
INTRODUCTION
Mission: Be the most customer-centric distributor in its industry
American Tire Distributors (ATD) is the largest replacement tire distributor in North America providing “tires at the speed of now” through more than 140 distribution centers serving 130,000 manufacturers and retailers across the U.S. and Canada. ATD offers same- or next-day service on more than eight million deliveries comprising 45 million units (tires and related products) per year. It has $1 billion in inventory on hand with 15,000 active products across 22 million square feet of warehouse space and 600,000 stocking locations. Brands under the ATD umbrella include National Tire Distributors, TDI, Hercules Tires, TirePros, ATDOnline, and Tirebuyer.

The figures above are impressive, but perhaps even more impressive is ATD’s mission to be known as the most customer-centric distributor the industry has ever seen by achieving its vision of becoming the world’s most connected and insightful automotive solutions provider. Suryadeep Chatterjee, Senior Director of Enterprise Architecture, Integration & Automation Technologies at ATD, spoke with us about how the technology team there is using MongoDB Atlas and Google Cloud to support its digital transformation journey in order to drive fast toward ATD's ambitious goals.
THE CHALLENGE
Limitations of legacy data stores
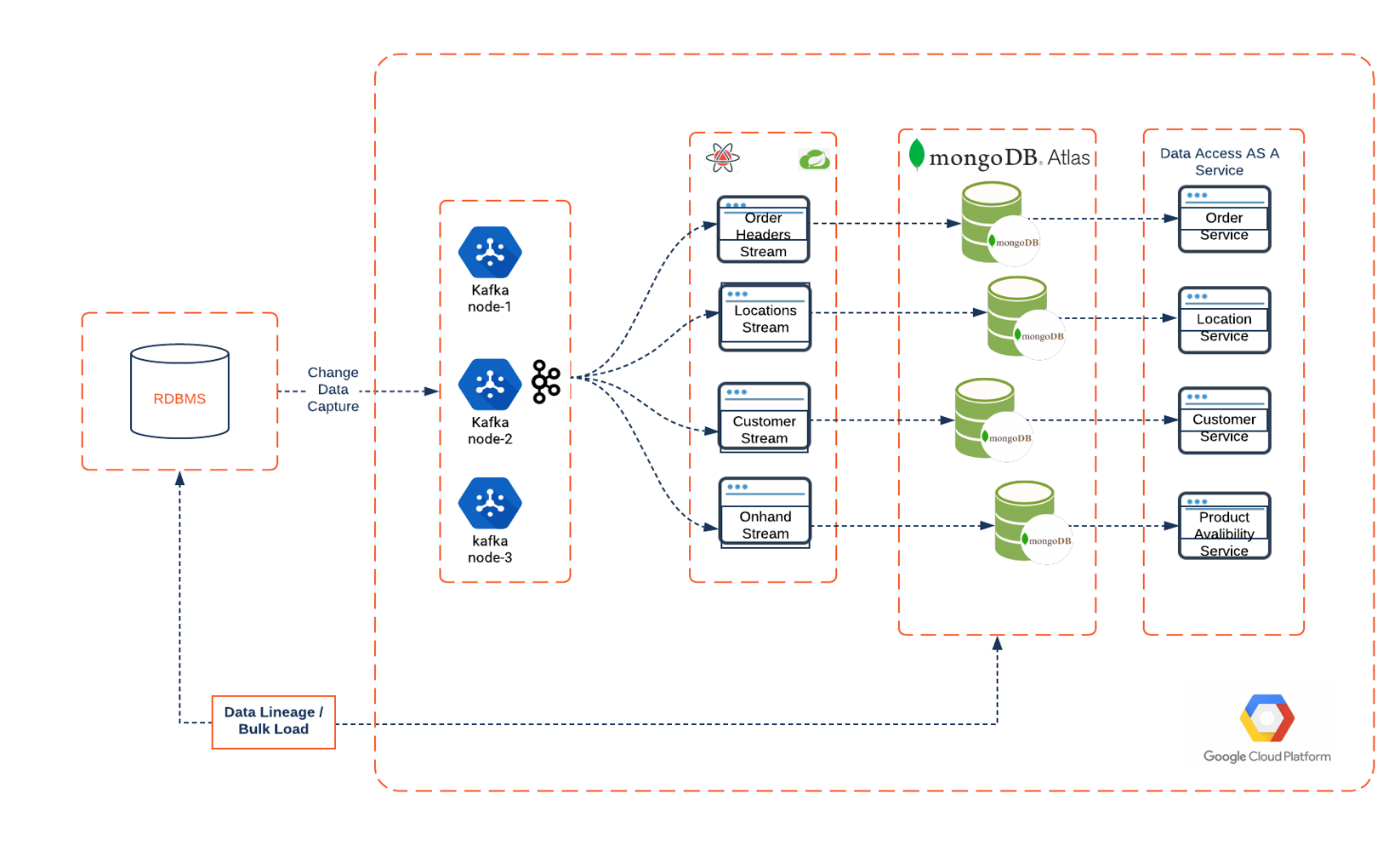
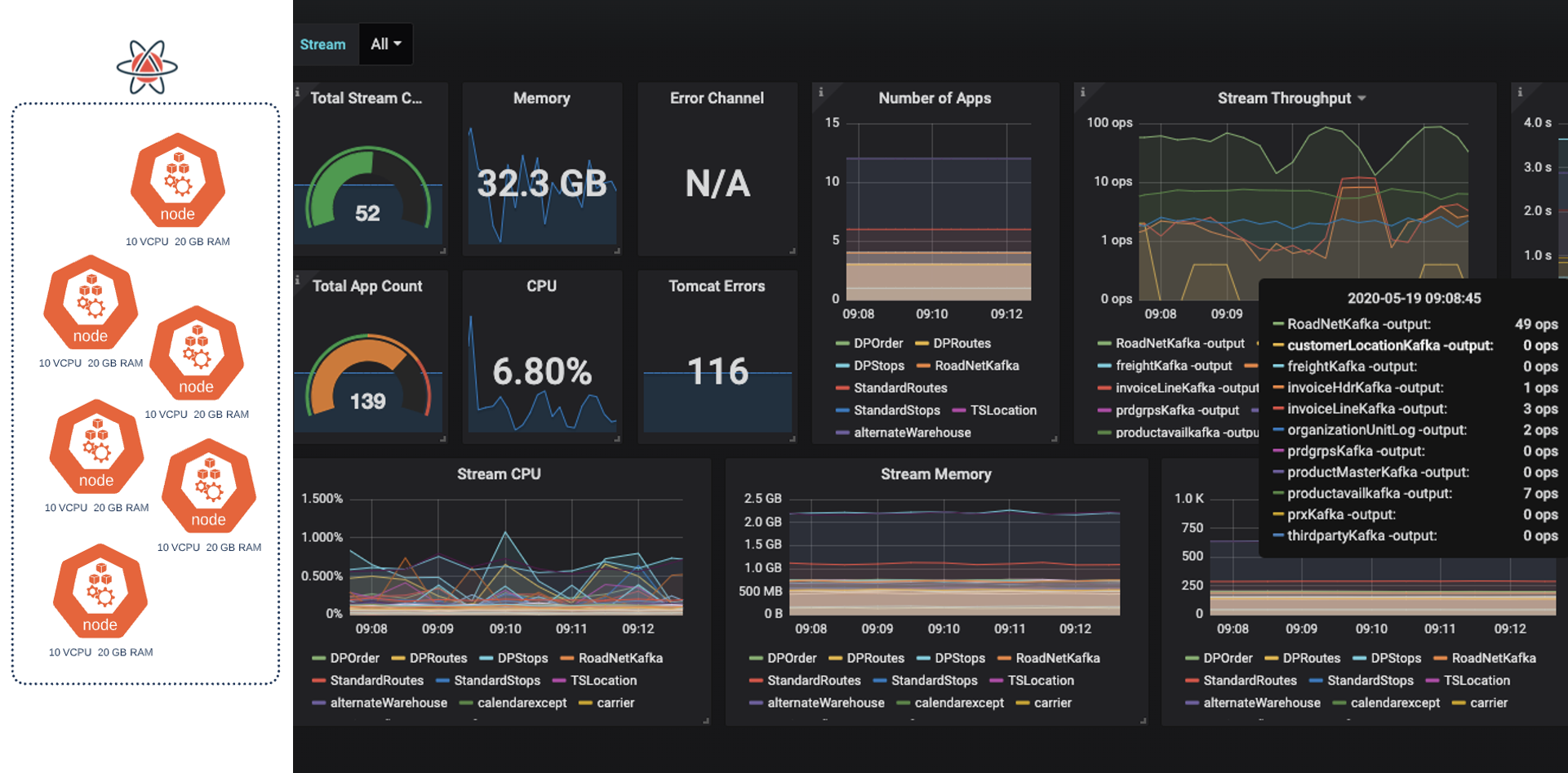
ATD is working with MongoDB and Google Cloud to solve a universal problem: how to unleash the massive amounts of data locked up in legacy data stores on-premise, said Chatterjee. “We have years’ worth of legacy data. Our challenge was, how can we unlock it to drive the business forward?”
Technology teams at ATD are on the road to the digital transformation of their business through highly performant distributed microservices-based systems connected via APIs. Doing so with a legacy relational database would require the immensely difficult proposition of getting such a database to stream data across a high volume of transactions in near real time. This new model also demands a hybrid cloud architecture spanning on-premise data centers through to public clouds. The data integration, too, would pose serious challenges to a relational database.
ATD’s legacy systems kept data locked in silos, making access difficult, and forced it to integrate data from an on-premises data center to the cloud and back again. It had no capability to process streaming data and store it for accessibility. And ATD’s desire to support data in a multi-cloud platform environment was out of the question. All of these constraints were keeping it from its goal of creating required information systems to support the tire supply chain of tomorrow.


.svg)