Overview
En esta guía, puedes aprender cómo almacenar y recuperar archivos grandes en MongoDB usando GridFS. El sistema de almacenamiento GridFS divide los archivos en fragmentos al almacenarlos y vuelve a ensamblar esos archivos al recuperarlos. La implementación del driver de GridFS es una abstracción que gestiona las operaciones y la organización del almacenamiento de archivos.
Utilice GridFS si el tamaño de cualquiera de sus archivos supera el límite de tamaño del documento BSON de 16 MB. Para obtener información más detallada sobre si GridFS es adecuado para su caso de uso, consulte GridFS en el manual del MongoDB Server.
Cómo funciona GridFS
GridFS organiza los archivos en un bucket, un grupo de colecciones de MongoDB que contienen los fragmentos de archivos e información que los describe. El bucket contiene las siguientes colecciones:
chunks: almacena los fragmentos de archivos binariosfiles:Almacena los metadatos del archivo
El controlador crea el bucket de GridFS, si aún no existe, la primera vez que se escriben datos en él. El bucket contiene las colecciones chunks y files, con el prefijo predeterminado fs, a menos que se especifique otro. Para garantizar una recuperación eficiente de los archivos y los metadatos relacionados, el controlador crea un índice en cada colección. El controlador se asegura de que estos índices existan antes de realizar operaciones de lectura y escritura en el bucket de GridFS.
Para obtener más información sobre los índices de GridFS, consulta Índices de GridFS en el manual del servidor MongoDB.
Cuando se utiliza GridFS para almacenar archivos, el driver divide los archivos en fragmentos más pequeños, cada uno representada por un documento independiente en la colección chunks. También crea un documento en la colección files que contiene un ID de archivo, el nombre del archivo y otros metadatos del archivo.
El siguiente diagrama muestra cómo GridFS divide los archivos cuando se cargan en un bucket.

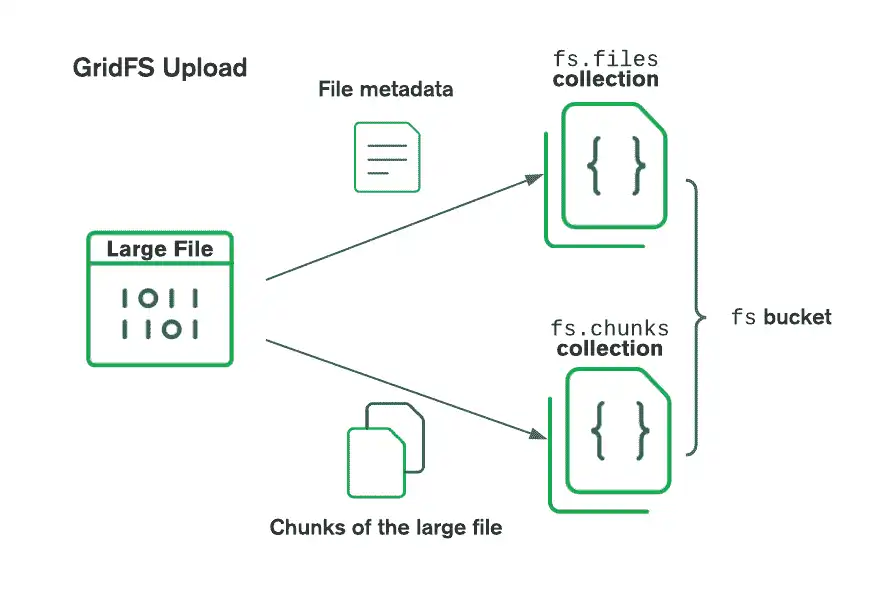
Al recuperar archivos, GridFS obtiene los metadatos de la colección files en el bucket especificado y usa la información para reconstruir el archivo a partir de documentos en la colección chunks.
Crear un bucket de GridFS
Para comenzar a utilizar GridFS para almacenar o recuperar archivos, crea una nueva instancia de la clase GridFSBucket, pasando un objeto IMongoDatabase que represente tu base de datos. Este método accede a un bucket existente o crea uno nuevo si aún no existe.
El siguiente ejemplo crea una nueva instancia de la clase GridFSBucket para la base de datos db:
var client = new MongoClient("<connection string>"); var database = client.GetDatabase("db"); // Creates a GridFS bucket or references an existing one var bucket = new GridFSBucket(database);
Personaliza el cubo
Puedes personalizar la configuración del bucket GridFS pasando una instancia de la clase GridFSBucketOptions al constructor GridFSBucket(). La siguiente tabla describe las propiedades de la clase GridFSBucketOptions:
Campo | Descripción |
|---|---|
| El nombre del bucket que se utilizará como prefijo para los archivos y colecciones de fragmentos. El valor por defecto es Tipo de dato: |
| El tamaño del fragmento en que GridFS divide los archivos. El valor por defecto es 255 KB. Tipo de dato: |
| El nivel de consistencia de lectura a usar para las operaciones en buckets. El valor predeterminado es el nivel de consistencia de lectura de la base de datos. Tipo de datos: ReadConcern |
| La preferencia de lectura que se utilizará para las operaciones de bucket. El valor por defecto es la preferencia de lectura de la base de datos. Tipo de datos: ReadPreference |
| El nivel de confirmación de escritura (write concern) a utilizar para operaciones de bucket. El valor por defecto es el nivel de confirmación de escritura (write concern) de la base de datos. Tipo de dato: WriteConcern |
El siguiente ejemplo crea un bucket llamado "myCustomBucket" pasando una instancia de la clase GridFSBucketOptions al constructor GridFSBucket():
var options = new GridFSBucketOptions { BucketName = "myCustomBucket" }; var customBucket = new GridFSBucket(database, options);
Cargar archivos
Puede cargar archivos en un bucket de GridFS utilizando los siguientes métodos:
OpenUploadStream()oOpenUploadStreamAsync(): abre un nuevo flujo de carga en el que puedes escribir el contenido del archivoUploadFromStream()oUploadFromStreamAsync(): Sube el contenido de una secuencia existente a un archivo GridFS
Las siguientes secciones describen cómo usar estos métodos.
Guardar en un flujo de carga
Utilice el método OpenUploadStream() o OpenUploadStreamAsync() para crear un flujo de carga para un nombre de archivo determinado. Estos métodos aceptan los siguientes parámetros:
Parameter | Descripción |
|---|---|
| El nombre del archivo a subir. Tipo de dato: |
| Opcional. Una instancia de la Tipo de dato: GridFSUploadOptions |
| Opcional. Un token que puedes usar para cancelar la operación. Tipo de dato: CancellationToken |
Este ejemplo de código demuestra cómo abrir un flujo de carga realizando los siguientes pasos:
Llama al método
OpenUploadStream()para abrir un flujo GridFS con permisos de escritura para un archivo llamado"my_file"Llama al método
Write()para escribir datos enmy_fileLlama al método
Close()para cerrar el flujo que apunta amy_file
Selecciona el Synchronous o la pestaña Asynchronous para ver el código correspondiente:
using (var uploader = bucket.OpenUploadStream("my_file")) { // ASCII for "HelloWorld" byte[] bytes = { 72, 101, 108, 108, 111, 87, 111, 114, 108, 100 }; uploader.Write(bytes, 0, bytes.Length); uploader.Close(); }
using (var uploader = await bucket.OpenUploadStreamAsync("my_file", options)) { // ASCII for "HelloWorld" byte[] bytes = { 72, 101, 108, 108, 111, 87, 111, 114, 108, 100 }; await uploader.WriteAsync(bytes, 0, bytes.Length); await uploader.CloseAsync(); }
Para personalizar la configuración del flujo de subida, pasa una instancia de la clase GridFSUploadOptions al método OpenUploadStream() o OpenUploadStreamAsync(). La clase GridFSUploadOptions contiene las siguientes propiedades:
Propiedad | Descripción |
|---|---|
| El número de fragmentos a subir en cada lote. El valor por defecto es 16 MB dividido por el valor de la propiedad Tipo de dato: |
| El tamaño de cada fragmento, excepto el último, que es más pequeño. El valor predeterminado es 255 KB. Tipo de dato: |
| Metadatos que se deben almacenar con el archivo, incluidos los siguientes elementos:
El valor por defecto es Tipo de dato: BsonDocument |
El siguiente ejemplo realiza los mismos pasos que el anterior, pero también utiliza la opción ChunkSizeBytes para especificar el tamaño de cada fragmento. Seleccione la pestaña Synchronous o Asynchronous para ver el código correspondiente.
Subir un flujo existente
Utilice el método UploadFromStream() o UploadFromStreamAsync() para cargar el contenido de un flujo en un nuevo archivo GridFS. Estos métodos aceptan los siguientes parámetros:
Parameter | Descripción |
|---|---|
| El nombre del archivo a subir. Tipo de dato: |
| El flujo desde el que se leerán los contenidos del archivo. Tipo de datos: Stream |
| Opcional. Una instancia de la Tipo de dato: GridFSUploadOptions |
| Opcional. Un token que puedes usar para cancelar la operación. Tipo de dato: CancellationToken |
Este ejemplo de código demuestra cómo abrir un flujo de carga realizando los siguientes pasos:
Abre un archivo ubicado en
/path/to/input_filecomo un flujo en modo de lectura binariaLlama al método
UploadFromStream()para escribir el contenido de la transmisión en un archivo GridFS llamado"new_file"
Selecciona la pestaña Synchronous o Asynchronous para ver el código correspondiente.
using (var fileStream = new FileStream("/path/to/input_file", FileMode.Open, FileAccess.Read)) { bucket.UploadFromStream("new_file", fileStream); }
using (var fileStream = new FileStream("/path/to/input_file", FileMode.Open, FileAccess.Read)) { await bucket.UploadFromStreamAsync("new_file", fileStream); }
Descargar archivos
Puede descargar archivos de un bucket GridFS utilizando los siguientes métodos:
OpenDownloadStream()oOpenDownloadStreamAsync(): Puedes abrir un nuevo flujo de descargar desde el cual puedes leer el contenido del archivoDownloadToStream()oDownloadToStreamAsync(): Escribe el contenido de un archivo GridFS en un flujo existente
Las siguientes secciones describen estos métodos con más detalle.
Leer desde un flujo de descarga
Utiliza el método OpenDownloadStream() o OpenDownloadStreamAsync() para crear un flujo de descarga. Estos métodos aceptan los siguientes parámetros:
Parameter | Descripción |
|---|---|
| El valor Tipo de datos: BsonValue |
| opcional. Una instancia de la clase Tipo de dato: GridFSDownloadOptions |
| Opcional. Un token que puedes usar para cancelar la operación. Tipo de dato: CancellationToken |
El siguiente ejemplo de código demuestra cómo abrir un flujo de descarga realizando los siguientes pasos:
Recupera el valor
_iddel archivo GridFS llamado"new_file"Llama al método
OpenDownloadStream()y pasa el valor de_idpara abrir el archivo como un flujo GridFS legibleCrea un vector
bufferpara almacenar el contenido del archivoLlama al método
Read()para leer el contenido del archivo desde el flujodownloaderal vector
Selecciona la pestaña Synchronous o Asynchronous para ver el código correspondiente.
var filter = Builders<GridFSFileInfo>.Filter.Eq(x => x.Filename, "new_file"); var doc = bucket.Find(filter).FirstOrDefault(); if (doc != null) { using (var downloader = bucket.OpenDownloadStream(doc.Id)) { var buffer = new byte[downloader.Length]; downloader.Read(buffer, 0, buffer.Length); // Process the buffer as needed } }
var filter = Builders<GridFSFileInfo>.Filter.Eq(x => x.Filename, "new_file"); var cursor = await bucket.FindAsync(filter); var fileInfoList = await cursor.ToListAsync(); var doc = fileInfoList.FirstOrDefault(); if (doc != null) { using (var downloader = await bucket.OpenDownloadStreamAsync(doc.Id)) { var buffer = new byte[downloader.Length]; await downloader.ReadAsync(buffer, 0, buffer.Length); // Process the buffer as needed } }
Para personalizar la configuración del flujo de descarga, pasa una instancia de la clase GridFSDownloadOptions al método OpenDownloadStream(). La clase GridFSDownloadOptions contiene la siguiente propiedad:
Propiedad | Descripción |
|---|---|
| Indica si el flujo admite la búsqueda, la consulta y la modificación de la posición actual. El valor predeterminado Tipo de dato: |
El siguiente ejemplo realiza los mismos pasos que el ejemplo anterior, pero también establece la opción Seekable en true para especificar que la secuencia se puede buscar.
Selecciona la pestaña Synchronous o Asynchronous para ver el código correspondiente.
Descargar en una transmisión existente
Utilice el método DownloadToStream() o DownloadToStreamAsync() para descargar el contenido de un archivo GridFS a un flujo existente. Estos métodos aceptan los siguientes parámetros:
Parameter | Descripción |
|---|---|
| El valor Tipo de datos: BsonValue |
| El flujo donde el controlador .NET/C# descarga el archivo GridFS. El valor de esta propiedad debe ser un objeto que implemente la clase Tipo de datos: Stream |
| opcional. Una instancia de la clase Tipo de dato: GridFSDownloadOptions |
| Opcional. Un token que puedes usar para cancelar la operación. Tipo de dato: CancellationToken |
El siguiente ejemplo de código muestra cómo descargar a un flujo existente realizando las siguientes acciones:
Abre un archivo ubicado en
/path/to/output_filecomo un flujo en modo binario de escrituraRecupera el valor
_iddel archivo GridFS llamado"new_file"Llama al método
DownloadToStream()y pasa el valor_idpara descargar el contenido de"new_file"a una secuencia
Selecciona la pestaña Synchronous o Asynchronous para ver el código correspondiente.
var filter = Builders<GridFSFileInfo>.Filter.Eq(x => x.Filename, "new_file"); var doc = bucket.Find(filter).FirstOrDefault(); if (doc != null) { using (var outputFile = new FileStream("/path/to/output_file", FileMode.Create, FileAccess.Write)) { bucket.DownloadToStream(doc.Id, outputFile); } }
var filter = Builders<GridFSFileInfo>.Filter.Eq(x => x.Filename, "new_file"); var cursor = await bucket.FindAsync(filter); var fileInfoList = await cursor.ToListAsync(); var doc = fileInfoList.FirstOrDefault(); if (doc != null) { using (var outputFile = new FileStream("/path/to/output_file", FileMode.Create, FileAccess.Write)) { await bucket.DownloadToStreamAsync(doc.Id, outputFile); } }
Buscar archivos
Para encontrar archivos en un bucket GridFS, llame al método Find() o FindAsync() en su instancia GridFSBucket. Estos métodos aceptan los siguientes parámetros:
Parameter | Descripción |
|---|---|
| Un filtro de consulta que especifica las entradas que deben coincidir en la colección Tipo de dato: |
| El flujo desde el que se leerán los contenidos del archivo. Tipo de datos: Stream |
| opcional. Una instancia de la clase Tipo de dato: GridFSFindOptions |
| Opcional. Un token que puedes usar para cancelar la operación. Tipo de dato: CancellationToken |
El siguiente ejemplo de código muestra cómo recuperar e imprimir metadatos de archivos en un bucket de GridFS. El Find() método devuelve una IAsyncCursor<GridFSFileInfo> instancia desde la que se puede acceder a los resultados. Utiliza un foreach bucle para iterar sobre el cursor devuelto y mostrar el contenido de los archivos cargados en los ejemplos de carga de archivos.
Selecciona la pestaña Synchronous o Asynchronous para ver el código correspondiente.
var filter = Builders<GridFSFileInfo>.Filter.Empty; var files = bucket.Find(filter); foreach (var file in files.ToEnumerable()) { Console.WriteLine(file.ToJson()); }
{ "_id" : { "$oid" : "..." }, "length" : 13, "chunkSize" : 261120, "uploadDate" : { "$date" : ... }, "filename" : "new_file" } { "_id" : { "$oid" : "..." }, "length" : 50, "chunkSize" : 1048576, "uploadDate" : { "$date" : ... }, "filename" : "my_file" }
var filter = Builders<GridFSFileInfo>.Filter.Empty; var files = await bucket.FindAsync(filter); await files.ForEachAsync(file => Console.Out.WriteLineAsync(file.ToJson()))
{ "_id" : { "$oid" : "..." }, "length" : 13, "chunkSize" : 261120, "uploadDate" : { "$date" : ... }, "filename" : "new_file" } { "_id" : { "$oid" : "..." }, "length" : 50, "chunkSize" : 1048576, "uploadDate" : { "$date" : ... }, "filename" : "my_file" }
Para personalizar la operación de búsqueda, pasa una instancia de la clase GridFSFindOptions al método Find() o FindAsync(). La clase GridFSFindOptions contiene las siguientes propiedades:
Propiedad | Descripción |
|---|---|
| El orden ascendente o descendente de los resultados. Si no especifica un orden de clasificación, el método devuelve los resultados en el orden en que fueron insertados. Tipo de dato: |
Borrar archivos
Para borrar archivos de un bucket GridFS, llama al método Delete() o DeleteAsync() en tu instancia de GridFSBucket. Este método remueve la colección de metadatos de un archivo y sus fragmentos asociados de tu bucket.
Los métodos Delete y DeleteAsync() aceptan los siguientes parámetros:
Parameter | Descripción |
|---|---|
| El Tipo de datos: BsonValue |
| Opcional. Un token que puedes usar para cancelar la operación. Tipo de dato: CancellationToken |
El siguiente ejemplo de código muestra cómo borrar un archivo llamado "my_file" pasando su valor _id a delete_file():
Utiliza la clase
Builderspara crear un filtro que coincida con el archivo llamado"my_file"Utiliza el método
Find()para buscar el archivo llamado"my_file"Pasa el valor
_iddel archivo al métodoDelete()para eliminar el archivo
Selecciona la pestaña Synchronous o Asynchronous para ver el código correspondiente.
var filter = Builders<GridFSFileInfo>.Filter.Eq(x => x.Filename, "new_file"); var doc = bucket.Find(filter).FirstOrDefault(); if (doc != null) { bucket.Delete(doc.Id); }
var filter = Builders<GridFSFileInfo>.Filter.Eq(x => x.Filename, "new_file"); var cursor = await bucket.FindAsync(filter); var fileInfoList = await cursor.ToListAsync(); var doc = fileInfoList.FirstOrDefault(); if (doc != null) { await bucket.DeleteAsync(doc.Id); }
Nota
Revisiones de archivos
Los métodos Delete() y DeleteAsync() solo permiten eliminar un archivo a la vez. Para eliminar cada revisión de archivo, o archivos con diferentes tiempos de carga que comparten el mismo nombre, recopile los valores _id de cada revisión. Luego, pase cada valor _id en llamadas separadas al método Delete() o DeleteAsync().
Documentación de la API
Para obtener más información sobre las clases utilizadas en esta página, consulta la siguiente documentación de la API:
Para conocer más sobre los métodos de la *clase* GridFSBucket utilizados en esta página, consulta la siguiente documentación de la API: