Crea un servicio de transcripción y resumen de YouTube con un grandes modelos de lenguaje (LLM) y búsqueda semántica.
caso de uso: Gen AI
Industrias: Medios
Productos: MongoDB Atlas, Búsquedavectorialde MongoDB Atlas
Socios: LangChain
Resumen de la solución
Con la cantidad y variación de contenido informativo en plataformas como YouTube, es importante poder encontrar rápidamente videos relevantes y transcribirlos y resumirlos para la recopilación de conocimientos.
Esta solución crea una aplicación de resumen de video con IA generativa para transcribir y resumir videos de YouTube. La aplicación utiliza un LLM e incrustaciones vectoriales con Atlas Vector Search para la generación de video a texto y búsquedas semánticas. Este enfoque puede ser útil en sectores como el desarrollo de software, donde los profesionales pueden aprender tecnologías más rápidamente con el resumen de video con IA generativa.
Arquitecturas de Referencia
Sin MongoDB, una herramienta de resumen de videos utiliza el siguiente flujo de trabajo:

Figura 1. Arquitectura de referencia sin MongoDB
Esta solución utiliza la siguiente arquitectura con MongoDB:

Figura 1. Arquitectura de referencia con MongoDB
Primero, la solución utiliza YouTubeLoader para procesar enlaces de YouTube y obtener metadatos y transcripciones de videos. Luego, un script de Python recupera y resume la transcripción del video utilizando un LLM.
Luego, los modelos de embeddings de Voyage AI convierten las transcripciones resumidas en embeddings que se almacenan en MongoDB Atlas. Además, el Reconocimiento Óptico de Caracteres (OCR) y la IA realizan análisis en tiempo real del código directamente desde los fotogramas de video, generando una versión basada en texto y buscable de la información del video, junto con una explicación impulsada por IA.
La solución almacena estos datos procesados en documentos en MongoDB Atlas e incluye los metadatos del video, su transcripción y un resumen generado por IA. El usuario puede entonces buscar en estos documentos mediante la búsqueda de Atlas Vector Search de MongoDB.
Enfoque de modelo de datos
El siguiente bloque de código es un ejemplo de los documentos generados por esta solución:
{ "videoURL": "https://youtu.be/exampleID", "metadata":{ "title": "How to use GO with MongoDB", "author": "MongoDB", "publishDate": "2023-01-24", "viewCount": 1449, "length": "1533s", "thumbnail": "https://exmpl.com/thumb.jpg" }, "transcript": "Full transcript…", "summary": "Tutorial on using Go with MongoDB.", "codeAnalysis": [ "Main function in Go initializes the MongoDB client.", "Imports AWS Lambda package for serverless architecture." ] }
Los datos extraídos de cada video de YouTube consisten en lo siguiente:
videoURL: Un enlace directo al video de YouTube.metadata: Detalles del video como el título, el encargado de cargarlo y la fecha.transcript:Una representación textual del contenido hablado en el vídeo.summary: Una versión concisa y generada por IA de la transcripción.codeAnalysis:Una lista de ejemplos de código analizados por IA.
Compilar la solución
El código para esta solución está disponible en el repositorio de GitHub. Sigue las README para obtener instrucciones más específicas que te guiarán a través del siguiente procedimiento:
Crear un índice de búsqueda vectorial de MongoDB Atlas
Convierte la transcripción resumida en incrustaciones para búsqueda vectorial y almacénalas en MongoDB Atlas.
Para aprender a usar Atlas Vector Search y crear un índice, consulta MongoDB Vector Search Quick Start.
La siguiente figura muestra los valores de parámetros que se pueden usar al crear su índice de búsqueda vectorial.

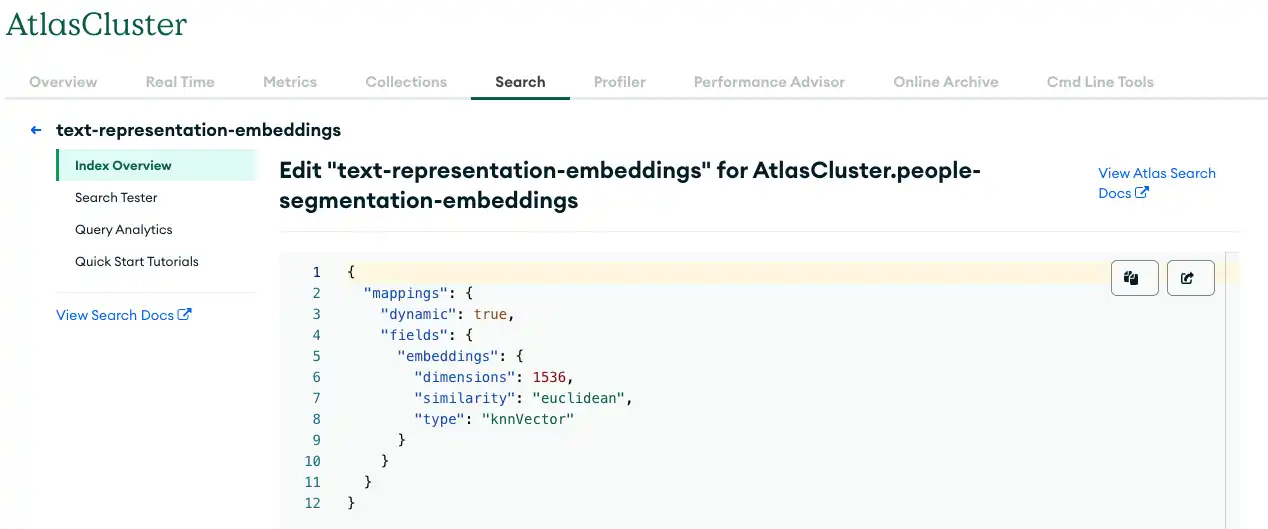
Figura 3. Almacenamiento de datos en MongoDB Atlas con búsqueda vectorial
Crear una capa de orquestación
La solución utiliza una capa de orquestación para coordinar los diversos servicios de la solución y gestionar flujos de trabajo complejos. La capa de orquestación está compuesta de las siguientes clases, que puedes encontrar en el repositorio de GitHub de la solución:
VideoServiceFacade: Actúa como el coordinador de las clasesVideoService,SearchServiceyVideoProcessResult. Este sistema gestiona las indicaciones del usuario y las solicitudes para la generación y resumén de transcripciones.VideoService: realiza la recopilación de resumenes de transcripciones.VideoProcessResultEncapsula los resultados de vídeo procesados, incluidas las metadatos, las acciones posibles y los términos óptimos de consulta de búsqueda.SearchService: Realiza una búsqueda en MongoDB Atlas.
Lecciones clave
Atlas Vector Search permite la búsqueda en lenguaje natural: Esta solución crea y almacena índices vectoriales en Atlas Vector Search, y almacena las incrustaciones y resultados generados por LLM en MongoDB Atlas. Esto permite a los usuarios buscar en una plataforma información relevante, previamente no estructurada, que podría no tener coincidencias exactas con palabras clave.
LangChain facilita aplicaciones impulsadas por IA: LangChain se integra perfectamente con MongoDB para crear una poderosa plataforma impulsada por IA.
Autores
Fabio Falavinha, MongoDB
David Macias, MongoDB