The evolution of databases has been fundamental to the progress of computing. In the early days, traditional databases were simple, centralized systems that stored structured data in rows and columns, such as those found in relational database management systems (RDBMS).
As technology advanced and the demand to store vast amounts of data increased, new data structures emerged. This led to the development of NoSQL databases, which offered more flexibility by allowing unstructured or semi-structured data to be managed at scale. Despite these innovations, most databases remained centralized, with a central authority responsible for storing data, managing data integrity, and processing queries.
The introduction of blockchain technology in 2008 by the pseudonymous figure Satoshi Nakamoto—via the creation of the bitcoin blockchain—brought a decentralized approach to data storage and management. A blockchain is a distributed ledger that tracks and stores transaction data across a network without relying on a single authority. In a blockchain network, multiple nodes work together to validate transactions, ensuring data security and immutability.
This decentralized model marked a significant shift in data management, promising the capacity to eliminate intermediaries, such as banks or other financial institutions, to validate or control data, thus reducing risks like fraud and tampering.
Initially designed to support bitcoin transactions, the potential of blockchain systems has since expanded far beyond cryptocurrencies. Today, blockchain platforms are widely adopted across industries such as healthcare, supply chain management, and real estate for recording transactions securely. However, blockchain technology alone faces challenges with performance—it offers relatively low transactions-per-second and relatively high power-consumption levels compared to traditional systems—particularly in querying blockchain data or processing large datasets across distributed ledger technologies.
This is where blockchain databases come into play. A blockchain database leverages the decentralized structure of blockchain for storing data while integrating the powerful querying and scalability features of modern databases. A blockchain database blends blockchain’s ability to maintain immutable data storage with the high-performance capabilities of traditional databases. By merging these strengths, blockchain databases enable organizations to manage and retrieve blockchain records efficiently, while still benefiting from blockchain’s enhanced security and decentralization.
Table of contents
- What is the difference between a blockchain and a database?
- Using MongoDB Atlas in a blockchain
- How do I build a blockchain database?
- What types of blockchain architecture are available?
- How to integrate blockchain within the enterprise IT stack
- Blockchain database design
- FAQs
What is the difference between a blockchain and a database?
At its core, the goal of a blockchain is to store information, making it a form of decentralized database. However, blockchains differ from other database types primarily in how they store and manage data. A blockchain database uses cryptographically signed blocks to record and link transaction data in a secure, immutable chain.
While blockchains can technically be considered a type of database, a traditional database typically does not function as a blockchain. Most databases do not rely on signed blocks or distributed ledger technologies to store data, and they are usually managed by a central authority.
Here are some key differences between blockchain systems and traditional databases:
Data integrity
In a blockchain network, altering blockchain data is virtually impossible without breaking the chain of blocks. Each block is cryptographically secured, making tampering extremely difficult. In contrast, a traditional database can be more vulnerable to malicious alterations if the appropriate security measures aren’t in place.
Transactions
A blockchain only allows for transactions to be read or added to the chain. Once a block is validated and added, it cannot be altered. Traditional databases, however, allow for full CRUD operations (create, read, update, delete), meaning data can be modified or deleted after being stored.
Querying performance
Due to the need for nodes to validate transactions and the cryptographic methods used to ensure data integrity, querying a blockchain can be slower than querying a database. Traditional databases provide much faster access and performance, especially for complex queries.
Structure
Blockchains operate as decentralized databases, often managed by a network of participants who validate and process new transactions. There is no need for a central authority. In contrast, traditional databases are usually centrally managed, with a database administrator controlling the data and operations.
Despite these differences, hybrid models, known as blockchain databases, are becoming more common. These systems combine the decentralized, secure nature of blockchain platforms with the high-performance querying capabilities of databases, offering the best of both worlds.
Blockchain databases provide immutable data storage while still allowing for fast and efficient querying, making them ideal for applications requiring secure yet accessible blockchain records.
Using MongoDB Atlas in a blockchain
When a blockchain is created, each block is stored across all nodes in the network, ensuring redundancy and decentralization. However, for efficient querying and analytics, integrating a solution like MongoDB Atlas can simplify data access and management. MongoDB Atlas, the database-as-a-service cloud solution from MongoDB, is perfect for storing a blockchain ledger.
- Its flexible schema makes it easy to store complex objects such as transactions.
- It provides enterprise-grade security.
- It has graph chain capabilities with $graphLookup to help efficiently query the blockchain.
- Drivers are available for popular languages used in blockchain development, such as Go, JavaScript, and C++.
- Change streams are available to trigger events when needed.
- Automatic synchronization of databases is available for any mobile device with Atlas App Services.
The data stored in MongoDB can be used in different ways.
- On-chain data: On-chain data is the data from the transactions in the blockchain.
- Off-chain data: Off-chain data refers to information that is related to the blockchain, but is not stored directly within the blocks. Using MongoDB for off-chain data storage can provide additional security and privacy.
- Centralized ledger: MongoDB can be used to store all the information about the blocks. This information is stored with cryptographic evidence to avoid any tampering with the data.
How do I create a blockchain database?
Before building a blockchain database, there are some considerations to take into account. Each deployment scenario is described in deeper detail in the Building Enterprise-Grade Blockchain Databases with MongoDB whitepaper.
First, determine whether the blockchain database will be deployed within a single enterprise or as part of a consortium. Not all blockchains are fully decentralized; in some cases, an enterprise might use a private blockchain to act as the central authority responsible for controlling and managing the blockchain data. In this scenario, the organization maintains control over data stored on the blockchain platform.
However, in many cases—especially with cryptocurrencies like Bitcoin—blockchains operate in a consortium model. Here, no single source owns the data, and each node participating in the blockchain network must maintain a copy of the distributed ledger to validate transactions.
Second, consider how the blockchain database will be used. Operational data, such as data directly accessed by clients (as seen in bitcoin transactions or other blockchain-based distributed ledgers), is publicly accessible, allowing blockchain users to query and perform actions directly on the blockchain.
In contrast, non-operational data is typically accessed through intermediaries, limiting direct interaction with the blockchain ledger. By addressing these considerations, you can effectively design a blockchain database that fits your organization’s needs, whether for private transactions, smart contracts, or public blockchain records.
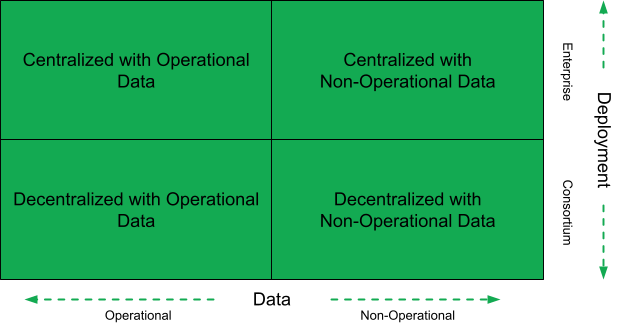
What types of blockchain architecture are available?
The choice of blockchain architecture depends on both the deployment type and the data type being managed. These two factors will determine which of the following four deployment models is best suited for your blockchain implementation.
- Centralized with operational data
- Centralized with non-operational data
- Decentralized with operational data
- Decentralized with non-operational data
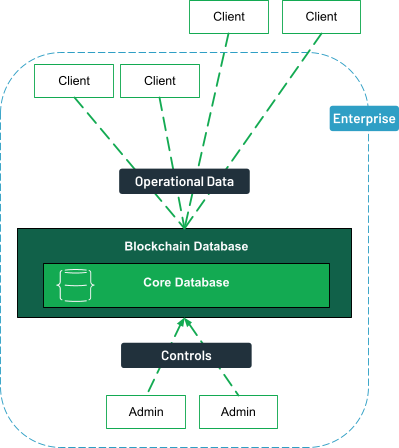
Centralized with operational data
In this model, the blockchain database is deployed within an enterprise and is managed by a central authority. This means the blockchain does not need to be fully decentralized, which simplifies the deployment process.
While this approach may seem counterintuitive to blockchain’s decentralized nature, it still offers advantages, such as immutable data storage and secure asset transfers.
However, in this type of blockchain architecture, the cryptographic protections differ from those in public blockchains. Proof-of-work (PoW) or proof-of-stake (PoS) mechanisms, typically used to achieve consensus in decentralized networks, may not be necessary.
Instead, these systems often rely on alternative methods, such as permissioned access or consensus protocols tailored to the network’s specific needs, making them more akin to traditional application deployments and familiar to most development teams.
Use cases for this model include internal systems where blockchain records need to be audited, as it provides third-party auditors with a clear, immutable trail for transaction data and asset transfers.
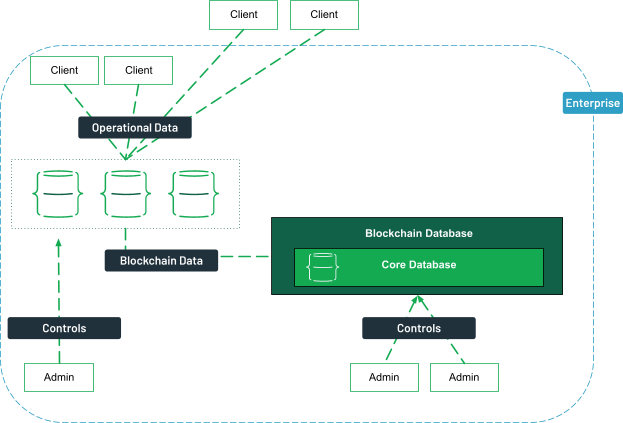
Centralized with non-operational data
Similar to the previous model, this deployment is also centralized but focuses on non-operational data. In this case, clients do not access the blockchain platform directly. Instead, data is offloaded to the blockchain by a limited number of administrators.
This additional layer enhances data privacy by restricting access to a select group of users and improves performance by reducing the number of nodes required to validate transactions.
This model is particularly useful when data security and privacy are critical, such as in systems that manage sensitive financial data like customer credit statuses across different departments.
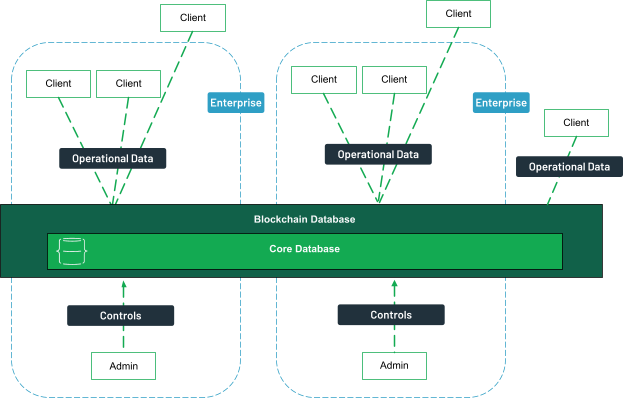
Decentralized with operational data
In this scenario, a blockchain network is created by a consortium of participants, eliminating the need for a single entity to control the distributed ledger. The decentralized nature of this model increases the immutability of the blockchain data, as each consortium member operates a node within the network.
However, additional care is needed to protect data privacy. For instance, a financial institution might limit network users to access data only when necessary, ensuring compliance with regulatory requirements. This model is applicable in industries where transparency and decentralized control are essential, such as the Open Music Initiative for musicians or R3, a consortium of financial institutions.
Decentralized with non-operational data
This deployment model is similar to its centralized counterpart, but with multiple consortium members overseeing the blockchain. The decentralized blockchain increases security while maintaining the advantages of non-operational data management. This scenario enhances performance by limiting the number of clients accessing the blockchain, providing both the immutability of blockchain and the speed needed for business operations.
This type of blockchain architecture is ideal for applications where privacy and speed are crucial, such as systems managing private or off-chain data for enterprises operating in highly regulated industries.
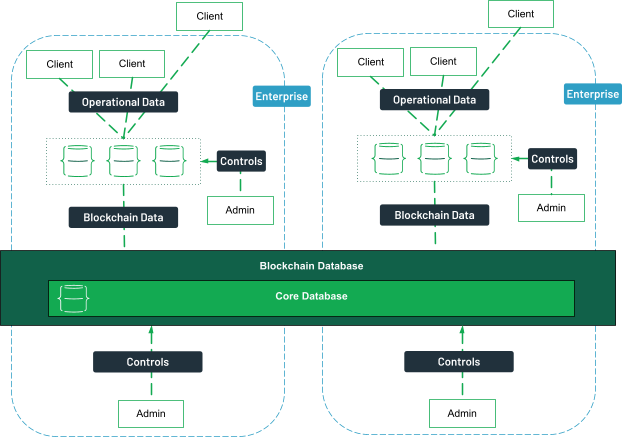
How to integrate blockchain within the enterprise IT stack
Integrating blockchain technology into an enterprise IT stack is a strategic process that requires careful planning based on the chosen blockchain architecture, deployment model, and specific business requirements. Whether deploying a centralized, decentralized, or hybrid blockchain platform, each approach has distinct advantages and integration challenges.
Centralized blockchain integration
In a centralized blockchain model, the integration is similar to traditional database architecture. The blockchain database is deployed alongside enterprise applications within the organization’s existing infrastructure.
In this setup, a central authority—often the enterprise itself—controls the blockchain network, managing blockchain records, data storage, and transaction data. This model simplifies the integration process, as the blockchain behaves like a traditional database but with enhanced features such as cryptographic hash validation and immutable data storage.
For enterprises, a centralized blockchain database can be used to record transactions securely while maintaining control over operational data. This allows businesses to enjoy the benefits of blockchain technology, such as secure asset tracking and audit trails, without overhauling their IT infrastructure.
Use cases for this approach include internal applications where data needs to be audited or stored securely, such as smart contracts, supply chain management, or financial auditing systems.
Decentralized blockchain integration
In contrast, a decentralized blockchain operates across multiple nodes, typically managed by different entities within a blockchain network.
This type of integration offers substantial benefits, such as eliminating the need for a single entity to control the data, enhancing transparency, and providing increased security through distributed ledger technology. Each node on the network is responsible for validating transactions, ensuring that no single participant can manipulate the blockchain data.
While decentralized blockchains are highly effective for applications like cryptocurrencies (e.g., the bitcoin blockchain), integrating this model into an enterprise IT stack presents challenges. A fully decentralized blockchain often requires significant infrastructure changes, as the distributed ledger is spread across multiple servers rather than centralized under one entity. The distributed nature of the blockchain ledger can make it more difficult to manage data security and performance, particularly for industries that require rapid transaction processing.
For example, in industries such as finance, where data integrity and transparency are critical, decentralized blockchains provide a robust solution for recording transactions across multiple parties, without relying on a single authority.
However, the decentralized database nature can complicate integration with existing systems, as it requires data to be replicated across all nodes in the network, which can impact performance and scalability.
Hybrid blockchain integration (partially decentralized)
To address the limitations of both centralized and fully decentralized models, enterprises often opt for a hybrid blockchain approach, also known as partially decentralized architecture. This model offers the best of both worlds, combining the control and performance of centralized blockchains with the security and transparency of decentralized blockchain systems.
In a partially decentralized blockchain, some aspects of the blockchain database—such as operational data—are managed internally within the enterprise’s IT stack. Meanwhile, the blockchain ledger component, which handles transaction data and blockchain records, is distributed across multiple nodes within a blockchain network. This allows enterprises to maintain control over sensitive data while benefiting from the blockchain’s immutable and tamper-resistant nature.
For example, a financial institution may deploy a partially decentralized blockchain where internal operations, such as bank account management or payment processing, are controlled centrally, but transactions processed through the blockchain are verified across a network of nodes. This approach allows enterprises to leverage the security of decentralized blockchain validation while ensuring that mission-critical applications run efficiently within their existing infrastructure.
The benefits of blockchain integration in enterprise IT
Integrating blockchain technology into an enterprise IT stack offers several advantages, including enhanced data security, regulatory compliance, and immutable data storage. The use of blockchain databases can also reduce fraud, as blockchain systems make it nearly impossible to alter blockchain records without consensus from multiple participants in the network.
However, challenges remain, particularly in balancing performance with security. Decentralized blockchains often suffer from slower transaction processing due to the time required for nodes to reach consensus and validate transactions. In addition, the need to replicate data across nodes can slow down query performance, especially for large-scale enterprise applications.
By contrast, centralized blockchains offer faster performance but may sacrifice the decentralized security benefits that blockchain technologies are known for. Enterprises must consider these trade-offs when designing their blockchain architecture to ensure it aligns with their business goals and operational needs.
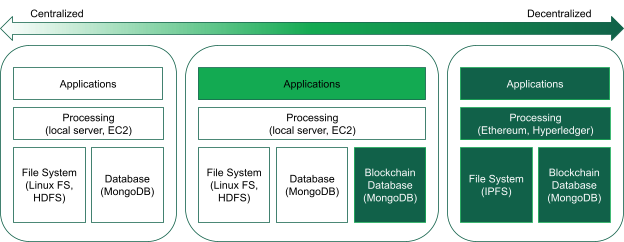
The spectrum of blockchain integration
The integration of blockchain into an enterprise IT stack spans a spectrum from fully centralized to fully decentralized models, with hybrid approaches offering a middle ground. The choice of blockchain architecture will depend on factors such as the type of blockchain data being managed, the need for data privacy, and the desired level of control over the blockchain network.
For enterprise-grade applications, a partially decentralized blockchain is often the most practical solution, allowing organizations to integrate blockchain platforms into their existing IT systems without sacrificing performance or data security. Whether your organization is managing digital assets, processing smart contracts, or ensuring compliance with industry regulations, blockchain technology can enhance your IT infrastructure while offering greater transparency and security.
Blockchain database design
Blockchains by themselves can contain transactional data but have very limited querying abilities. The other problem is with the work required to prove that a block is valid. To validate a block, a majority of nodes need to approve it. The more nodes in the system, the longer this can take. For this reason, it is hard to use a blockchain as a database in the traditional sense.
Instead, it is simpler to take an existing database and then add a blockchain feature on top of it. In this case, two database layers are used. The first layer utilizes a lightweight distributed consensus protocol that ensures some integrity level while providing good performance for querying. The second layer uses a proof of work-based blockchain to store evidence of the database operations from the first layer.
The two layers are connected through a blockchain anchoring mechanism. This anchoring mechanism links parts of the first layer with blocks in the second layer. This creates a chain of evidence validating data from the first layer.