In today’s competitive world, software applications need to be fast and responsive. With more people going digital, accommodating high loads on a particular application is imperative. Applications crashing due to high load is mostly a thing of the past, largely thanks to containers. Containers allow many instances of a given application service to be much more easily deployed quickly, meaning services can be scaled more dynamically in response to greater load. For larger applications, where many containers are needed, container orchestration tools play a major role in managing the overall lifecycle of containers. Without intelligent and automated orchestration, managing hundreds or thousands of containers would be unfeasible and error-prone done manually.
To be able to understand container orchestration — or in simple words, “container management” — we need to understand how containers came into existence and the real-world problems they solve.
In this article, we will discuss the need for containerized applications, container orchestration, some popular container orchestration tools, and how stateful applications like MongoDB work with container orchestration tools to deliver highly scalable, available, and resilient applications that also automate continuous integration and deployment of applications.
Table of contents
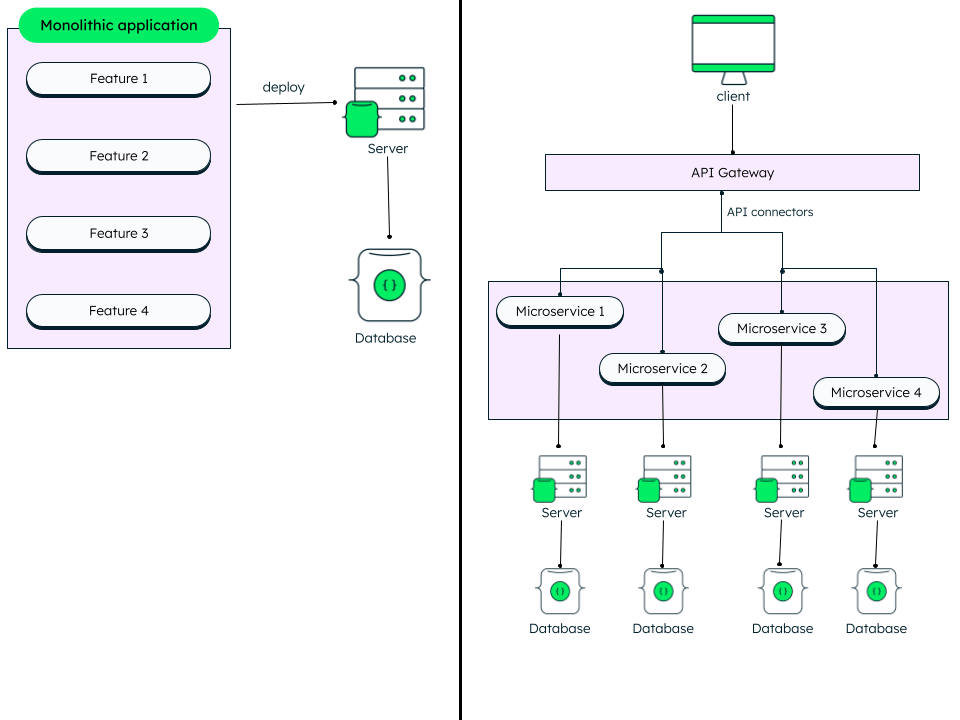
- From monolith to microservices
- Need for containerization
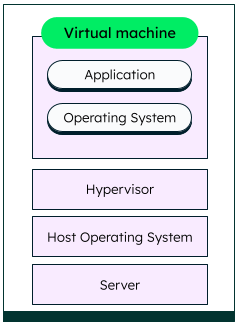
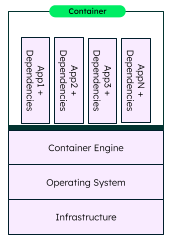
- What are containers?
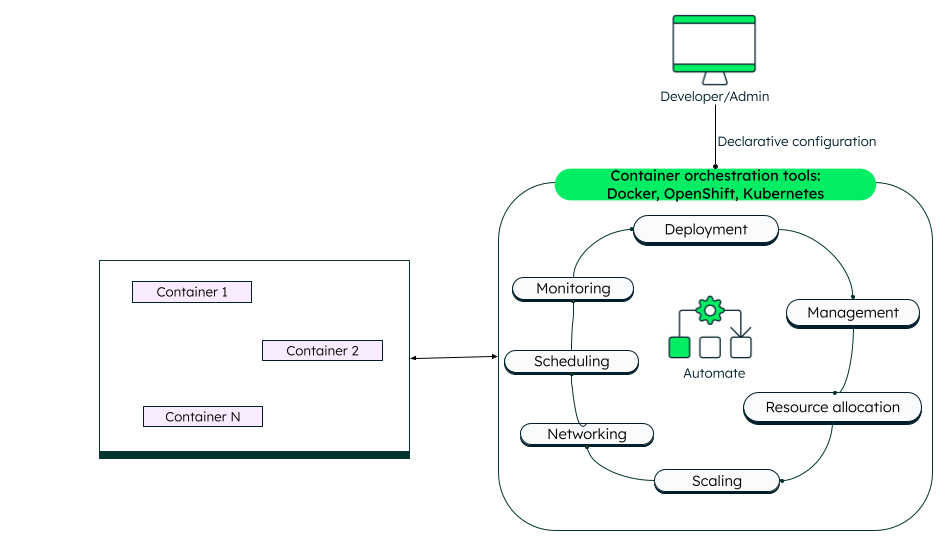
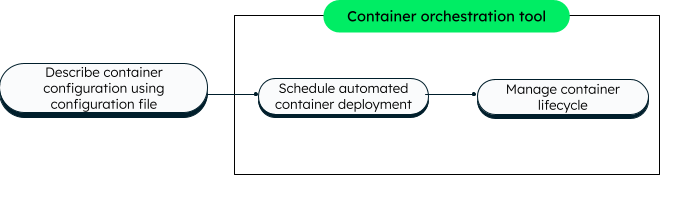
- Container orchestration explained
- How does container orchestration work?
- Benefits of container orchestration
- Container orchestration tools
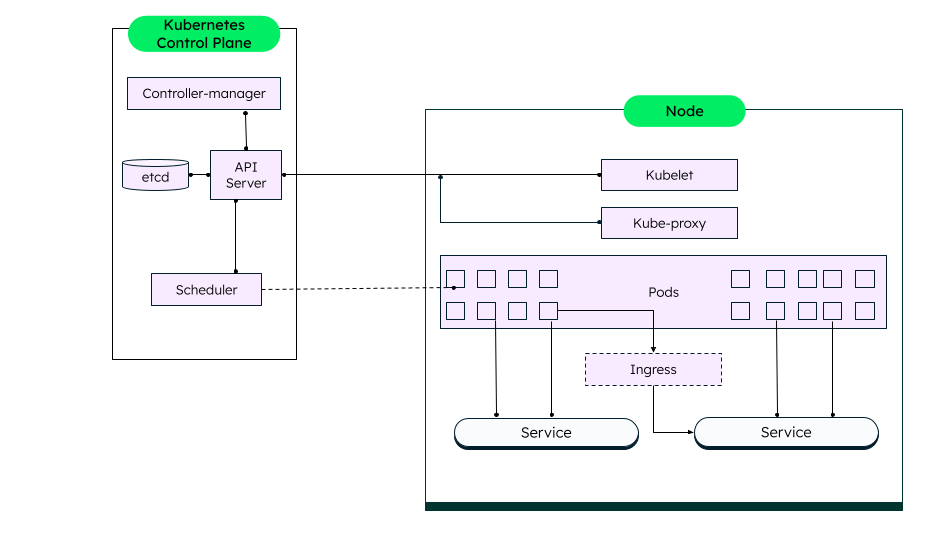
- Kubernetes — the most popular container orchestration tool
- What type of applications can be deployed on containers?
- MongoDB and Kubernetes
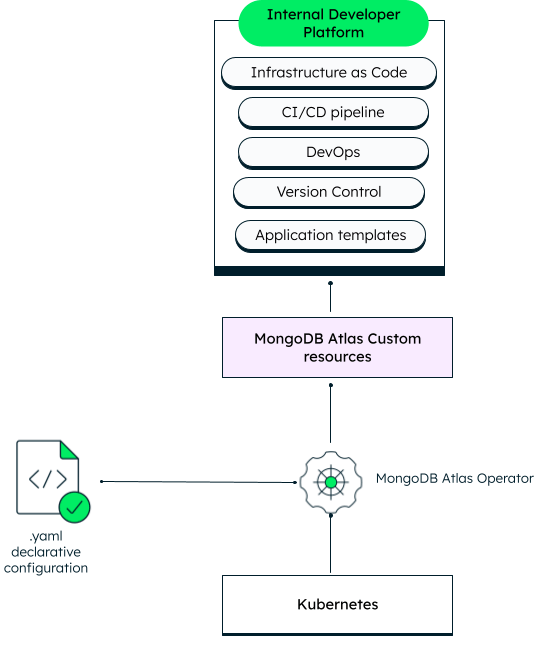
- MongoDB Atlas
- MongoDB Atlas Kubernetes Operator
- FAQs