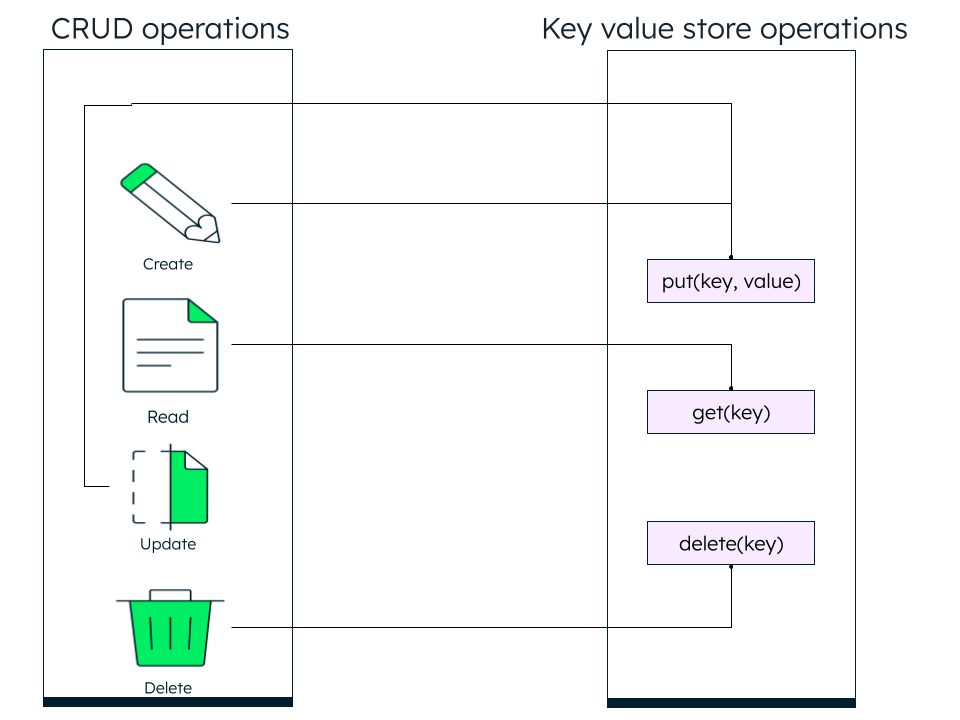
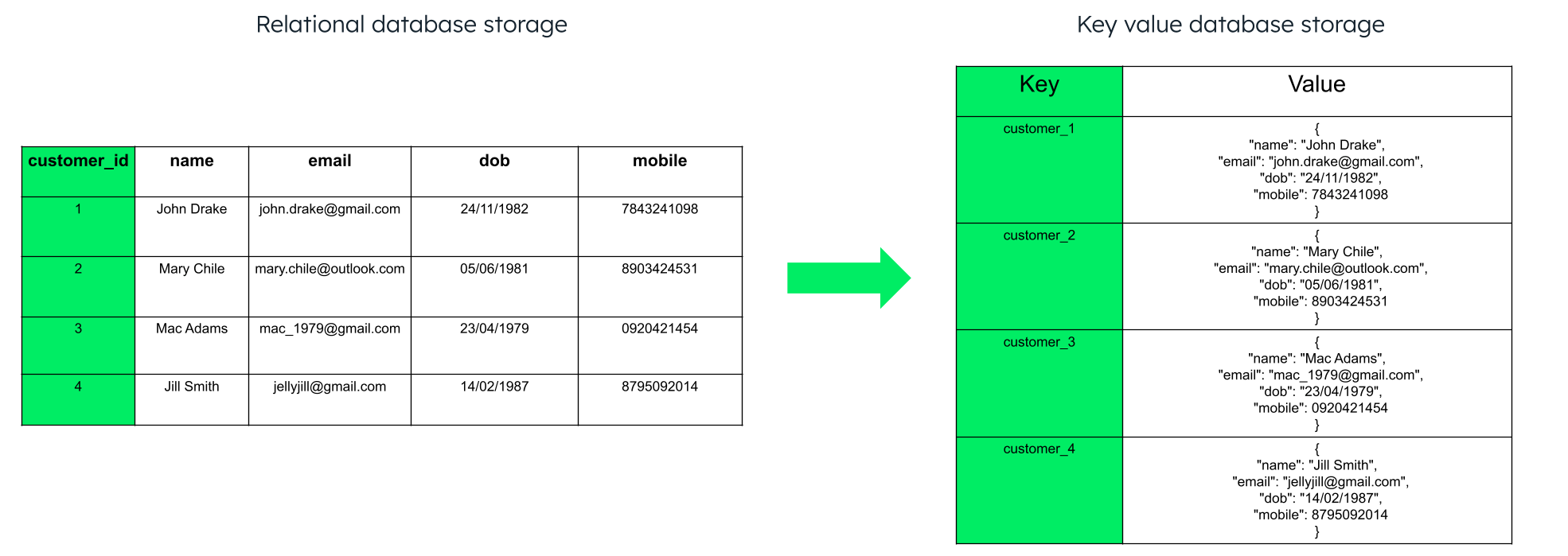
Key value databases, also known as key value stores, are NoSQL database types where data is stored as key value pairs and optimized for reading and writing that data. The data is fetched by a unique key or a number of unique keys to retrieve the associated value with each key. The values can be simple data types like strings and numbers or complex objects.
The unique key can be anything. Most of the time, it is an id field, since that's the unique field in all the documents. To group related items, you can also add a common prefix to the key. The general structure of a key value pair is key: value. For example, “name”: “John Drake.”
Table of contents
- Types of key value databases
- How do key value databases work?
- What are the features of a key value database?
- MongoDB as a key value store
- Key value database vs cache
- Advantages of key value databases
- Summary
- FAQs
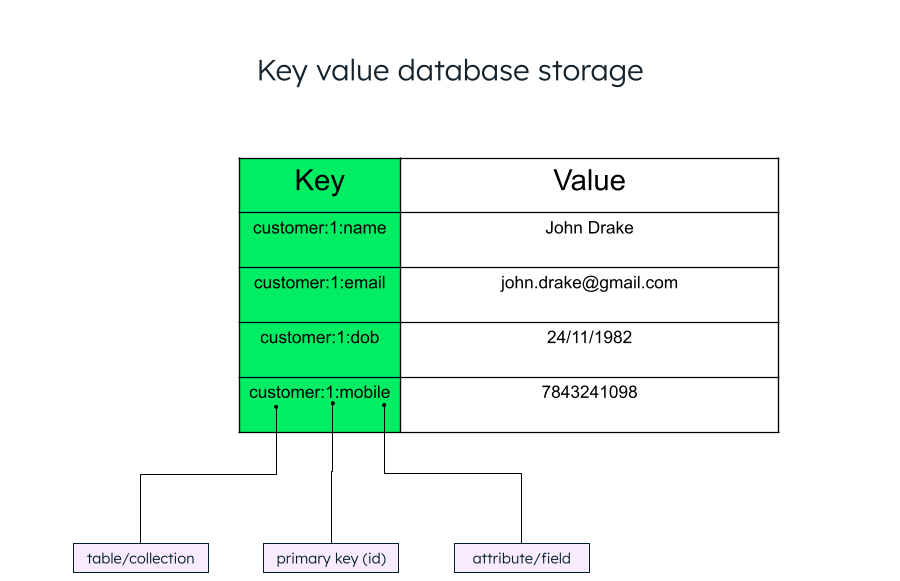
Over the years, database systems have evolved from legacy relational databases storing data in rows and columns to distributed databases allowing a solution per use case. Key value pair stores are not a new concept and have been around for the last few decades. One of the known stores is the old Microsoft Windows Registry allowing the system/applications to store data in a “key value” structure, where a key can be represented as a unique identifier or a unique path to the value.
Data is written (inserted, updated, and deleted) and queried based on the key to store/retrieve its value.