Atlas Device Sync utiliza espacio en el clúster Atlas sincronizado de tu aplicación para almacenar metadatos para la sincronización. Esto incluye un historial de cambios en cada base de datos sincronizada. Atlas App Services minimiza este uso de espacio en tu clúster Atlas. Minimizar los metadatos es necesario para reducir el tiempo y los datos necesarios para la sincronización.
Historia
El backend de App Services mantiene un historial de cambios en los datos subyacentes para cada ámbito, similar al Registro de operaciones de MongoDB. App Services utiliza este historial para sincronizar datos entre el backend y los clientes. App Services almacena el historial en el clúster Atlas sincronizado.
Guarnición
When you set a client maximum offline time in an App, trimming deletes changes older than the client maximum offline time.
Tiempo máximo sin conexión del cliente
Utilizado en el recorte, el tiempo máximo sin conexión del cliente controla el límite de antigüedad del historial. Esto modifica indirectamente el tiempo que un cliente puede permanecer sin conexión entre sesiones de sincronización con el backend. Los clientes que no se sincronizan durante más de la cantidad de días especificada podrían experimentar un reinicio la próxima vez que se conecten al backend.
Si se establece un valor menor para el tiempo máximo sin conexión del cliente, se reducirá la cantidad de historial requerido para la sincronización. La optimización resultante reduce el uso de almacenamiento en el clúster Atlas sincronizado.
Las aplicaciones nuevas habilitan automáticamente el tiempo máximo sin conexión del cliente con un valor por defecto de 30 días.
Advertencia
El tiempo máximo sin conexión del cliente provoca cambios permanentes en el historial
El tiempo máximo sin conexión del cliente permite recortar el historial anterior. Esto modifica permanentemente el historial afectado y puede provocar reinicios del cliente en el futuro.
Conceptos clave
La sincronización debe siempre converger en el mismo estado final en todos los clientes. Para poder converger durante una sincronización, los clientes necesitan el historial completo de cambios a partir de inmediatamente después de su última sincronización. Cuando un cliente no se sincroniza durante mucho tiempo, el recorte puede alterar el historial de formas que impidan que el cliente converja. Dado que la sincronización depende de que todos los clientes converjan en un resultado común, dicho cliente no puede sincronizar.
Como resultado, el cliente debe reiniciarse para poder reanudar la sincronización. En este caso, el cliente elimina la copia local de un dominio y descarga su estado actual desde el backend. La sincronización se reanuda con la nueva copia del dominio.
El tiempo máximo sin conexión del cliente controla el tiempo que el backend espera antes de aplicar el recorte. Tras el número especificado de días sin sincronización, los clientes podrían experimentar un reinicio la próxima vez que se conecten al backend.
Las aplicaciones que no especifican el tiempo máximo de desconexión del cliente nunca aplican recorte. Esto significa que los clientes pueden conectarse después de cualquier período de tiempo sin conexión –semanas, meses o incluso años– y sincronizar cambios. Con el paso del tiempo, los realms editados frecuentemente acumulan muchos cambios. Con un gran conjunto de cambios, la sincronización requiere más tiempo y uso de datos.
El tiempo máximo sin conexión del cliente no influye inmediatamente en los reinicios del cliente
El recorte provoca cambios permanentes e irreversibles en el historial. Por lo tanto, aumentar el tiempo máximo de desconexión del cliente no modifica inmediatamente el tiempo que tarda el cliente en reiniciarse. El recorte ya modificó el historial existente, lo que requiere reiniciar el cliente. El nuevo historial necesita tiempo para acumularse hasta alcanzar el nuevo tiempo máximo de desconexión del cliente.
Reducir el tiempo máximo sin conexión de un cliente no modifica inmediatamente el tiempo que tarda en reiniciarse. Los reinicios comienzan a ocurrir antes una vez que el trabajo de recorte programado regularmente aplica el recorte al historial recién habilitado.
Establecer el tiempo máximo sin conexión del cliente
Desde la interfaz de usuario de App Services, haga clic en Device Sync Menú en la barra lateral. La pestaña Dashboard se muestra por defecto.
Haz clic en la pestaña Configuration.
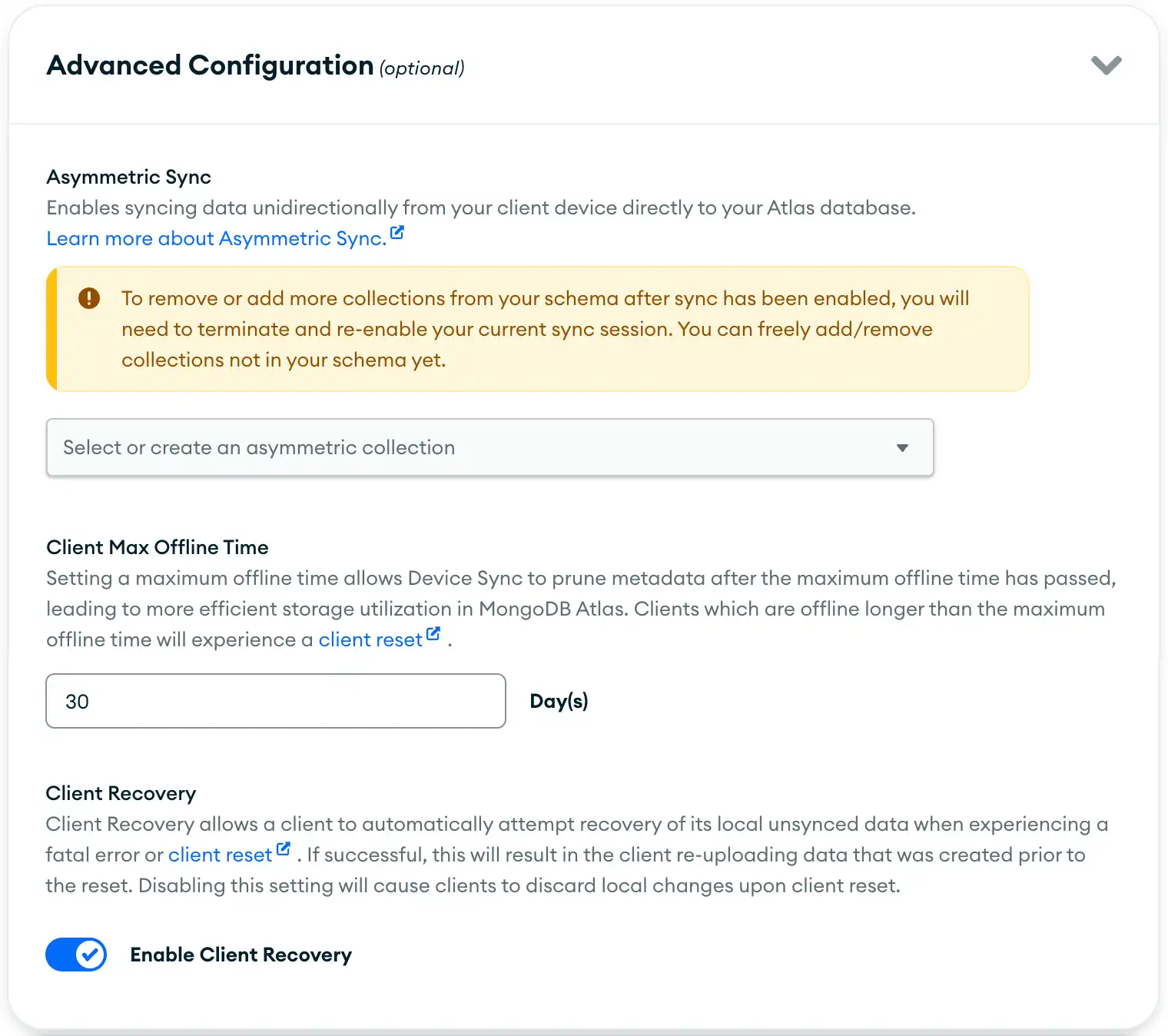
Scroll down to the Advanced Configuration (optional) section, and click the dropdown to expand the section.
![Advanced Configuration section in the App Services UI]()
En la sección Client Max Offline Time, especifique el número de días que el cliente de su aplicación puede permanecer sin conexión. El valor predeterminado es 30 días. El valor mínimo es 1.
Haz clic en el botón Save Changes en la parte inferior de la pantalla una vez que estés listo para guardar.
En la ventana de confirmación, haga clic en el botón Save Changes nuevamente para confirmar los cambios.

Pull a local copy of the latest version of your app with the following pull command:
Tirarappservices pull --remote="<Your App ID>" Puede configurar el número de días que el cliente de su aplicación permanecerá fuera de línea como máximo con el
client_max_offline_dayspropiedad en el archivosync/config.jsonde su aplicación:``sync/config.json``{ "client_max_offline_days": 42, } Implemente la configuración actualizada de la aplicación con el siguiente comando push:
Pushappservices push --remote="<Your App ID>"
Optimización del rendimiento y almacenamiento al utilizar Flexible Sync
For Flexible Sync configuration, the amount of Atlas storage space used is directly proportional to the number of queryable fields you have set up. Queryable fields use storage on the backing Atlas cluster. The more queryable fields you configure, the more storage you use on the backing cluster.
Si tiene una gran cantidad de colecciones en una aplicación, es posible que necesite usar el mismo nombre de campo consultable en varias colecciones. Combine esto con los permisos para obtener un control más preciso sobre quién puede acceder a cada colección.
Ejemplo
Tu aplicación puede contener 20 o 30 colecciones, pero quieres minimizar el número de campos consultables. Puedes reutilizar campos consultables globales en varias colecciones para sincronizar objetos de cada una. Por ejemplo, owner_id podría ser un campo que quieras consultar en varias colecciones.
Alternativamente, puede tener owner_id en varias colecciones, pero solo necesitar consultar query en una colección. En ese caso, podrías hacer que owner_id sea un campo consultable de colección. Esto significa que sincronizar solo tiene que mantener metadatos sobre este campo para una colección, en lugar de almacenar metadatos para todas las colecciones donde no se está realizando una consulta sobre este campo.
Finalmente, para las aplicaciones donde los dispositivos desean consultar una faceta específica de los datos,owner_id == user.id como, se recomienda designar el campo como un campo consultable indexado. Los campos consultables indexados ofrecen un rendimiento más eficiente para las aplicaciones donde el cliente solo necesita sincronizar un pequeño subconjunto de sus datos (por ejemplo, un grupo de tiendas o un solo usuario).
Se puede tener un campo indexado consultable por aplicación. Un campo indexado consultable es un campo global consultable que debe estar presente y usar el mismo tipo de datos elegible en cada colección que se sincronice.
Para obtener más información, consulte Ámbitos de campos consultables y Campos consultables indexados.
For best performance, open a synced realm with a broad query. Then, add more refined queries to expose targeted sets of data in the client application. Slicing off working sets from a broad query provides better performance than opening multiple synced realms using more granular queries.
When you configure queryable fields, consider the broad queries you use for Sync, and select fewer fields that support those broad queries.
Ejemplo
En una aplicación de listas de tareas, priorice consultas generales como assignee == currentUser o projectName == selectedProject para una consulta de sincronización. Esto le proporciona un par de campos generales para sincronizar documentos. En el cliente, puede refinar aún más su consulta para tareas con cierta prioridad o estado de finalización, para desglosar un conjunto de trabajo.
Resumen
Device Sync utiliza espacio en tu clúster sincronizado de Atlas para almacenar el historial de cambios.
Trimming reduces the space usage for Flexible Sync apps, but can cause client resets for clients who have not connected to the backend in more than the client maximum offline time (in days).
Añadir campos consultables adicionales a una configuración de sincronización flexible aumentará el consumo de almacenamiento en un clúster Atlas. Usar consultas amplias y seleccionar menos campos compatibles con ellas reduce el consumo de almacenamiento.