MongoDB Atlas cuenta con un sólido conjunto de métricas integradas, telemetría y registros que puedes aprovechar desde Atlas o integrar en tu pila de observabilidad y alertas de terceros. Esto permite supervisar y administrar las implementaciones de Atlas y responder a los incidentes de manera proactiva y en tiempo real.
La supervisión de tu implementación te permite:
Comprenda la salud y el estado de su clúster
Aprende cómo las operaciones que se ejecutan en el clúster impactan en la base de datos
Aprende si tu hardware tiene recursos limitados
Realizar optimización de carga de trabajo y consultas
Detecte y reaccione ante problemas en tiempo real para mejorar su pila de aplicaciones
Atlas proporciona varias métricas para la monitorización y las alertas. Puede realizar un seguimiento del estado, la disponibilidad, el consumo y el rendimiento de sus implementaciones en paneles visuales y mediante... API. También puedes ver varias métricas de clúster, supervisar el rendimiento de tu base de datos, configurar alertas y notificaciones de alertas, y descargar los registros de actividad.
Funciones para el monitoreo y alertas de Atlas
Métricas | Las métricas de implementación proporcionan perspectiva sobre el rendimiento del hardware y la eficiencia de la operación de la base de datos. Atlas recopila las métricas de tus servidores, bases de datos y procesos de MongoDB, y almacena los datos de las métricas en varios niveles de granularidad. Para cada nivel de granularidad, Atlas calcula las métricas como promedios de las métricas reportadas en el siguiente nivel de granularidad más fino. Muchas métricas tienen un equivalente en reporte de ráfaga. Puedes supervisar métricas en la Interfaz de Usuario de Atlas utilizando la vista de Métricas, el Real-Time Performance Panel, el perfilador del query, el Performance Advisor y la página de Namespace Insights. También puedes usar la CLI de Atlas o la API de Administración de Atlas para canalizar métricas en una herramienta de tu elección. La siguiente vista de Métricas de la Interfaz de Usuario de Atlas muestra la variedad de métricas disponibles para supervisar un set de réplicas de muestra de tres nodos: 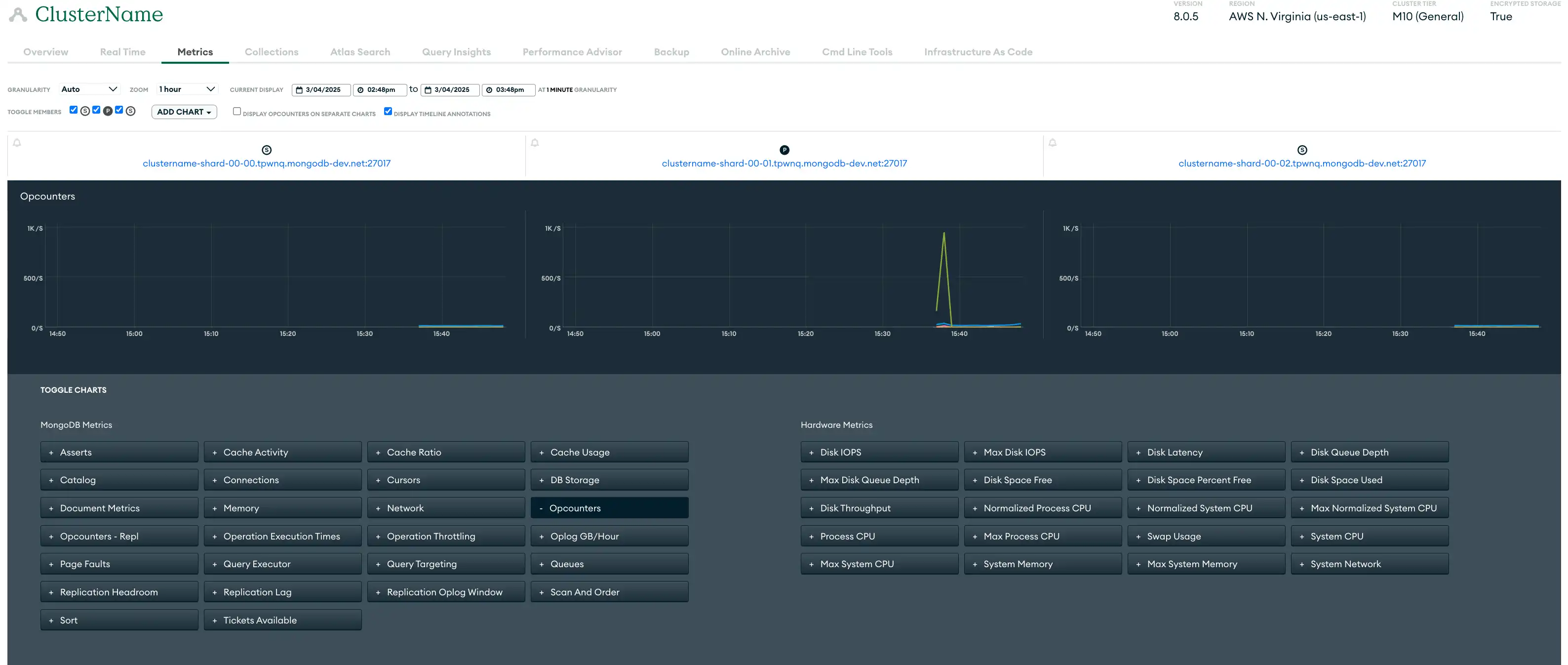 haga clic para ampliar |
Alertas | Atlas ofrece alertas para más de 200 tipos de eventos, lo que te permite personalizar alertas para una supervisión precisa. Atlas emite alertas para la base de datos y las condiciones del servidor que configures en la configuración de alertas. Cuando una condición activa una alerta, Atlas muestra un símbolo de advertencia en el clúster y envía notificaciones de alerta. Puede utilizar la interfaz de usuario de Atlas, la API de administración de Atlas, la CLI de Atlas y el recurso Terraform integrado para configurar alertas y notificaciones de alertas. |
Monitoring | Las visualizaciones de supervisión de Atlas ofrecen perspectivas sobre varias métricas clave, incluyendo el rendimiento del hardware y la eficiencia de las operaciones de la base de datos. Herramientas como los paneles de rendimiento en tiempo real para la visibilidad de la red y la operación, perfiladores del query para el seguimiento de tendencias de eficiencia y sugerencias automáticas de índices te permiten supervisar y solucionar problemas de manera más eficaz, impulsando una mayor eficiencia operativa. Por ejemplo, estas gráficas pueden ayudarte a entender el impacto de los reinicios y elecciones del servidor en el desempeño de la base de datos. |
Registros | Atlas proporciona registros para cada proceso del clúster. Cada proceso registra su actividad en su propio archivo de registro. Puede descargar registros mediante la interfaz de usuario de Atlas, la CLI de Atlas y la API de administración de Atlas. Para obtener más información, consulte Orientaciones para la auditoría y el registro en Atlas. |

Recomendaciones para la supervisión y Alertas de Atlas
Las implementaciones en una sola región no tienen consideraciones especiales para integraciones con herramientas de alertas de terceros, como Datadog y Prometheus. Vea Todas las recomendaciones de paradigma de implementación.
En clústeres multirregionales, considere los posibles costos de transferencia de datos asociados con el envío de registros y métricas entre regiones. Le recomendamos configurar su sistema de registro y auditoría para minimizar las transferencias de datos entre regiones, posiblemente manteniendo los registros locales en la región donde se generan.
Todas las recomendaciones paradigmáticas de implementación
Las siguientes recomendaciones se aplican a todos los paradigmas de implementación.
Monitorizar mediante métricas
Para supervisar el desempeño de tu clúster o base de datos, puedes visualizar las métricas del clúster, como el rendimiento histórico, el rendimiento y las métricas de utilización. La siguiente tabla enumera algunas (pero no todas) categorías importantes de métricas para supervisar:
Operaciones del clúster Atlas y métricas de conexión |
|
Métricas de Hardware |
|
Métricas de replicación |
|
Puedes usar la interfaz de usuario de Atlas, la API de Administración de Atlas y el Atlas CLI para ver las métricas del clúster de Atlas. Además, Atlas proporciona integraciones con funcionalidad incorporada con herramientas de terceros como Datadog y Prometheus, y también puedes aprovechar la API de administración de Atlas para integrarte con otras herramientas de métricas personalizadas.
Para obtener más información, consulta Revisar métricas del clúster.
Supervisar mediante la configuración de alertas
Atlas se extiende a tu pila de observabilidad existente, permitiéndote recibir alertas y tomar decisiones basadas en datos sin tener que reemplazar tus herramientas actuales ni modificar tus flujos de trabajo. Atlas puede enviar notificaciones de alertas con herramientas de terceros como Microsoft Teams, PagerDuty, DataDog, Opsgenie, Splunk On-Call y otras herramientas para brindarte visibilidad tanto del rendimiento de la base de datos como de la pila completa en el mismo lugar.
Configura alertas y notificaciones para eventos de seguridad, como intentos fallidos de inicio de sesión, patrones de acceso inusuales y violaciones de datos. En entornos de desarrollo y pruebas, recomendamos configurar alertas para clústeres que han estado inactivos por siete días o más para ayudarte a identificar qué clústeres se pueden apagar para ahorrar costos.
Cuando se consulten las alertas en la Interfaz de Usuario de Atlas, se recomienda usar los filtros disponibles para limitar los resultados por host, set de réplicas, clúster, partición, y así ayudar a centrarse en las alertas más críticas.
Configuraciones recomendadas de Atlas Alert
Como mínimo, recomendamos configurar las siguientes alertas. Estas recomendaciones de alertas proporcionan una base, pero debe ajustarlas según las características de su carga de trabajo. Si se especifican condiciones de "alta prioridad" en la siguiente tabla, le recomendamos configurar varias alertas para la misma condición: una para un nivel de gravedad bajo y otra para uno alto. Esto le permite configurar las notificaciones de alerta para cada una por separado.
Atlas configura algunas alertas por defecto. Para aprender sobre la configuración por defecto de alertas, consulte Configuración por defecto de Alertas.
Condición | Umbral de alerta recomendada: Prioridad baja | Umbral de alerta recomendado: Alta prioridad | Principales perspectivas |
|---|---|---|---|
Oplog window | < 24h durante 5 minutos | < 1h durante 10 minutos | Supervisa el oplog window, junto con el margen de replicación, para determinar si el secundario puede necesitar pronto una resincronización completa. La oplog window de replicación suele ayudar a determinar de antemano la resiliencia de las secundarias ante interrupciones del servicio planificadas e imprevistas. |
> 3 durante 5 minutos | > 30 durante 5 minutos | Monitoree los eventos de elección, que ocurren cuando un nodo principal se desactiva y un nodo secundario se elige como el nuevo principal. Los eventos de elección frecuentes pueden interrumpir las operaciones y afectar la disponibilidad, causando indisponibilidad temporal de escritura y una posible reversión de datos. Minimizar los eventos de elección garantiza operaciones de escritura consistentes y un rendimiento estable del clúster. | |
> 4000 durante 2 minutos | > 9000 durante 5 minutos | Supervisar si las IOPS del disco se acercan al máximo aprovisionamiento de IOPS. Determinar si el clúster puede gestionar cargas de trabajo futuras. | |
guardar IOPS | > 4000 durante 2 minutos | > 9000 durante 5 minutos | Supervisar si las IOPS del disco se acercan al máximo aprovisionamiento de IOPS. Determinar si el clúster puede gestionar cargas de trabajo futuras. |
Latencia de lectura | > 20ms por 5 minutos | > 50 s por 5 minutos | Supervisa la latencia del disco para rastrear la eficiencia de leer y escribir en el disco. |
Latencia de guardar | > 20ms por 5 minutos | > 50ms durante más de 5 minutos | Supervisa la latencia del disco para rastrear la eficiencia de leer y escribir en el disco. |
Uso de intercambio | > 2GB por 15 minutos | > 2GB por 15 minutos | Supervisa la memoria para determinar si debes actualizar a un nivel de clúster superior. Esta métrica representa el valor promedio durante el período de tiempo especificado por la granularidad de la métrica. |
Host caído | minutos de 15 | 24 horas | Monitorea tus hosts para detectar tiempos de inactividad rápidamente. Un host inactivo durante más de 15 minutos puede afectar la disponibilidad, mientras que un tiempo de inactividad superior a 24 horas es crítico, poniendo en riesgo la accesibilidad a los datos y el rendimiento de las aplicaciones. |
Sin primario | 5 minutos | 5 minutos | Supervisa el estado de tus set de réplicas para identificar instancias donde no haya un nodo primario. La falta de un primario durante más de 5 minutos puede detener las operaciones de escritura y afectar la funcionalidad de la aplicación. |
Falta activo | minutos de 15 | minutos de 15 | Supervise el estado de los procesos |
Errores de página | > 50/segundo durante 5 minutos | > 100/segundo durante 5 minutos | Supervisa los fallos de página para determinar si debes aumentar tu memoria. Esta métrica muestra la tasa promedio de fallos de página en este proceso por segundo durante el período de muestra seleccionado. En entornos distintos de Windows esto solo se aplica a fallos de página graves. |
atraso de la replicación | > 240 segundo durante 5 minutos | > 1 horas con 5 minutos | Supervisa el atraso de la replicación para determinar si el secundario podría caerse del oplog. |
Copia de seguridad fallida | Cualquier ocurrencia | Ninguno | Rastrea las operaciones de copia de seguridad para garantizar la integridad de los datos. Una copia de seguridad fallida puede comprometer la disponibilidad de datos. |
Copia de seguridad restaurada | Cualquier ocurrencia | Ninguno | Verificar las copias de seguridad restauradas para garantizar la integridad de los datos y el funcionamiento del sistema. |
La snapshot de fallback falló | Cualquier ocurrencia | Ninguno | Supervisa las operaciones de recuperación de snapshots de respaldo para garantizar la redundancia de los datos y la capacidad de recuperación. |
Cronograma de copia de seguridad retrasada | > 12 horas | > 12 horas | Comprueba los cronogramas de copia de seguridad para asegurarte de que están en marcha. Quedarse atrás puede arriesgarse a la pérdida de datos y comprometer los planes de recuperación. |
Lecturas en cola | > 0-10 | > 10+ | Supervisa las lecturas en cola para asegurar una recuperación de datos eficiente. Altos niveles de lecturas en cola pueden indicar restricciones de recursos o cuellos de botella en el rendimiento, requiriendo optimización para mantener la capacidad de respuesta del sistema. |
Escrituras en cola | > 0-10 | > 10+ | Supervise las escrituras en cola para mantener un procesamiento eficiente de los datos. Los niveles altos de guardados en cola pueden indicar restricciones de recursos o cuellos de botella en el rendimiento, lo que requiere optimización para mantener la capacidad de respuesta del sistema. |
Reinicios última hora | > 2 | > 2 | Realice un seguimiento del número de reinicios en la última hora para detectar inestabilidad o problemas de configuración. Los reinicios frecuentes pueden indicar problemas subyacentes que requieren una investigación inmediata para mantener la fiabilidad y el tiempo de actividad del sistema. |
Cualquier ocurrencia | Ninguno | Supervise las elecciones primarias para asegurar operaciones estables del clúster. Las elecciones frecuentes pueden indicar problemas de red o restricciones de recursos, lo que podría afectar la disponibilidad y el rendimiento de la base de datos. | |
Mantenimiento ya no necesario | Cualquier ocurrencia | Ninguno | Revisa tareas de mantenimiento innecesarias para optimizar recursos y minimizar interrupciones. |
Mantenimiento iniciado | Cualquier ocurrencia | Ninguno | Monitoree el inicio de las tareas de mantenimiento para garantizar que las actividades planificadas se desarrollen sin problemas. Una supervisión adecuada ayuda a mantener el rendimiento del sistema y a minimizar el tiempo de inactividad durante el mantenimiento. |
Mantenimiento programado | Cualquier ocurrencia | Ninguno | Supervise el mantenimiento programado para prepararse ante posibles impactos en el sistema. |
> 5% durante 5 minutos | > 20% durante 5 minutos | Supervise el robo de CPU en los clústeres de AWS EC2 con Rendimiento Aumentable para identificar cuándo el uso de CPU supera la línea base garantizada debido a núcleos compartidos. Los altos porcentajes de robo indican que el saldo de créditos de CPU está agotado, lo que afecta el rendimiento. | |
CPU | > 75% durante 5 minutos | > 75% durante 5 minutos | Supervisa el uso de la CPU para determinar si los datos se recuperan del disco en lugar de la memoria. |
Uso de la partición del disco | > 90% | > 95% durante 5 minutos | Supervisar el uso de la partición de disco para garantizar la disponibilidad suficiente de almacenamiento. Los altos niveles de uso pueden conducir a una degradación del rendimiento y posibles interrupciones del servicio. |
Para obtener más información, consulta Configura y resuelve alertas.
Monitoreo mediante herramientas integradas de Atlas
Atlas proporciona varias herramientas que le permiten supervisar y mejorar de forma proactiva el rendimiento de su base de datos.
Panel de rendimiento en tiempo real
El Real-Time Performance Panel (RTPP) en la Interfaz de Usuario de Atlas proporciona perspectivas sobre el tráfico actual de la red, las operaciones de la base de datos y estadísticas de hardware sobre los hosts a una granularidad de un segundo en la Interfaz de Usuario de Atlas. Recomendamos utilizar RTPP para:
Identificar visualmente las operaciones relevantes de la base de datos.
Evalúe los tiempos de ejecución de las consultas
Evaluar la proporción de documentos escaneados frente a documentos devueltos
Supervisar la carga y el rendimiento de la red
Descubre una posible atraso de la replicación en los miembros secundarios de conjuntos de réplicas
Cancelar las operaciones antes de que se completen para liberar recursos valiosos.
El RTPP no está disponible para supervisar desde la API de Administración de Atlas, pero puedes activar y desactivar el RTPP desde la API de Administración de Atlas con Actualizar la configuración de un proyecto.
Para obtener más información, consulte Supervisar el rendimiento en tiempo real.
Perfilador de la query
El Query Profiler identifica las consultas lentas y los cuellos de botella, y sugiere el perfeccionamiento de índices y la reestructuración de consultas para mejorar el rendimiento de la base de datos. Proporciona visibilidad de las operaciones más lentas durante una ventana de 24horas en la Interfaz de Usuario de Atlas, facilitando la identificación de tendencias y valores atípicos en la eficiencia de las queries. Te recomendamos que utilices estos datos para detectar y solucionar consultas con bajo rendimiento, reduciendo la sobrecarga de rendimiento.
Puedes devolver líneas de registro para queries lentas que el perfilador del query identifica desde la API de administración de Atlas con Devolver queries lentas.
Para obtener más información, consulte Supervise el rendimiento de las query con el perfilador del query.
Performance Advisor
El Asesor de Rendimiento analiza automáticamente los registros para detectar consultas lentas y recomienda crear y eliminar índices. Analiza las consultas lentas y ofrece sugerencias de índices para colecciones individuales, clasificadas según una puntuación de impacto calculada y adaptadas a su carga de trabajo. Esto le ofrece una forma sencilla e instantánea de implementar mejoras de rendimiento significativas. Le recomendamos que supervise periódicamente, se centre en las consultas lentas y active el generador de perfiles de forma selectiva para minimizar la sobrecarga.
Puedes usar la Interfaz de Usuario de Atlas, la Atlas CLI y la API de administración de Atlas para ver slow queries y sugerencias para mejorar el rendimiento de tus queries del Performance Advisor.
Puedes devolver las líneas del registro para las slow queries que el Performance Advisor identifica desde la API de Administración de Atlas con Return Slow Queries. Para devolver los índices sugeridos y más con la API de administración Atlas, consulta Performance Advisor.
Para aprender más, consulta Supervisar y mejorar queries lentas con el Performance Advisor.
Namespace Insights
La página Información del espacio de nombres en la interfaz de usuario de Atlas le permite supervisar el rendimiento y las métricas de uso a nivel de colección. Muestra métricas (como el número de operaciones CRUD en la colección) y estadísticas (como el tiempo promedio de ejecución de consultas) para ciertos hosts y tipos de operaciones de las colecciones que ha fijado para su supervisión. Esto le proporciona una visibilidad más detallada del rendimiento a nivel de colección, que puede utilizar para optimizar el rendimiento de la base de datos, resolver problemas y tomar decisiones sobre el escalado, la indexación y el ajuste de consultas.
Para aprender más, consulta Supervisa la latencia de las query a nivel de colección con Namespace Insights.
Fuente de actividad
La fuente de actividad de la organización y la fuente de actividad del proyecto en la Interfaz de Usuario de Atlas enumeran todos los eventos que se producen para una organización o proyecto de Atlas determinados, respectivamente. Puedes filtrar cada fuente de actividad por tipo de evento y rango de tiempo para supervisar eventos como actualizaciones de acceso a la API, cambios en la configuración de alertas, y más. Esto le permite revisar los registros de actividad de su organización o proyecto con el nivel de profundidad que desee.
Utilice la interfaz de usuario de Atlas, la CLI de Atlas y la API de administración de Atlas para recuperar eventos de cada fuente de actividad. Para obtener más información, consulte Ver fuente de actividad.
Supervise usando registros
Atlas conserva los últimos 30 días de mensajes de registro y de auditoría de eventos del sistema. Puede descargar los registros de Atlas en cualquier momento hasta el final de sus periodos de retención mediante la interfaz de usuario de Atlas, la API de administración de Atlas y la CLI de Atlas.
Para obtener más información, se debe consultar Ver y descargar los registros de MongoDB.
También puede exportar registros a un bucket AWS S3 . Cuando se configura esta funcionalidad, Atlas exporta desde mongod, mongos y los registros de auditoría a un bucket S3 de AWS cada minuto.
Ejemplos de automatización: supervisión y registro de Atlas
Los siguientes ejemplos demuestran cómo habilitar la supervisión usando Atlas herramientas para automatización.
Ver métricas de clúster
Ejecute el siguiente comando para recuperar la cantidad de espacio utilizado y libre en el disco especificado. Esta métrica se puede utilizar para determinar si el sistema se está quedando sin espacio libre.
atlas metrics disks describe atlas-lnmtkm-shard-00-00.ajlj3.mongodb.net:27017 data \ --granularity P1D \ --period P1D \ --type DISK_PARTITION_SPACE_FREE,DISK_PARTITION_SPACE_USED \ --projectId 6698000acf48197e089e4085 \
Configurar alertas
Ejecuta el siguiente comando para crear una notificación de alerta a una dirección de correo electrónico cuando tu implementación no tenga una primaria.
atlas alerts settings create \ --enabled \ --event "NO_PRIMARY" \ --matcherFieldName CLUSTER_NAME \ --matcherOperator EQUALS \ --matcherValue ftsTest \ --notificationType EMAIL \ --notificationEmailEnabled \ --notificationEmailAddress "myName@example.com" \ --notificationIntervalMin 5 \ --projectId 6698000acf48197e089e4085
Supervisar el rendimiento de la base de datos
Ejecute el siguiente comando para activar el umbral de operaciones lentas gestionadas por Atlas para tu proyecto.
atlas performanceAdvisor slowOperationThreshold enable --projectId 56fd11f25f23b33ef4c2a331
Descargar registros
Ejecuta el siguiente comando para descargar un archivo comprimido que contiene los registros de MongoDB para el host especificado en tu proyecto.
atlas logs download cluster0-shard-00-00.a1b2c.mongodb.net mongodb.gz
Vea todos los ejemplos del SDK de Go del Atlas Architecture Center en un solo proyecto en el repo de GitHub del SDK de Go de Atlas Architecture.
Antes de poder autenticarse y ejecutar los scripts de ejemplo utilizando el SDK Atlas Go, debe:
Crea una cuenta de servicio de Atlas. Almacena tu ID y secreto de cliente como variables de entorno ejecutando el siguiente comando en la terminal:
export MONGODB_ATLAS_SERVICE_ACCOUNT_ID="<insert your client ID here>" export MONGODB_ATLAS_SERVICE_ACCOUNT_SECRET="<insert your client secret here>" Establezca las siguientes variables de configuración en su proyecto de Go:
configs/config.json{ "MONGODB_ATLAS_BASE_URL": "https://cloud.mongodb.com", "ATLAS_ORG_ID": "32b6e34b3d91647abb20e7b8", "ATLAS_PROJECT_ID": "67212db237c5766221eb6ad9", "ATLAS_CLUSTER_NAME": "myCluster", "ATLAS_PROCESS_ID": "myCluster-shard-00-00.ajlj3.mongodb.net:27017" }
Ver métricas de clúster
El siguiente script de ejemplo muestra cómo recuperar la cantidad de espacio usado y libre en el disco especificado. Esta métrica permite determinar si el sistema se está quedando sin espacio libre.
// See entire project at https://github.com/mongodb/atlas-architecture-go-sdk package main import ( "context" "encoding/json" "fmt" "log" "atlas-sdk-examples/internal/auth" "atlas-sdk-examples/internal/config" "atlas-sdk-examples/internal/metrics" "github.com/joho/godotenv" "go.mongodb.org/atlas-sdk/v20250219001/admin" ) func main() { envFile := ".env.development" if err := godotenv.Load(envFile); err != nil { log.Printf("Warning: could not load %s file: %v", envFile, err) } secrets, cfg, err := config.LoadAllFromEnv() if err != nil { log.Fatalf("Failed to load configuration %v", err) } ctx := context.Background() client, err := auth.NewClient(ctx, cfg, secrets) if err != nil { log.Fatalf("Failed to initialize authentication client: %v", err) } // Fetch disk metrics with the provided parameters p := &admin.GetDiskMeasurementsApiParams{ GroupId: cfg.ProjectID, ProcessId: cfg.ProcessID, PartitionName: "data", M: &[]string{"DISK_PARTITION_SPACE_FREE", "DISK_PARTITION_SPACE_USED"}, Granularity: admin.PtrString("P1D"), Period: admin.PtrString("P1D"), } view, err := metrics.FetchDiskMetrics(ctx, client.MonitoringAndLogsApi, p) if err != nil { log.Fatalf("Failed to fetch disk metrics: %v", err) } // Output metrics out, err := json.MarshalIndent(view, "", " ") if err != nil { log.Fatalf("Failed to format metrics data: %v", err) } fmt.Println(string(out)) }
Descargar registros
El siguiente script de ejemplo demuestra cómo descargar y descomprimir un archivo comprimido que contiene los registros de MongoDB para el host especificado en su proyecto Atlas:
// See entire project at https://github.com/mongodb/atlas-architecture-go-sdk package main import ( "context" "fmt" "log" "atlas-sdk-examples/internal/auth" "atlas-sdk-examples/internal/config" "atlas-sdk-examples/internal/fileutils" "atlas-sdk-examples/internal/logs" "github.com/joho/godotenv" "go.mongodb.org/atlas-sdk/v20250219001/admin" ) func main() { envFile := ".env.production" if err := godotenv.Load(envFile); err != nil { log.Printf("Warning: could not load %s file: %v", envFile, err) } secrets, cfg, err := config.LoadAllFromEnv() if err != nil { log.Fatalf("Failed to load configuration %v", err) } ctx := context.Background() client, err := auth.NewClient(ctx, cfg, secrets) if err != nil { log.Fatalf("Failed to initialize authentication client: %v", err) } // Fetch logs with the provided parameters p := &admin.GetHostLogsApiParams{ GroupId: cfg.ProjectID, HostName: cfg.HostName, LogName: "mongodb", } fmt.Printf("Request parameters: GroupID=%s, HostName=%s, LogName=%s\n", cfg.ProjectID, cfg.HostName, p.LogName) rc, err := logs.FetchHostLogs(ctx, client.MonitoringAndLogsApi, p) if err != nil { log.Fatalf("Failed to fetch logs: %v", err) } defer fileutils.SafeClose(rc) // Prepare output paths // If the ATLAS_DOWNLOADS_DIR env variable is set, it will be used as the base directory for output files outDir := "logs" prefix := fmt.Sprintf("%s_%s", p.HostName, p.LogName) gzPath, err := fileutils.GenerateOutputPath(outDir, prefix, "gz") if err != nil { log.Fatalf("Failed to generate GZ output path: %v", err) } txtPath, err := fileutils.GenerateOutputPath(outDir, prefix, "txt") if err != nil { log.Fatalf("Failed to generate TXT output path: %v", err) } // Save compressed logs if err := fileutils.WriteToFile(rc, gzPath); err != nil { log.Fatalf("Failed to save compressed logs: %v", err) } fmt.Println("Saved compressed log to", gzPath) // Decompress logs if err := fileutils.DecompressGzip(gzPath, txtPath); err != nil { log.Fatalf("Failed to decompress logs: %v", err) } fmt.Println("Uncompressed log to", txtPath) }
Tip
Para ejemplos de Terraform que aplican nuestras recomendaciones en todos los pilares, consulta uno de los siguientes ejemplos en GitHub:
Antes de poder crear recursos con Terraform, debe:
Crea tu organización pagadora y crea una clave de API para la organización pagadora. Almacena tu clave API como variables de entorno ejecutando el siguiente comando en la terminal:
export MONGODB_ATLAS_PUBLIC_KEY="<insert your public key here>" export MONGODB_ATLAS_PRIVATE_KEY="<insert your private key here>"
También recomendamos crear un espacio de trabajo para tu entorno.
Configurar alertas
Los siguientes ejemplos demuestran cómo configurar alertas y notificaciones de alertas. Debe crear los siguientes archivos para cada ejemplo. Coloca los archivos de cada ejemplo en su propio directorio. Cambie los IDs y nombres para usar sus valores:
variables.tf
variable "atlas_org_id" { type = string description = "MongoDB Atlas Organization ID" } variable "atlas_project_name" { type = string description = "The MongoDB Atlas Project Name" } variable "atlas_project_id" { description = "MongoDB Atlas project id" type = string } variable "atlas_cluster_name" { description = "MongoDB Atlas Cluster Name" default = "datadog-test-cluster" type = string }
terraform.tfvars
atlas_org_id = "32b6e34b3d91647abb20e7b8" atlas_project_name = "Customer Portal - Prod" atlas_project_id = "67212db237c5766221eb6ad9" atlas_cluster_name = "myCluster"
ejemplo: Utilice lo siguiente para enviar una notificación de alerta por correo electrónico a los usuarios con el rol GROUP_CLUSTER_MANAGER cuando haya un atraso de la replicación, lo que podría resultar en inconsistencias de datos.
main.tf
resource "mongodbatlas_alert_configuration" "test" { project_id = var.atlas_project_id event_type = "REPLICATION_OPLOG_WINDOW_RUNNING_OUT" enabled = true notification { type_name = "GROUP" interval_min = 10 delay_min = 0 sms_enabled = false email_enabled = true roles = ["GROUP_CLUSTER_MANAGER"] } matcher { field_name = "CLUSTER_NAME" operator = "EQUALS" value = "myCluster" } threshold_config { operator = "LESS_THAN" threshold = 1 units = "HOURS" } }
Ver métricas de clúster
Ejecuta el comando de muestra para recuperar las siguientes métricas:
OPCOUNTERS: supervisa la cantidad de consultas, actualizaciones, inserciones y eliminaciones que ocurren durante la carga máxima y garantiza que la carga no aumente inesperadamente.
CONEXIONES - Asegúrese de que la cantidad de sockets utilizados para los latidos y la replicación entre miembros no supere el límite establecido.
ORIENTACIÓN DE CONSULTAS: asegúrese de que la cantidad de claves y documentos escaneados en relación con la cantidad de documentos devueltos, promediados por segundo, no sean demasiado altos.
CPU DEL SISTEMA: asegúrese de que el uso de la CPU sea estable.
COLA DE BLOQUEO GLOBAL - Supervisa la cantidad de operaciones de lectura y escritura que están actualmente en la cola y esperando por el bloqueo de lectura y escritura, y asegúrate de que la carga no aumente inesperadamente.
atlas metrics processes atlas-lnmtkm-shard-00-00.ajlj3.mongodb.net:27017 \ --projectId 56fd11f25f23b33ef4c2a331 \ --granularity PT1H \ --period P7D \ --type OPCOUNTER_DELETE,OPCOUNTER_INSERT,OPCOUNTER_QUERY,OPCOUNTER_UPDATE,CONNECTIONS,QUERY_TARGETING_SCANNED_OBJECTS_PER_RETURNED,QUERY_TARGETING_SCANNED_PER_RETURNED,SYSTEM_CPU_GUEST,SYSTEM_CPU_IOWAIT,SYSTEM_CPU_IRQ,SYSTEM_CPU_KERNEL,SYSTEM_CPU_NICE,SYSTEM_CPU_SOFTIRQ,SYSTEM_CPU_STEAL,SYSTEM_CPU_USER,GLOBAL_LOCK_CURRENT_QUEUE_TOTAL,GLOBAL_LOCK_CURRENT_QUEUE_READERS,GLOBAL_LOCK_CURRENT_QUEUE_WRITERS \ --output json
Configurar alertas
Ejecute el siguiente comando para enviar alertas a un grupo por correo electrónico cuando haya posibles tormentas de conexiones en función del número de conexiones en su proyecto.
atlas alerts settings create \ --enabled \ --event "OUTSIDE_METRIC_THRESHOLD" \ --metricName CONNECTIONS \ --metricOperator LESS_THAN \ --metricThreshold 1 \ --metricUnits RAW \ --notificationType GROUP \ --notificationRole "GROUP_DATA_ACCESS_READ_ONLY","GROUP_CLUSTER_MANAGER","GROUP_DATA_ACCESS_ADMIN" \ --notificationEmailEnabled \ --notificationEmailAddress "user@example.com" \ --notificationIntervalMin 5 \ --projectId 6698000acf48197e089e4085
Supervisar el rendimiento de la base de datos
Ejecute el siguiente comando para recuperar los índices sugeridos para las colecciones que experimentan consultas lentas.
atlas performanceAdvisor suggestedIndexes list \ --projectId 56fd11f25f23b33ef4c2a331 \ --processName atlas-zqva9t-shard-00-02.2rnul.mongodb.net:27017
Descargar registros
Ejecuta el siguiente comando para descargar un archivo comprimido que contiene los registros de MongoDB para el host especificado en tu proyecto.
atlas logs download cluster0-shard-00-00.a1b2c.mongodb.net mongodb.gz
Consulta todos los ejemplos de Atlas Architecture Center Go SDK en un único proyecto en el repositorio de Atlas Architecture Go SDK en GitHub.
Antes de poder autenticarse y ejecutar los scripts de ejemplo utilizando el SDK Atlas Go, debe:
Crea una cuenta de servicio de Atlas. Almacena tu ID y secreto de cliente como variables de entorno ejecutando el siguiente comando en la terminal:
export MONGODB_ATLAS_SERVICE_ACCOUNT_ID="<insert your client ID here>" export MONGODB_ATLAS_SERVICE_ACCOUNT_SECRET="<insert your client secret here>" Establezca las siguientes variables de configuración en su proyecto de Go:
configs/config.json{ "MONGODB_ATLAS_BASE_URL": "https://cloud.mongodb.com", "ATLAS_ORG_ID": "32b6e34b3d91647abb20e7b8", "ATLAS_PROJECT_ID": "67212db237c5766221eb6ad9", "ATLAS_CLUSTER_NAME": "myCluster", "ATLAS_PROCESS_ID": "myCluster-shard-00-00.ajlj3.mongodb.net:27017" }
Para obtener más información sobre cómo autenticar y crear un cliente, consulte el proyecto de ejemplo completo Atlas SDK para Go en GitHub.
Ver métricas de clúster
El siguiente script de ejemplo demuestra cómo recuperar las siguientes métricas:
OPCOUNTERS: supervisa la cantidad de consultas, actualizaciones, inserciones y eliminaciones que ocurren durante la carga máxima y garantiza que la carga no aumente inesperadamente.
CONEXIONES - Asegúrese de que la cantidad de sockets utilizados para los latidos y la replicación entre miembros no supere el límite establecido.
ORIENTACIÓN DE CONSULTAS: asegúrese de que la cantidad de claves y documentos escaneados en relación con la cantidad de documentos devueltos, promediados por segundo, no sean demasiado altos.
CPU DEL SISTEMA: asegúrese de que el uso de la CPU sea estable.
COLA DE BLOQUEO GLOBAL - Supervisa la cantidad de operaciones de lectura y escritura que están actualmente en la cola y esperando por el bloqueo de lectura y escritura, y asegúrate de que la carga no aumente inesperadamente.
// See entire project at https://github.com/mongodb/atlas-architecture-go-sdk package main import ( "context" "encoding/json" "fmt" "log" "atlas-sdk-examples/internal/auth" "atlas-sdk-examples/internal/config" "atlas-sdk-examples/internal/metrics" "github.com/joho/godotenv" "go.mongodb.org/atlas-sdk/v20250219001/admin" ) func main() { envFile := ".env.production" if err := godotenv.Load(envFile); err != nil { log.Printf("Warning: could not load %s file: %v", envFile, err) } secrets, cfg, err := config.LoadAllFromEnv() if err != nil { log.Fatalf("Failed to load configuration %v", err) } ctx := context.Background() client, err := auth.NewClient(ctx, cfg, secrets) if err != nil { log.Fatalf("Failed to initialize authentication client: %v", err) } // Fetch process metrics with the provided parameters p := &admin.GetHostMeasurementsApiParams{ GroupId: cfg.ProjectID, ProcessId: cfg.ProcessID, M: &[]string{ "OPCOUNTER_INSERT", "OPCOUNTER_QUERY", "OPCOUNTER_UPDATE", "TICKETS_AVAILABLE_READS", "TICKETS_AVAILABLE_WRITE", "CONNECTIONS", "QUERY_TARGETING_SCANNED_OBJECTS_PER_RETURNED", "QUERY_TARGETING_SCANNED_PER_RETURNED", "SYSTEM_CPU_GUEST", "SYSTEM_CPU_IOWAIT", "SYSTEM_CPU_IRQ", "SYSTEM_CPU_KERNEL", "SYSTEM_CPU_NICE", "SYSTEM_CPU_SOFTIRQ", "SYSTEM_CPU_STEAL", "SYSTEM_CPU_USER", }, Granularity: admin.PtrString("PT1H"), Period: admin.PtrString("P7D"), } view, err := metrics.FetchProcessMetrics(ctx, client.MonitoringAndLogsApi, p) if err != nil { log.Fatalf("Failed to fetch process metrics: %v", err) } // Output metrics out, err := json.MarshalIndent(view, "", " ") if err != nil { log.Fatalf("Failed to format metrics data: %v", err) } fmt.Println(string(out)) }
Descargar registros
El siguiente script de ejemplo demuestra cómo descargar y descomprimir un archivo comprimido que contiene los registros de MongoDB para el host especificado en su proyecto Atlas:
// See entire project at https://github.com/mongodb/atlas-architecture-go-sdk package main import ( "context" "fmt" "log" "atlas-sdk-examples/internal/auth" "atlas-sdk-examples/internal/config" "atlas-sdk-examples/internal/fileutils" "atlas-sdk-examples/internal/logs" "github.com/joho/godotenv" "go.mongodb.org/atlas-sdk/v20250219001/admin" ) func main() { envFile := ".env.production" if err := godotenv.Load(envFile); err != nil { log.Printf("Warning: could not load %s file: %v", envFile, err) } secrets, cfg, err := config.LoadAllFromEnv() if err != nil { log.Fatalf("Failed to load configuration %v", err) } ctx := context.Background() client, err := auth.NewClient(ctx, cfg, secrets) if err != nil { log.Fatalf("Failed to initialize authentication client: %v", err) } // Fetch logs with the provided parameters p := &admin.GetHostLogsApiParams{ GroupId: cfg.ProjectID, HostName: cfg.HostName, LogName: "mongodb", } fmt.Printf("Request parameters: GroupID=%s, HostName=%s, LogName=%s\n", cfg.ProjectID, cfg.HostName, p.LogName) rc, err := logs.FetchHostLogs(ctx, client.MonitoringAndLogsApi, p) if err != nil { log.Fatalf("Failed to fetch logs: %v", err) } defer fileutils.SafeClose(rc) // Prepare output paths // If the ATLAS_DOWNLOADS_DIR env variable is set, it will be used as the base directory for output files outDir := "logs" prefix := fmt.Sprintf("%s_%s", p.HostName, p.LogName) gzPath, err := fileutils.GenerateOutputPath(outDir, prefix, "gz") if err != nil { log.Fatalf("Failed to generate GZ output path: %v", err) } txtPath, err := fileutils.GenerateOutputPath(outDir, prefix, "txt") if err != nil { log.Fatalf("Failed to generate TXT output path: %v", err) } // Save compressed logs if err := fileutils.WriteToFile(rc, gzPath); err != nil { log.Fatalf("Failed to save compressed logs: %v", err) } fmt.Println("Saved compressed log to", gzPath) // Decompress logs if err := fileutils.DecompressGzip(gzPath, txtPath); err != nil { log.Fatalf("Failed to decompress logs: %v", err) } fmt.Println("Uncompressed log to", txtPath) }
Tip
Para ejemplos de Terraform que aplican nuestras recomendaciones en todos los pilares, consulta uno de los siguientes ejemplos en GitHub:
Antes de poder crear recursos con Terraform, debe:
Crea tu organización pagadora y crea una clave de API para la organización pagadora. Almacena tu clave API como variables de entorno ejecutando el siguiente comando en la terminal:
export MONGODB_ATLAS_PUBLIC_KEY="<insert your public key here>" export MONGODB_ATLAS_PRIVATE_KEY="<insert your private key here>"
También recomendamos crear un espacio de trabajo para tu entorno.
Configurar alertas
Los siguientes ejemplos demuestran cómo configurar alertas y notificaciones de alertas. Debe crear los siguientes archivos para cada ejemplo. Coloca estos archivos para cada ejemplo en su propio directorio y reemplaza solo el archivo main.tf. Cambie los IDs y nombres para usar sus valores:
variables.tf
variable "atlas_org_id" { type = string description = "MongoDB Atlas Organization ID" } variable "atlas_project_name" { type = string description = "The MongoDB Atlas Project Name" } variable "atlas_project_id" { description = "MongoDB Atlas project id" type = string } variable "atlas_cluster_name" { description = "MongoDB Atlas Cluster Name" default = "datadog-test-cluster" type = string } variable "datadog_api_key" { description = "Datadog api key" type = string } variable "datadog_region" { description = "Datadog region" default = "US5" type = string } variable "prometheus_user_name" { type = string description = "The Prometheus User Name" default = "puser" } variable "prometheus_password" { type = string description = "The Prometheus Password" default = "ppassword" }
terraform.tfvars
atlas_org_id = "32b6e34b3d91647abb20e7b8" atlas_project_name = "Customer Portal - Prod" atlas_project_id = "67212db237c5766221eb6ad9" atlas_cluster_name = "myCluster" datadog_api_key = "1234567890abcdef1234567890abcdef" datadog_region = "US5" prometheus_user_name = "prometheus_user" prometheus_password = "secure_prometheus_password"
1Ejemplo: utilice lo siguiente para integrarse con servicios de terceros como Datadog y Prometheus para notificaciones de alertas.
main.tf
resource "mongodbatlas_third_party_integration" "test_datadog" { project_id = var.atlas_project_id type = "DATADOG" api_key = var.datadog_api_key region = var.datadog_region } resource "mongodbatlas_third_party_integration" "test_prometheus" { project_id = var.atlas_project_id type = "PROMETHEUS" user_name = var.prometheus_user_name password = var.prometheus_password service_discovery = "http" enabled = true } output "datadog.id" { value = mongodbatlas_third_party_integration.test_datadog.id } output "prometheus.id" { value = mongodbatlas_third_party_integration.test_prometheus.id }
Ejemplo 2: Use lo siguiente para enviar una notificación de alerta a servicios de terceros como DataDog y Prometheus cuando no haya un nodo principal en el set de réplicas durante más de 5 minutos.
main.tf
resource "mongodbatlas_alert_configuration" "test_alert_notification" { project_id = var.atlas_project_id event_type = "NO_PRIMARY" enabled = true notification { type_name = "PROMETHEUS" integration_id = mongodbatlas_third_party_integration.test_datadog.id # ID of the Atlas Prometheus integration } notification { type_name = "DATADOG" integration_id = mongodbatlas_third_party_integration.test_prometheus.id # ID of the Atlas Datadog integration } matcher { field_name = "REPLICA_SET_NAME" operator = "EQUALS" value = "myReplSet" } threshold_config { operator = "GREATER_THAN" threshold = 5 units = "MINUTES" } }
ejemplo 3: Usa lo siguiente para enviar una notificación de alerta por correo electrónico a los usuarios con el rol GROUP_CLUSTER_MANAGER cuando haya un atraso de la replicación, lo que podría resultar en inconsistencias de datos.
main.tf
resource "mongodbatlas_alert_configuration" "test_replication_lag_alert" { project_id = var.atlas_project_id event_type = "OUTSIDE_METRIC_THRESHOLD" enabled = true notification { type_name = "GROUP" interval_min = 10 delay_min = 0 sms_enabled = false email_enabled = true roles = ["GROUP_CLUSTER_MANAGER"] } matcher { field_name = "CLUSTER_NAME" operator = "EQUALS" value = "myCluster" } metric_threshold_config { metric_name = "OPLOG_SLAVE_LAG_MASTER_TIME" operator = "GREATER_THAN" threshold = 1 units = "HOURS" } }