
The Materials Project delivers a ‘Google’ for materials research with help from MongoDB

INDUSTRY
PRODUCTS
MongoDB Enterprise Advanced
INITIATIVE
CUSTOMER SINCE
The Materials Project and MongoDB
As a public initiative supported by funding from the US Department of Energy, the Materials Project (MP) at Lawrence Berkeley National Laboratory isn’t looking to become the tech industry’s next billion-dollar unicorn. However, the insights it provides to the public for free could inspire many unicorns to come. By computing properties of all known materials, the Materials Project aims to remove guesswork from materials design. Experimental research and the discovery of novel materials can be targeted to the most promising compounds by applying tailored and tiered screening criteria on MP’s computational data sets (see figure).
For example, research leading up to the launch of Materials Project on the energy storage capabilities of different kinds of materials helped lead to Duracell’s launch last year of a new battery called Optimum, which the company says can provide devices with either extra life or extra power. The Materials Project’s research can also be applied to innovations in transparent conducting films, thermoelectric devices, LEDs, electrolytes and other new technologies.
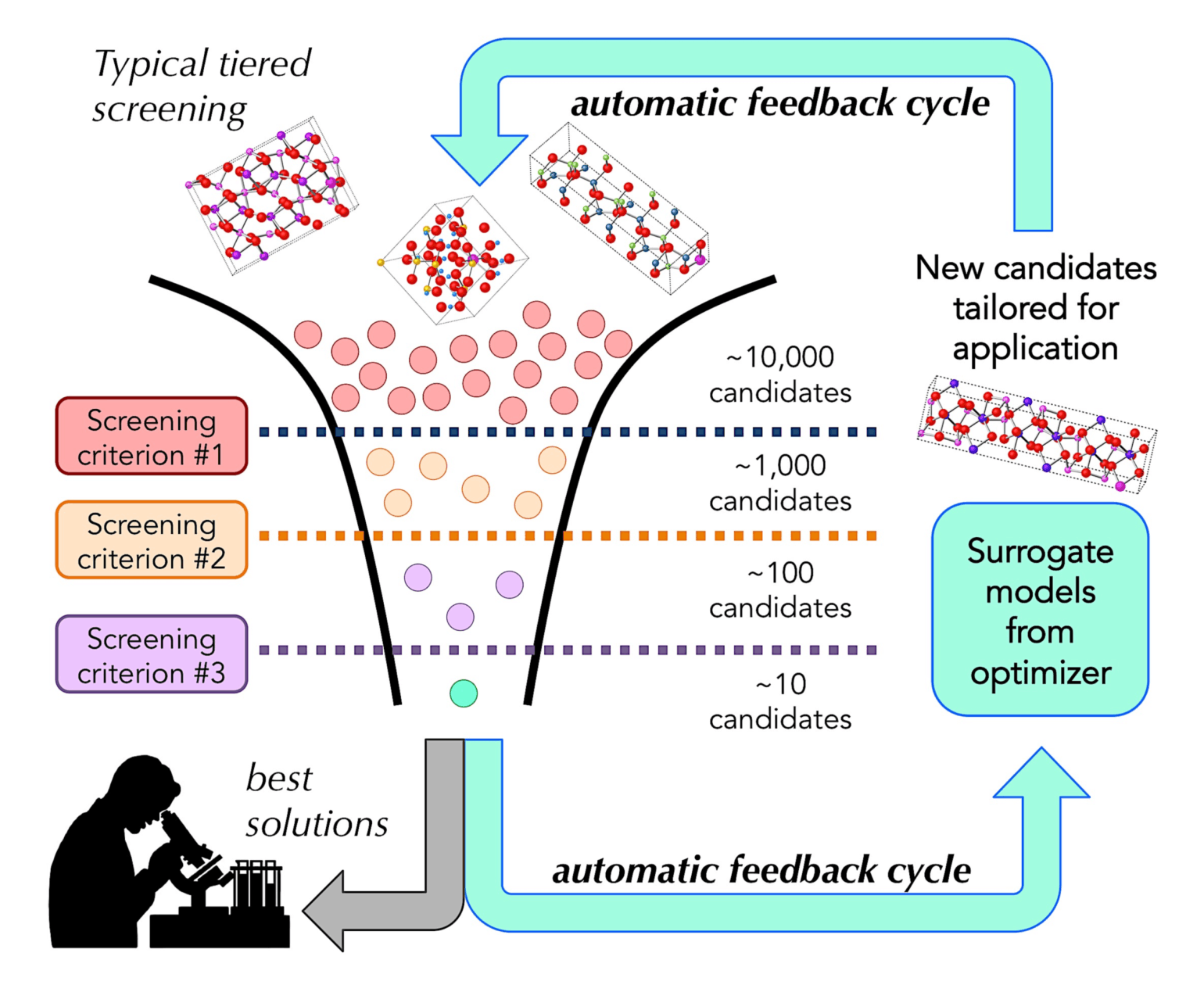
The discovery of novel materials is driven by a screening cycle to identify promising candidates with materials properties suited for the application. Computed materials in MP’s database can be filtered by applying selection criteria that increase the likelihood of successful synthesis in the lab. New results from synthesis and characterization in the lab are fed back into the “screening funnel” to improve the list of materials candidates.
A Million Calculations, Exponential User Growth And Constant Up-Time
The Materials Project generates a lot of data. To date, it’s carried out millions of calculations resulting in 131,613 distinct inorganic compounds and 530,243 nanoporous materials (which have pores of a consistent size that allow only certain substances to pass through). It provides its findings to over 135,000 registered users around the world and demands near 100% uptime. “When I joined in 2014, we were at about 5,000 users,” Dr. Huck says. “We now have over 135,000 and we’re still in exponential growth.” The Materials Project’s infrastructure includes supercomputers at the Berkeley Lab’s National Energy Research Scientific Computing Center (NERSC) and other DOE sites – these run high-throughput materials simulation programs to calculate the properties of different materials’ structures. The project also has a website that delivers the project’s findings to the public, and backend applications that power the site. And then, of course, there’s data – a decade’s worth of data that Dr. Huck and the core MP team needed to incorporate into modern infrastructure to deliver a searchable web app that could scale for exponential growth both in terms of data ingested and users all while staying online without downtime.
Crucial Database Support
When the project started in 2011, it began with a monolithic infrastructure, choosing MongoDB for its backend database over alternatives such as MySQL or SQL. That’s enabled the project to keep growing ever since, Dr. Huck says.
“MongoDB comes in as a very central aspect of our entire infrastructure,” Dr. Huck says. “You could say that almost everything we do is designed around one or more MongoDB databases.”
The Materials Project uses open-source FireWorks software to manage its simulation workflows – this defines which jobs to submit when to the NERSC supercomputers. FireWorks operates hand-in-hand with the MongoDB database. The raw output of each simulation is parsed into queryable documents and fed back into the database.
Over the years, Dr. Huck estimates that the project’s data infrastructure has generated more than 250 terabytes of raw data, with higher-level information stored in a number of databases of 5 to 10 terabytes each. A core database of around 100 gigabytes feeds into the website, but the Materials Project is now working to move many of its website-related MongoDB workloads — previously self-managed on-premise in MongoDB Enterprise Advanced, and in AWS — to MongoDB Atlas, the managed database service, and undergo a shift to microservices. This includes index collections for terabytes of band structure objects in S3 storage, for instance.
Dr. Patrick Huck, Berkeley Lab's Materials Project
Public Access to Valuable Research
Any member of the public can access the Materials Project’s data via a searchable website that displays between 20 and 30 properties for every material’s structure that’s been run through the simulator. This lets site users sort materials according to a wide variety of characteristics, ranging from band structures (the levels of energy that a material’s electrons have) to thermodynamic or nanoporous properties.
Now under way, the project’s application and data infrastructure is being updated with a switch to microservices, containers, and Amazon Web Services for S3 storage and more. Dr. Huck says the Materials Project is using an API container and peering to connect to a MongoDB Atlas cloud deployment in the same region.
Other aspects of the update – how to speed up queries, for example – have taken some care to work out. Dr. Huck remembers long but efficient sessions to identify bottlenecks in data structure, CPU/memory resources, and queries that would not have been possible without Atlas’s excellent interfaces for Real Time Metrics and Profiler. There have also been days where Atlas’s automated cloud provider backups turned out to be life savers.
At the moment, Materials Project is exploring Atlas Search and its custom Lucene Analyzers to enable advanced capabilities like full-text-search and auto-completion of materials formulas, synthesis recipes, and crystallographic descriptions. Refreshing its systems is important after all these years, because today’s website users expect a much different experience than the one they had in 2011.
“Our scientific group with a small core of staff members has to run an efficient public website that is available 24/7, that serves data and that has all the infrastructure requirements that a modern website has. The expectations are high,” Dr. Huck says.