := uploadStream.Close(); err != nil { panic(err) }
Recuperar información de archivos
Puede recuperar los metadatos de archivos almacenados en la colección files del bucket GridFS. Cada documento de la colección files contiene la siguiente información:
ID de archivo
Longitud del archivo
Tamaño máximo de fragmento
Fecha y hora de carga
Nombre de archivo
metadatadocumento que almacena cualquier otra información
Para recuperar datos de archivo, llame al método Find() en una instancia GridFSBucket. Puede pasar un filtro de consulta como argumento a Find() para que coincida solo con ciertos documentos de archivo.
Nota
Debes pasar un filtro de query al método Find(). Para recuperar todos los documentos en la colección files, pasa un filtro de query vacío a Find().
El siguiente ejemplo recupera el nombre y el tamaño del archivo de documentos en los que el valor length es mayor que 1500:
filter := bson.D{{"length", bson.D{{"$gt", 1500}}}} cursor, err := bucket.Find(filter) if err != nil { panic(err) } type gridFSFile struct { Name string `bson:"filename"` Length int64 `bson:"length"` } var foundFiles []gridFSFile if err = cursor.All(context.TODO(), &foundFiles); err != nil { panic(err) } for _, file := range foundFiles { fmt.Printf("filename: %s, length: %d\n", file.Name, file.Length) }
Descargar archivos
Puede descargar un archivo GridFS utilizando uno de los siguientes métodos:
DownloadToStream(), que descarga un archivo en un flujo de salidaOpenDownloadStream(), que abre un flujo de entrada
Descargar un archivo a un flujo de salida
Puedes descargar un archivo en un bucket GridFS directamente a un flujo de salida utilizando el método DownloadToStream(). El método DownloadToStream() toma un ID de archivo y una instancia io.Writer como parámetros. El método descarga el archivo con el ID de archivo especificado y lo escribe en la instancia io.Writer.
El siguiente ejemplo descarga un archivo y guarda en un búfer de archivos:
id, err := bson.ObjectIDFromHex("62f7bd54a6e4452da13b3e88") fileBuffer := bytes.NewBuffer(nil) if _, err := bucket.DownloadToStream(id, fileBuffer); err != nil { panic(err) }
Descargar un archivo en un flujo de entrada
Puedes descargar un archivo de un bucket GridFS a la memoria usando un flujo de entrada mediante el método OpenDownloadStream(). El método OpenDownloadStream() toma un ID de archivo como parámetro y retorna un flujo de entrada desde el cual se puede leer el archivo.
El siguiente ejemplo descarga un archivo en la memoria y lee su contenido:
id, err := bson.ObjectIDFromHex("62f7bd54a6e4452da13b3e88") downloadStream, err := bucket.OpenDownloadStream(id) if err != nil { panic(err) } fileBytes := make([]byte, 1024) if _, err := downloadStream.Read(fileBytes); err != nil { panic(err) }
Renombrar archivos
Puedes actualizar el nombre de un archivo de GridFS en tu bucket usando el método Rename(). Pasa un valor de ID de archivo y un nuevo valor de filename como argumentos a Rename().
El siguiente ejemplo renombra un archivo a "mongodbTutorial.zip":
id, err := bson.ObjectIDFromHex("62f7bd54a6e4452da13b3e88") if err := bucket.Rename(id, "mongodbTutorial.zip"); err != nil { panic(err) }
Borrar archivos
Puedes remover un archivo de tu bucket de GridFS usando el método Delete(). Pase un valor de ID de archivo como argumento a Delete().
El siguiente ejemplo elimina un archivo:
id, err := bson.ObjectIDFromHex("62f7bd54a6e4452da13b3e88") if err := bucket.Delete(id); err != nil { panic(err) }
Borrar un bucket de GridFS
Puede borrar un bucket GridFS utilizando el método Drop().
El siguiente ejemplo de código elimina un depósito GridFS:
if err := bucket.Drop(); err != nil { panic(err) }
Recursos adicionales
Para obtener más información sobre GridFS y el almacenamiento, consulta las siguientes páginas en el manual del Servidor:
Documentación de la API
Para obtener más información sobre los métodos y tipos mencionados en esta guía, vea la siguiente documentación de la API: