Elsevier Taps MongoDB to Power its Cloud Platforms
Around $4 trillion is invested globally every year in medical and scientific research. Elsevier publishes 17% of the content and discoveries generated from that research, providing visibility to much more through products such as Scopus. MongoDB is at the core of the Elsevier cloud-based platform, enabling the company to apply software and analytics that turn content into actionable knowledge and new insights for its customers.
We met with Kim Baddeley, Application Architect in Business Technology Solutions at Elsevier, to learn more.
Can you start by telling us a little bit about your company?
Elsevier is a global information analytics business that helps institutions and professionals advance healthcare, open science, and improve performance for the benefit of humanity. Elsevier provides digital solutions and tools that enable strategic research management, R&D performance, clinical decision support, and professional education; including ScienceDirect, Scopus, SciVal, ClinicalKey and Sherpath. Elsevier publishes over 2,500 digitized journals, including The Lancet and Cell, more than 35,000 e-book titles and many iconic reference works, including Gray's Anatomy. We are part of RELX Group, a global provider of information and analytics for professionals and business customers across multiple industries.
Can you describe how you are using MongoDB?
MongoDB is at the heart of managing our content and digital assets, powering two critical parts of the infrastructure at Elsevier:
Virtual Total Warehouse (VTW) is the central hub for our content, using MongoDB to manage the JSON-serialized metadata for each piece of research, including the title, author, date, abstract, version numbers, distribution rights, and more. Our revenue-generating publishing apps use VTW to access the appropriate research.
Unified Cloud Service (UCS) sits alongside VTW, storing the physical binary content assets (i.e. PDFs, Word documents, HTML, notebooks) in Amazon Web Services (AWS) S3 buckets, with MongoDB managing metadata for the asset, including its title, its indexed location in S3, and file size.
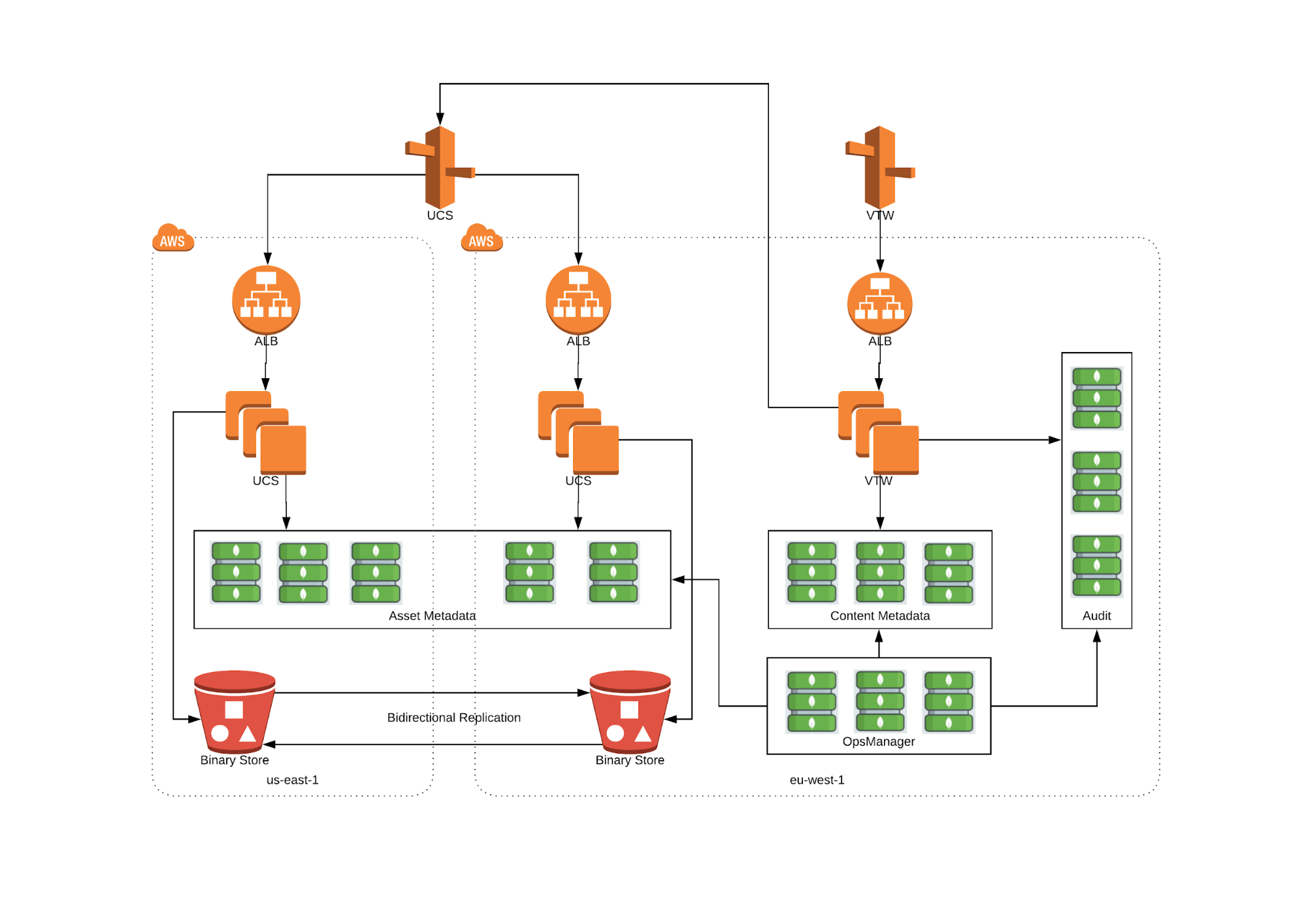
High level Elsevier architecture: MongoDB deployed across two AWS regions
Our platforms store 1.2 billion physical assets, represented as 200 million MongoDB documents, before replication. We serve an average of 50 million API calls per day, reaching 100 million calls during our peak publishing cycles.
Did you use MongoDB from the start, or something else?
We initially built out on a Key-Value NoSQL database, using it to store indexes into our assets persisted in S3. The content’s metadata was also stored in S3 along with the binary asset itself. We found this approach had a number of limitations. For one, it was expensive. And then it was next to impossible to ask more complex business queries for analytics against the content.
We decided to explore alternatives, and ran a Proof of Concept (PoC) on MongoDB, which proved itself in all of our tests, so we made the switch.
What encouraged you to consider MongoDB?
Currently our internal data model is a JSON-LD schema, and so MongoDB seemed an ideal fit as it offers native JSON document storage, along with a rich query language, and distributed, scale-out design.
We use agile methodologies and DevOps to build and run our applications. With MongoDB, our developers can move much faster, creating new services without first having to pre-define database schema.
Can you talk us through the migration process?
Migration was completed in a multi-stage approach:
Copy the data from the Key-Value datastore to MongoDB
The application then writes to both databases, and reads from the existing Key-Value store to maintain existing application functionality.
After one month we performed a reconciliation between the databases to ensure they were both in sync, and then moved all reads to MongoDB while still writing to the Key-Value database. This approach would enable us to switch back if required.
After another month we re-directed all traffic to MongoDB, turning off writes to the existing store, and dropping it.
We also took the opportunity to update our data model. In the previous system, we were persisting metadata and properties in separate places. With MongoDB’s richer data model, we could combine these entities into a single document to give us improved reporting capabilities.
What have the results been of migrating to MongoDB?
Firstly, we’ve been able to reduce costs by 55%, while maintaining performance levels at scale. In the original architecture, each document was modelled as an object in an S3 bucket and an entry in two tables of the Key-Value store. Most of the cost saving came from the performance of MongoDB versus the provisioned throughput on the existing Key-Value tables that was required to get the performance we needed.
Secondly, we have been able to introduce much greater capabilities to our platform – we can answer business questions that just weren’t possible with the previous Key-Value store, for example, how many of our articles are available under open access distribution policies. We can analyze the content in new ways, enabling us to build new services, and provide operational insight to the organization that we were unable to expose before.
To extend analytics functionality, we have recently completed a PoC with the MongoDB Connector for BI. This capability will allow our business analysts to use their existing Tableau tools to explore and visualize richly structured content metadata directly from MongoDB, without first having to move that data into a tabular, SQL database.
How is MongoDB deployed?
We run MongoDB Enterprise Advanced in AWS EC2.
VTW is currently configured with a single shard and three replica set members. This provides us the foundation to scale-out as we need to add capacity, using Ops Manager to provision new shards on-demand, either via its GUI, or RESTful API. Either way, our DevOps team doesn’t need to manually add new instances from the command line, or create their own deployment scripts.
UCS is deployed across a geo-distributed, five node replica set with members spread across AWS regions in the US and EU, enabling us to provide service continuity in the event of a complete regional outage.
In addition to provisioning, we also use Ops Manager for monitoring cluster health and query performance, and for continuous backups with point in time recovery. We use MongoDB access controls to manage permissions to the underlying content assets, and the Encrypted storage engine to secure data at-rest.
We are a Java shop, so use the MongoDB Java driver, with a bit of Scala sprinkled in here and there. We also used the MongoDB Connector for Apache Spark for data reconciliation during the migration from the Key-Value database to MongoDB, and use it today to reconcile assets between VTW and UCS.
Do you have other projects underway with MongoDB?
Yes, we are extending the use of MongoDB further into our Production Process Evolution (PPE) project. VTW is at the core of our production platform, but we have two legacy systems that we are working now to evolve. The production systems are responsible for ingesting new content, and then triggering an event-driven framework to drive the production pipeline – converting the assets into required formats such as PDFs, generating thumbnails, creating the metadata, enriching the content, and persisting it to the object store.
We are using a phased approach to the migration, moving specific functionality in parts as microservices. We are packaging the evolved functionality in Docker containers, orchestrated with Kubernetes, and will use MongoDB as the backend data platform, with plans to run it the Atlas database service.
Why MongoDB Atlas?
Strategically we are looking to embrace software as a service across our entire computing estate, rather than operate everything ourselves. Experience shows us that this helps us move faster. In my team, we run a lean DevOps organization, and want to focus on our apps, rather than backend database operations.
The Atlas service fits that bill – we can pass all of the provisioning, managing, monitoring, and upgrades to MongoDB, freeing up our team’s bandwidth to focus on meeting the needs of the business, and the scientific community we serve. It also makes more sense cost wise. We can simply spin up and scale services on-demand, without having to acquire and pre-provision resources in advance. What’s more, we don’t need to invest in expanding internal expertise to run the database, but rather farm that back to MongoDB.
Anything else for MongoDB at Elsevier?
I’m excited about multi-document ACID transactions that have recently come to MongoDB in the new 4.0 release. This will help us extend MongoDB to even more use cases in the future, and is immediately useful to the project I’m working on now.
Kim, thanks for sharing your story with the MongoDB community!
About Kim
Kim Baddeley is a senior technologist at Elsevier with over 5 years’ experience architecting and developing large scale, cloud-native applications. He loves good food, fine wine, fitness, adventure sports and technology - not necessarily in that order.
