Aprenda cómo la convergencia de datos alternativos, la inteligencia artificial y la IA generativa está transformando la base de la evaluación crediticia.
caso de uso: Gen AI
Productos y herramientas: MongoDB Atlas, Spark transmisión Connector, MongoDB Atlas búsqueda vectorial
emparejar: LangChain, Fireworks.ai
Resumen de la solución
Esta solución muestra cómo la convergencia de la inteligencia artificial de datos alternativos y la IA generativa transforma los fundamentos de la calificación crediticia. Los métodos alternativos de calificación crediticia ofrecen una evaluación más inclusiva y matizada de la solvencia, y además pueden superar los desafíos de los modelos tradicionales.
Esta solución explica paso a paso un proceso de aplicación de tarjeta de crédito en linea de muestra y muestra cómo MongoDB respalda la evaluación crediticia. También se puede utilizar un enfoque similar para otros productos de crédito, como préstamos personales, hipotecas, préstamos corporativos y líneas de crédito para financiación comercial.
Desafíos de la calificación crediticia tradicional
Aquí tienes algunos ejemplos de los desafíos y limitaciones de los modelos tradicionales de evaluación de crédito:
Historial crediticio limitado: Muchas personas se encuentran con obstáculos en forma de un historial crediticio limitado o inexistente, lo que dificulta demostrar su solvencia crediticia debido a la falta de datos históricos.
Ingresos inconsistentes: los ingresos irregulares, típicos del trabajo a tiempo parcial o independiente, representan un desafío para los modelos tradicionales de calificación crediticia, que etiquetan a las personas como de mayor riesgo, lo que lleva al rechazo de solicitudes o a límites de crédito restrictivos.
Alta utilización del crédito existente: la dependencia del crédito existente, que conduce a un aumento en las proporciones de utilización del crédito, se convierte en un obstáculo en las aplicaciones de crédito, ya que los solicitantes pueden enfrentar el rechazo o la aprobación con términos menos favorables.
Falta de claridad en los motivos de rechazo: la falta de transparencia en los motivos de rechazo dificulta que los clientes aborden la causa raíz y mejoren su solvencia para futuras solicitudes.
Compilar la solución
La siguiente solución muestra cómo MongoDB transforma la solicitud de crédito en los siguientes aspectos del proceso:
Simplifique la captura y el procesamiento de datos.
Mejora la puntuación crediticia con IA.
Explique el rechazo de la aplicación de crédito.
Recomiende productos de crédito alternativos.
Simplifica la captura y el procesamiento de datos
Solicitar productos de crédito suele ser un proceso complicado por las siguientes razones:
Complejidad del proceso de aplicación: El proceso de aplicación de tarjeta de crédito implica varios pasos que consumen mucho tiempo:
Elige una tarjeta: Primero, selecciona una tarjeta de crédito que se ajuste a tus necesidades. Investiga diferentes tarjetas, compara sus características y comprende sus términos y condiciones.
Verificación de elegibilidad: Siguiente, verifica si cumples con los criterios de elegibilidad establecidos por el banco. Estos criterios suelen considerar factores como la calificación de crédito, la edad, los ingresos y las obligaciones financieras.
Presentación de documentos: Proporcione documentos como prueba de identidad (como tarjeta de Seguridad Social, pasaporte y/o licencia de conducir), prueba de domicilio (contrato de alquiler, facturas de servicios públicos) y prueba de ingresos (estados de cuenta bancarios, nóminas de salario, Formulario 16).
Formulario de aplicación: complete el formulario de aplicación de tarjeta de crédito. Puedes hacerlo en línea a través del sitio web del banco, la banca en línea o visitando una sucursal. Algunos bancos requieren documentos físicos, aunque los procesos digitales son cada vez más comunes.
Verificación y referencias: Los bancos verifican la autenticidad de tus documentos y comprueban la información proporcionada. Este paso también implica calcular la probabilidad de incumplimiento utilizando algoritmos de IA/aprendizaje automático.
Recopilación de información redundante: los bancos a menudo recopilan datos redundantes, como:
Detalles de KYC: A pesar de tener acceso a sus detalles de KYC (Conozca a su Cliente), aún le piden que los envíe repetidamente.
Verificación de ingresos: a pesar de contar con información como tus ingresos, historial bancario, facturas de servicios públicos, pagos de alquiler, pagos móviles y gastos de compras, el banco podría hacer una solicitud de prueba adicional para verificar estos detalles.
Agilizar este proceso eliminando solicitudes redundantes y aprovechando los datos existentes puede mejorar la experiencia del usuario.
Estos formularios de aplicación aumentan en complejidad con otros productos crediticios como préstamos para automóviles, hipotecas y operaciones con renta variable. En un formulario de aplicación, puede haber información tabular y jerárquica que deba completarse. La flexible plataforma de datos de MongoDB para desarrolladores admite de forma nativa Los datos JSON no requieren que los documentos tengan el mismo esquema, lo que mejora la capacidad de gestionar varios tipos de datos.
Para simplificar el proceso de captura de datos y mejorar el rendimiento de la aplicación, puedes usar JSON para el formulario de solicitud de crédito en línea. JSON tiene una representación de datos estructurada, lo que te permite organizar los diferentes detalles que necesitas almacenar. El modelo de datos flexible se ajusta bien a la naturaleza dinámica de los requisitos de las solicitudes de tarjetas de crédito, permitiendo almacenar datos relacionados juntos, incluso si esos datos no tienen exactamente la misma estructura. JSON también es generalmente entendido por otros desarrolladores, lo que permite la colaboración y facilita la comprensión de los datos de un vistazo.
MongoDB procesa documentos JSON eficazmente en aplicaciones de crédito gracias a su soporte nativo para el formato BSON similar a JSON.
Mejorar la calificación crediticia con IA
Aprovecha Atlas, la plataforma de datos para desarrolladores de MongoDB para crear un perfil bancario integral del usuario combinando los puntos de datos relevantes.
Este es un diagrama arquitectónico de la pipeline de procesamiento de datos para predecir la probabilidad de morosidad y la puntuación crediticio:

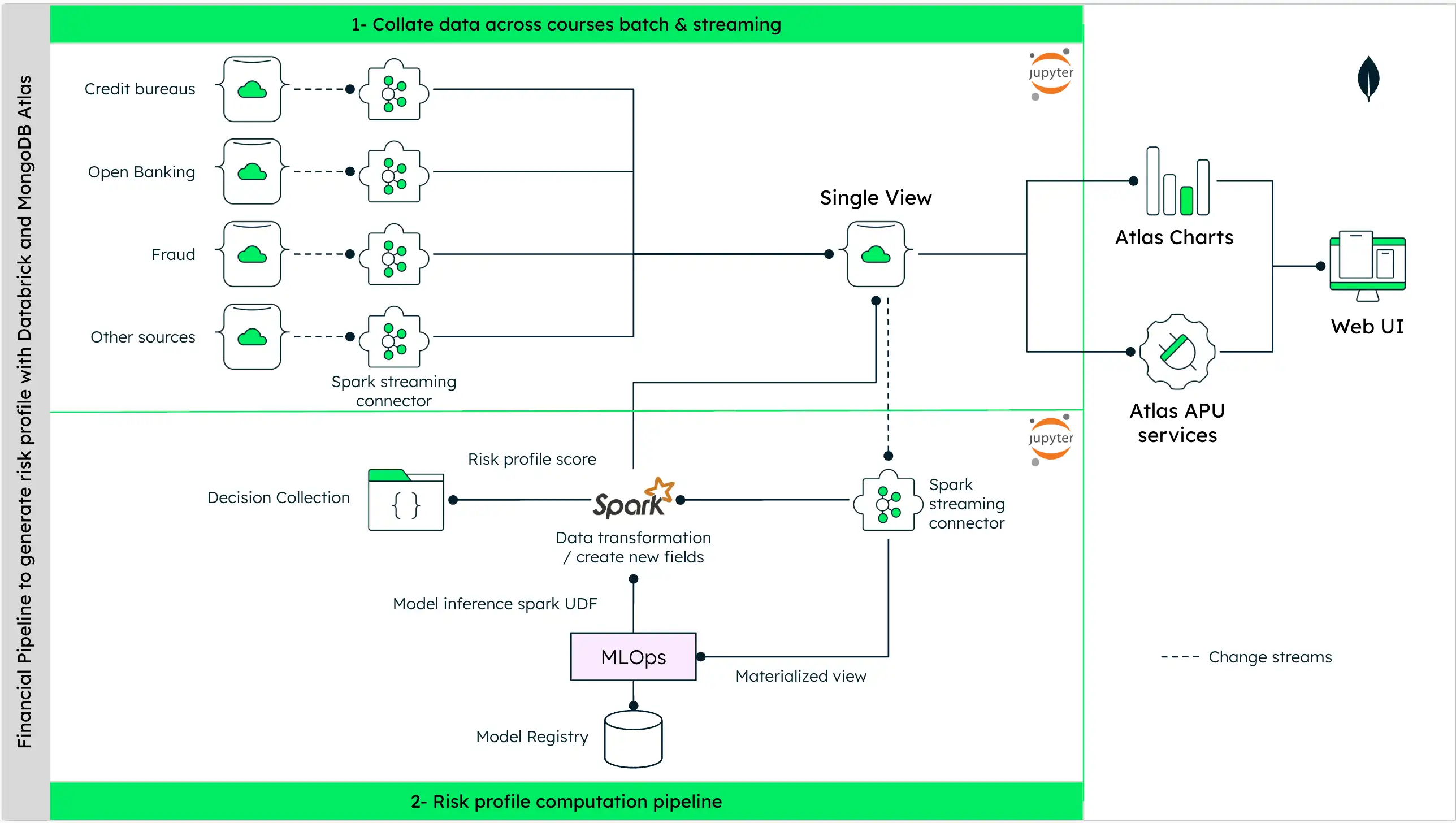
Figura 1. Diagrama del pipeline de procesamiento de datos para la calificación crediticia
El proceso de obtención de datos para la calificación crediticia de un cliente implica los siguientes pasos:
Colección de datos: Inicialmente, el proceso recopila datos de diversas fuentes como burós de crédito, open banking, sistemas de detección de fraude y otras fuentes relevantes.
Procesamiento de datos: Los datos recopilados se procesan utilizando herramientas como Spark Streaming Connectors para crear una vista unificada del perfil financiero del cliente y almacenar los mismos datos como una única vista en MongoDB Atlas.
Generación de perfiles de riesgo: Desde esta vista unificada, se generan perfiles de riesgo o sugerencias de productos. Esto implica utilizar métodos estadísticos para realizar análisis descriptivos, así como técnicas de inteligencia artificial (IA) o aprendizaje automático (ML) para identificar patrones en los datos y realizar una puntuación de propensión al riesgo.
Desarrollo del modelo: Se pueden utilizar diversos algoritmos de aprendizaje automático para la calificación crediticia y la toma de decisiones. Considera la regresión logística, los árboles de decisión, las máquinas de soporte vectorial y las redes neuronales.
Este tutorial emplea el modelo XGBoost (Árboles Extremos de Gradiente Potenciado), un algoritmo de aprendizaje automático comúnmente utilizado por su rendimiento predictivo. El algoritmo es un método de aprendizaje supervisado basado en la aproximación de funciones. El algoritmo tiene las siguientes capacidades:
Optimizar funciones de pérdida específicas.
Aplicar varias técnicas de regularización.
Gestione datos de alta dimensión.
Capturar patrones complejos para clasificación y regresión.
El modelo respalda su resultado de inferencia, lo que ayuda a explicar el resultado de este modelo predictivo.
Transformación de datos: Antes de realizar la puntuación del perfil de riesgo, los datos brutos del usuario se transforman utilizando Spark (o un marco de análisis gestionado similar). La información se recopila a partir de diversas fuentes para crear una vista única y materializada de datos, que puede derivarse directamente de la colección de MongoDB Atlas, lo cual es útil tanto para el desarrollo de modelos como para diversas tareas de análisis descriptivo. Este paso también puede implicar la inferencia del modelo.
Recopilación de decisiones: Los datos transformados finales se incorporan a una recopilación de decisiones. Esto ayuda a los bancos e instituciones financieras a respaldar sus decisiones financieras y sus auditorías.
El objetivo es evaluar con precisión la solvencia de un cliente para tomar decisiones informadas sobre préstamos y realizar recomendaciones de productos financieros. El pipeline es una demostración de pipelines de evaluación de riesgos existentes mantenidos por las organizaciones.
Explica la denegación de aplicación de crédito
Comprender los motivos del rechazo de una solicitud de crédito es fundamental. Aprenda cómo MongoDB y los modelos de lenguaje extenso (LLM) pueden explicar las predicciones del modelo XGBoost (el modelo utilizado en este tutorial).
Aquí está el diagrama arquitectónico que explica la evaluación de crédito utilizando un LLM:

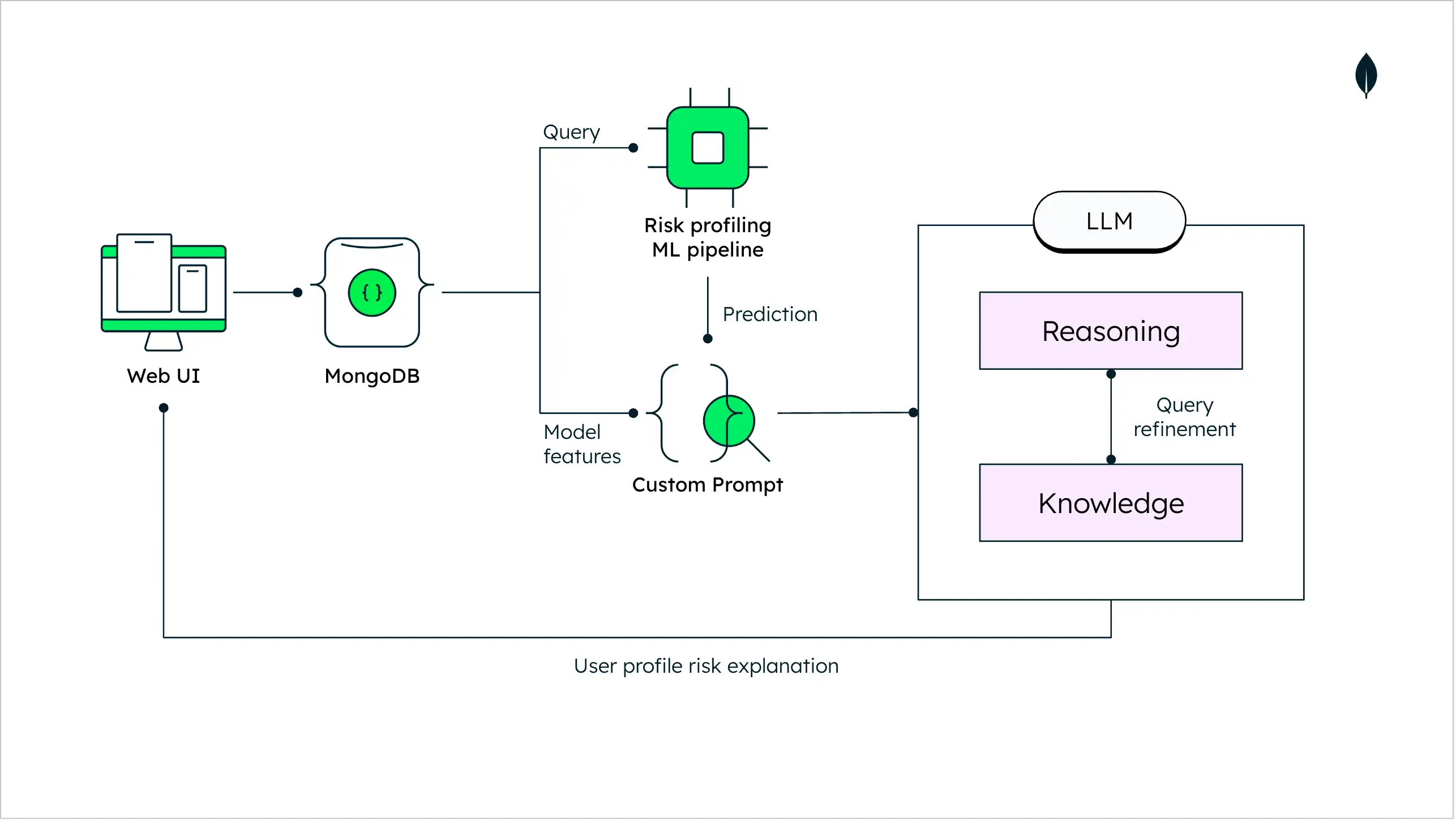
Figura 2. Diagrama de arquitectura de scoring crediticio utilizando un LLM
El flujo de trabajo de ML para la creación de perfiles de riesgo proporciona una puntuación de probabilidad que define el riesgo asociado al perfil para la recomendación del producto. Este mensaje se comunica al usuario de forma estandarizada, donde solo se le informa del estado final de la aplicación. En la arquitectura propuesta con LLM, se puede utilizar la ingeniería de solicitudes para explicar el motivo del estado final de aprobación del producto, con razones válidas para el cliente final.
Aquí puedes encontrar el código y ejemplos de respuestas.El código para generar un mensaje similar se puede crear con Python en un Jupyter Notebook. En este enlace encontrará información detallada sobre cómo configurar MongoDB Atlas y obtener la cadena de conexión.
A continuación se muestra un ejemplo de una explicación de rechazo:

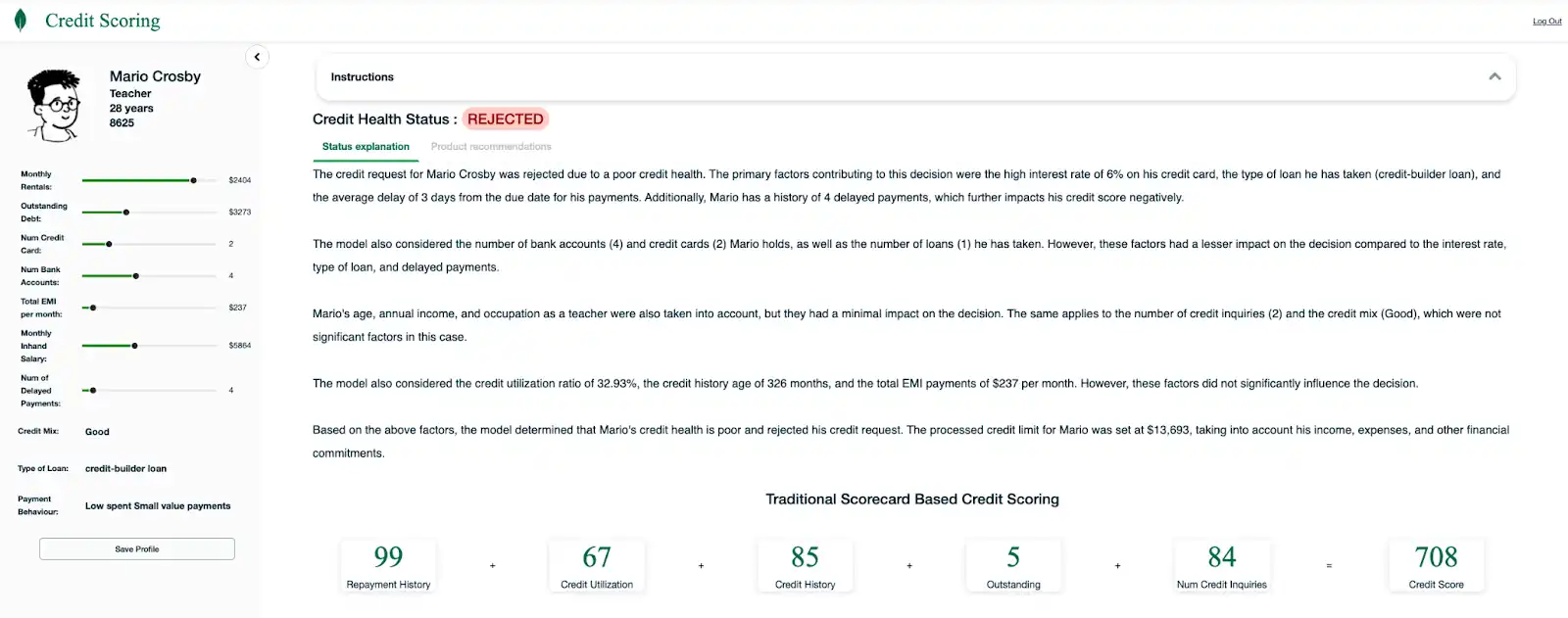
Figura 3. Ejemplo de explicación de rechazo
Este mensaje al cliente es una forma de IA explicable donde las características utilizadas en el modelo para elaborar perfiles de riesgo se clasifican y se utilizan como parte de la solicitud personalizada para el LLM. Esto puede ayudar a generar razones más descriptivas para que el cliente final explique su perfil de usuario, como se muestra arriba. Los LLM también pueden ayudar a resumir la lista de razones descriptivas para ofrecer una visión simplificada de la descripción.
En esta demostración, se utilizan dos enfoques para calificar la aplicación de crédito. El estado de la solicitud de crédito se determina utilizando un enfoque de aprendizaje automático, como se describe en la sección anterior, con el uso de más de 20 características relacionadas con el crédito. Aquí hay un subconjunto de las 15 funcionalidades más importantes:

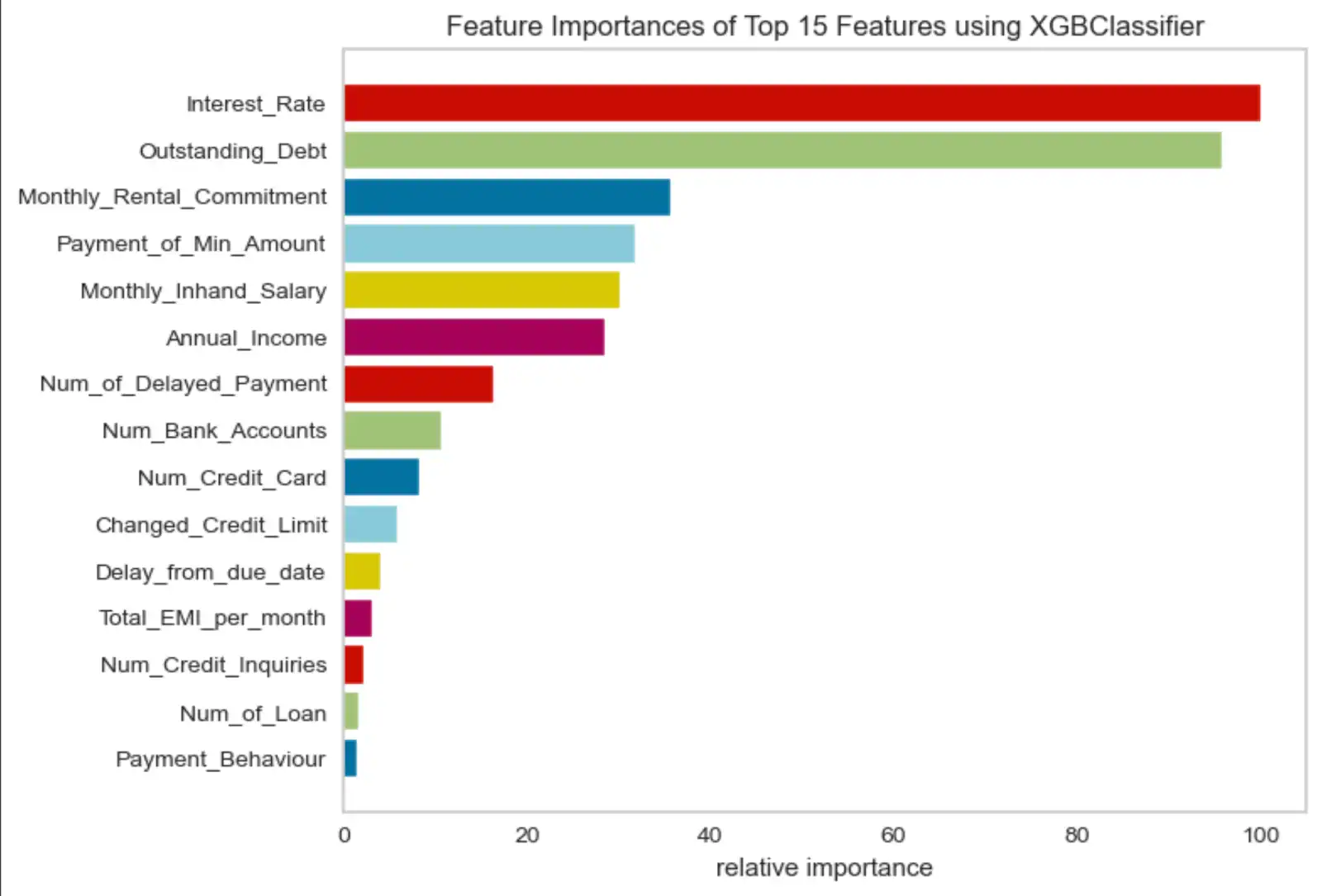
Figura 4. Gráfico de importancia de características
Para obtener más detalles sobre las características utilizadas en esta demostración, consulte el código fuente proporcionado en el repositorio de GitHub de puntuación de crédito.
Para demostrar la diferencia entre el enfoque de calificación de crédito de aprendizaje automático y el tradicional, considera que un método típico de calificación de crédito tradicional puede calificar la misma aplicación de crédito, pero normalmente utiliza solo unas pocas dimensiones. La demostración utiliza varias funcionalidades que suelen emplear los principales proveedores de puntaje de crédito:
El historial de pagos del solicitante de crédito
Utilización del crédito
Historial crediticio
Excepcional y número de consultas de crédito
Recomendar productos crediticios alternativos
La entidad crediticia debe intentar siempre realizar ventas cruzadas al cliente con un producto relevante que satisfaga sus necesidades, ya que está involucrado en el proceso y portal de aplicaciones.
Las instituciones financieras pueden implementar un sistema de recomendación de productos que ofrezca una explicación intuitiva de la justificación de la nueva recomendación, lo que generaría nuevas oportunidades de ingresos que los sistemas tradicionales no ofrecen actualmente. Proporcionar la justificación puede crear una relación personalizada con los clientes y aumentar la aceptación del producto recomendado. A continuación, se muestra un ejemplo de una arquitectura de datos utilizada para lograrlo:

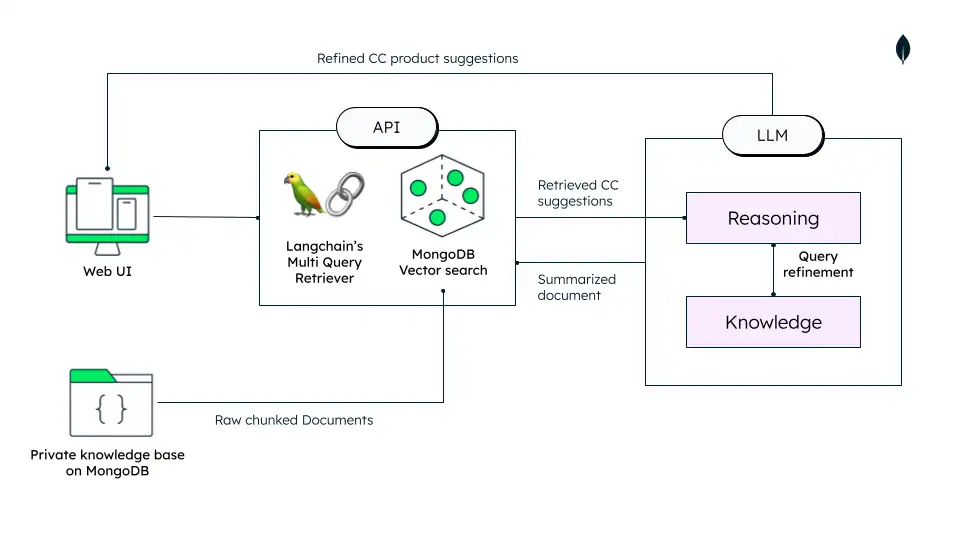
Figura 5. Arquitectura de sistemas de recomendación
Atlas Vector Search es una funcionalidad que permite realizar búsqueda semántica e IA generativa sobre cualquier tipo de datos. Integra tu base de datos operacional y búsqueda vectorial en una plataforma unificada y completamente gestionada, con una interfaz nativa de MongoDB. Puedes crear incrustaciones vectoriales con modelos de aprendizaje automático, luego almacenarlas e indexarlas en MongoDB Atlas para generación de recuperación aumentada (RAG), búsqueda semántica, motores de recomendación, personalización dinámica y otros casos de uso.
RAG es un paradigma que utiliza la búsqueda vectorial para recuperar documentos relevantes basándose en la query de entrada. Luego proporciona estos documentos recuperados como contexto a los LLM para ayudar a generar una respuesta más informada y precisa.
El tutorial anterior menciona tecnologías que pueden utilizarse para resolver un caso práctico de recomendación de productos de tarjetas de crédito. Los pasos del proceso se describen a continuación:
Cargue datos privados: cada producto de tarjeta de crédito tiene diferentes ofertas. Estos productos cambian ocasionalmente, al igual que las tarifas cobradas por diversos beneficios de estilo de vida, como tickets de cine y servicios de conserjería. Almacenar datos de productos en MongoDB como un almacén de datos operativos (ODS) ayuda a mantener los cambios y, al mismo tiempo, compila índices vectoriales.
Los grandes puntos de datos pueden actualizarse, borrarse, insertarse o reemplazarse adecuadamente según las necesidades.
Las descripciones de los productos de tarjetas de crédito son muy grandes, por lo que dividirlas en fragmentos más pequeños ayuda a recuperar la información relevante en consecuencia.
Puedes aprovechar los LLM para acortar la descripción del producto a resúmenes que incluyan todas las funcionalidades y costos relevantes del producto. Este cambio te permite recuperar rápidamente y recomendar los productos relevantes.
Recomendaciones impulsadas por modelos LLM: en este caso de uso, se utiliza un LLM como sistema de recomendación, donde el perfil de usuario generado en la etapa anterior puede usarse como entrada para generar subconsultas que pueden emplearse para realizar similitud semántica contra los vectores de productos almacenados en MongoDB Atlas.
Recomendación de productos con mensajes personalizados: los productos recomendados luego se utilizan en un mensaje personalizado para el LLM para generar resúmenes de recomendaciones de productos relevantes para el usuario final.
Esto ayuda a la institución financiera a personalizar la recomendación y ofrecer recomendaciones relevantes al cliente final, lo que impulsa mayores tasas de conversión.
La recomendación de productos aumenta la participación del cliente y mejora las experiencias de los usuarios al mejorar la puntuación de "Probablemente recomendado" de los productos ofrecidos.
Aquí encontrará el código y ejemplos de recomendaciones de productos alternativas. A continuación, se muestran algunos ejemplos. Puede usar Python en un Jupyter Notebook para crear código que genere una recomendación de producto y personalice su descripción.

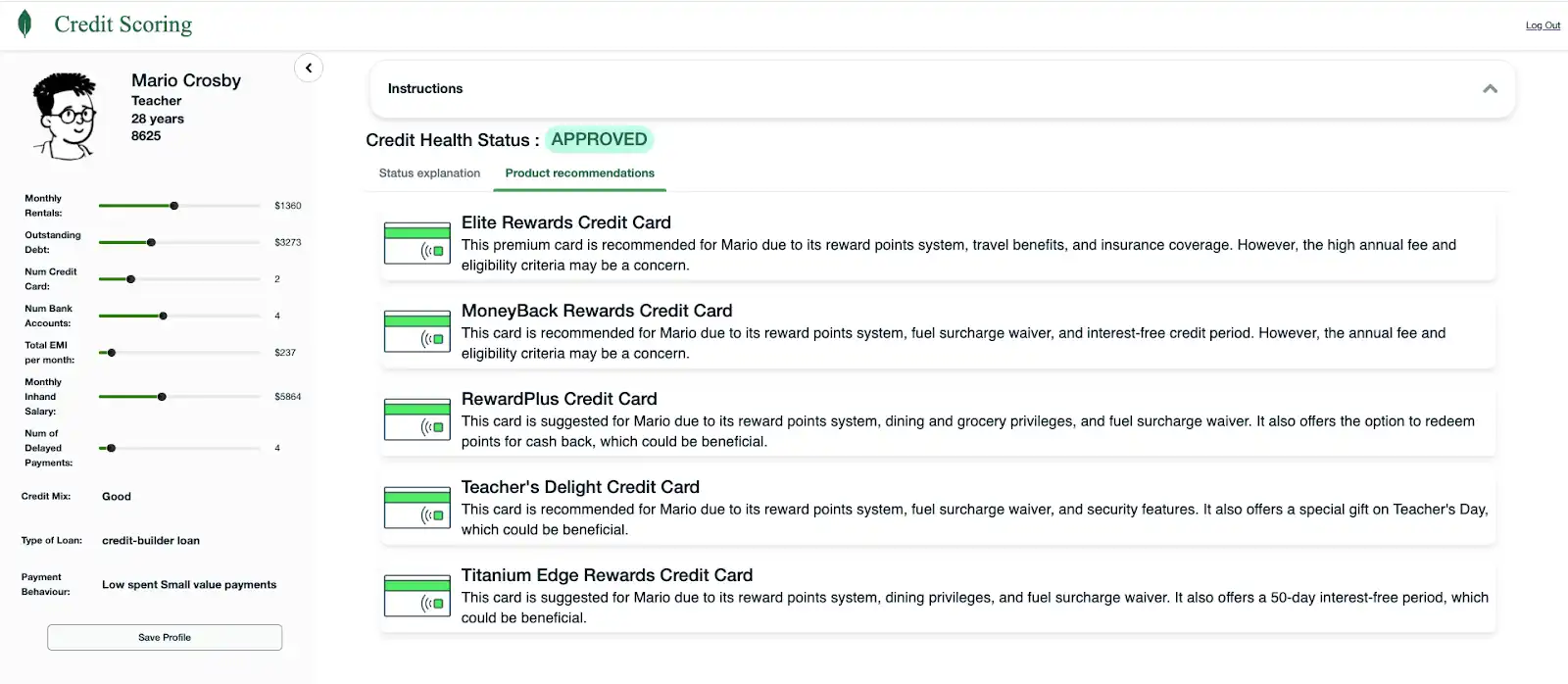
Figura 6. Ejemplo de una aplicación aprobada
En conclusión, la evaluación del crédito está experimentando una transformación gracias a la integración de IA generativa. La sinergia entre tecnología y finanzas está forjando un futuro en el que las decisiones de crédito sean tan precisas como oportunas para los prestatarios.
El código que demuestra todas las características de MongoDB para crear dicha solución está disponible en este repositorio deGitHub. Fireworks.AI, socio clave de MongoDB en IA, permite innovar con IA generativa de forma más rápida, eficiente y segura.
Lecciones clave
Comprender las capacidades de la GenIA: Sincronizar conjuntos de datos diversos para abordar las principales limitaciones de los modelos tradicionales de calificación crediticia.
Proporcionar un estado crediticio explicable: Utiliza la ingeniería de prompts a través de LLM para explicar el motivo del estado crediticio con razones válidas comunicadas al cliente final.
Desafío de los modelos tradicionales de calificación crediticia: Reconocer la necesidad de modelos alternativos de calificación crediticia que puedan adaptarse a la evolución de los comportamientos financieros, gestionar fuentes de datos no tradicionales y ofrecer una evaluación más inclusiva y precisa de la solvencia.
Utilice datos alternativos: Comprenda las ventajas de los datos alternativos para una calificación crediticia más precisa. Este modelo de calificación crediticia, por ejemplo, puede mejorarse aún más con datos alternativos como facturas de servicios públicos, facturas de teléfono móvil y historial académico.
Alucinación de direcciones: mitiga el riesgo de alucinaciones mediante el aprovechamiento de RAG para fundamentar las respuestas del modelo en información fáctica de fuentes actuales, asegurando que las respuestas del modelo reflejen la información más actual y precisa disponible.
Autores
Ashwin Gangadhar, Partner Solutions, MongoDB
Wei You Pan, Industry Solutions, MongoDB
Julian Boronat, Soluciones de Industria, MongoDB