Partitioning (aka sharding)
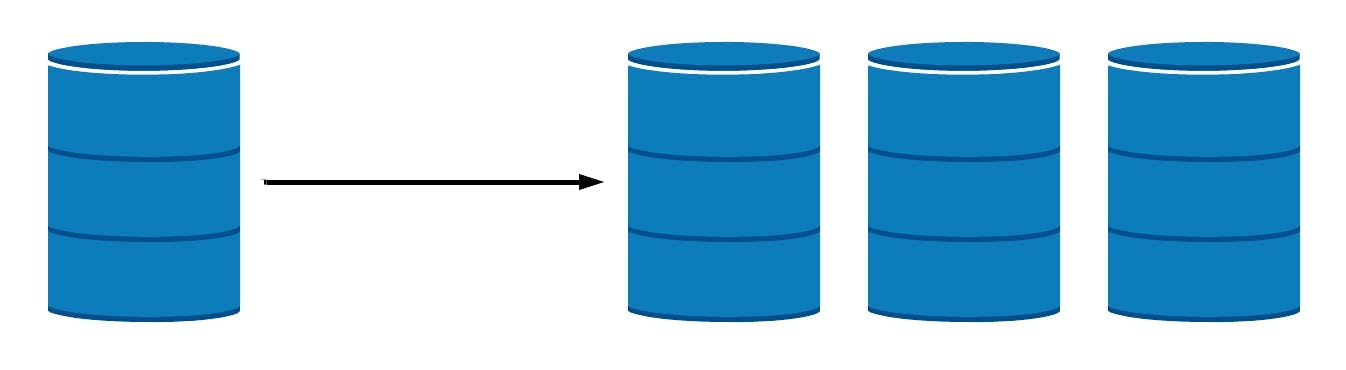
Partitioning distributes data across multiple nodes in a cluster. Each replica set (known in MongoDB as a shard) in a cluster only stores a portion of the data based on a collection sharding key (sharding strategy), which determines the distribution of the data. This makes it possible to scale the storage capacity of the cluster virtually without limit. Since each node is only responsible for processing the data it stores, overall processing capacity for both reads and writes is increased as well.
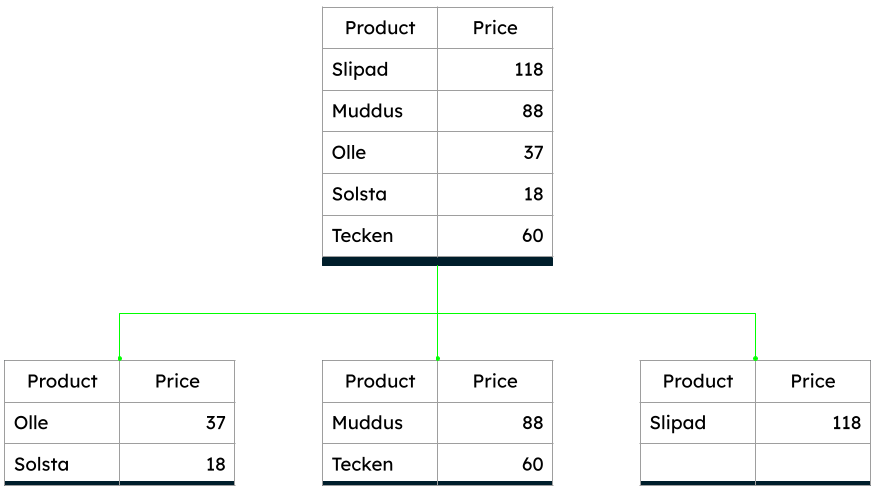
For example, in the illustration below, the data shard data subsets were divided by price range.
However, partitioning is a more complex scaling strategy than replication. Because each node only stores part of the data, for each request, the database queries need to determine which node or nodes contain the relevant data. In MongoDB, the client application connects to a sharded cluster through a router that directs the requests to the appropriate nodes.
If the data is stored across multiple nodes, the reads and writes could be done in parallel. For large-volume data reads, performance is improved because each node can read its section of data in parallel with the other nodes.
There is an overhead to reading from multiple nodes. The data from all the nodes still needs to be transferred over the network and then combined into a query result set. For small data reads, the network latency could be a significant portion of the overall query time. For those scenarios, it's more efficient to query using targeted operations.
MongoDB has the ability to store both sharded and unsharded collections in a sharded cluster. This allows the application to take full advantage of the cluster for large data sets while using a primary shard for small data sets.
The easiest, most convenient, and most cost-effective way to deploy and manage a sharded cluster is via MongoDB Atlas, the Developer Data Platform that simplifies sharded cluster implementation.