When planning a new project or application, the discussion of database requirements will often come up. What type of database should be used? What’s the difference between relational and non-relational databases?
This article aims to address those questions by explaining what they are and how they differ and to help you make an informed decision. Towards the end, you’ll learn about Relational Migrator, a free developer tool that utilizes intelligent algorithms and gen AI to help you seamlessly migrate from popular relational databases to MongoDB.
Data of the digital age can be categorized into operational and analytical data.
- Operational data is used for day-to-day transactions and needs to be fresh—for example, product inventory and bank balance. Such data is captured in real-time using Online Transaction Processing (OLTP) systems.
- Businesses use analytical data to gain insights into customer behavior, product performance, and forecasting. It includes data collected over a period of time and is usually stored in OLAP (Online Analytical Processing) systems, warehouses, or data lakes.
Databases are the most efficient way to permanently store and fetch operational and analytical data digitally.
Based on their project requirements, companies need to choose a database that can: Store all types of data. Access required data quickly. Get instant insights to make strategic business decisions. Most companies need both OLTP (operational) and OLAP (analytical) systems to store their data and can use a relational database, non-relational database, or both to serve their business purposes.
What is a relational database?
A relational database, or relational database management system (RDMS), stores information in tables. Often, these tables share information, forming a relationship between them. This is where a relational database gets its name.
A table utilizes columns to define the types of information being stored and rows to hold the actual data. Each table contains a column that must have unique values, referred to as the primary key. This primary key can be used in other tables to establish relationships between them. When the primary key from one table is used in another table, the corresponding column in the second table is known as the foreign key. The most common way of interacting with relational database systems is using SQL (Structured Query Language). Developers can write SQL queries to perform CRUD (Create, Read, Update, Delete) operations. A simple example of a query is:
Imagine you run an online business. You store various information, such as customer, order, and product information, in a relational database. This information would be stored in different tables, with a key to join the tables when needed.
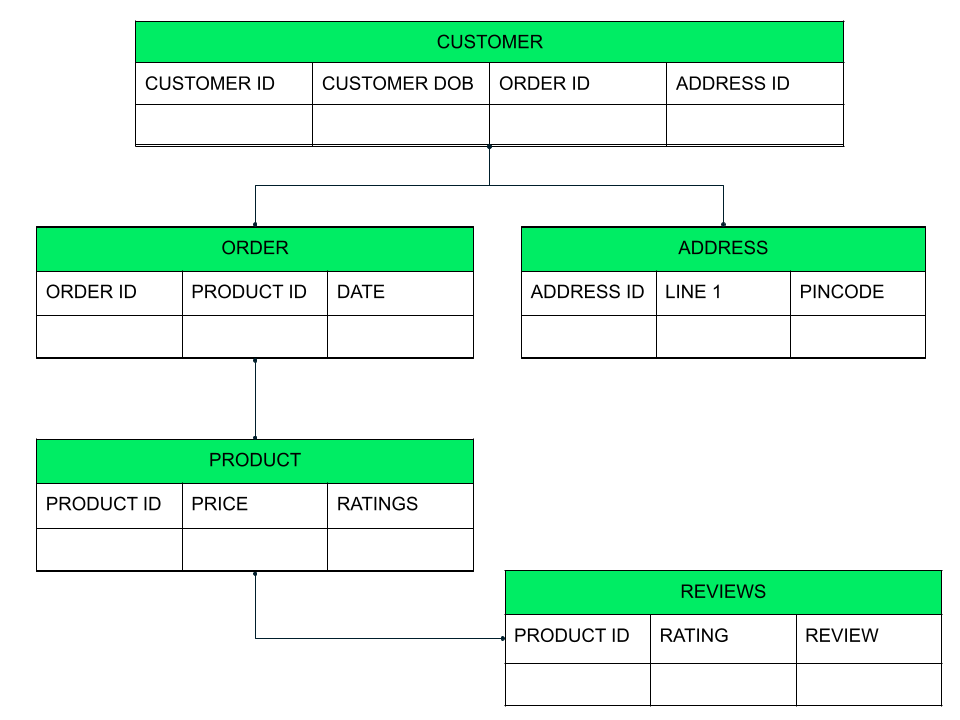
Here, the customer table stores the basic customer information, order id and address id. If someone needs more information on the order or address, they can query the matching order and address tables using an INNER JOIN operator with the id field. The order, table in turn, has product ids of the product items in the order. The details of the product are in a separate product table. This makes information organized and more structured.
Advantages of relational databases
ACID compliance
Atomicity, Consistency, Isolation, and Durability (ACID) is a standard that guarantees the reliability of database transactions. The general principle is if one change fails, the whole transaction will fail, and the database will remain in the state it was in before the transaction was attempted.
This is important because some transactions—for example, banking — will have real consequences if not completed fully. For more information, see our documentation explaining ACID.
Data accuracy
Using primary and foreign keys allows you to ensure there is no duplicate information. This helps enforce data accuracy because there will never be repeated information.
Normalization
The process of normalization involves organizing the data so that data anomalies are reduced or eliminated. This, in turn, reduces storage costs.
Simplicity
RDMS, or SQL databases, have been around for so long that a wide variety of tools and resources have been developed to help get started and interact with relational databases. The English-like syntax of SQL also makes it possible for non-developers to generate reports and queries from the data.
Disadvantages of relational databases
Scalability
RDMSs are historically intended to be run on a single machine. This means that if the machine's requirements are insufficient due to data size or an increase in the frequency of access, you will have to improve the hardware, also known as vertical scaling.
This can be incredibly expensive and has a ceiling, as eventually, the costs outweigh the benefits. Plus, there will potentially come a stage where you simply cannot get hardware capable of hosting the database. The only solution would be to buy a machine that supports better hardware, which can be very costly.
Flexibility
In relational databases, the schema is rigid. You define the columns and data types for those columns, including any restraints such as format or length. Common examples of constraints would include the length of a phone number or the minimum/maximum length for a name column.
Although this means you can interpret the data more easily and identify the relationships between tables, it means that making changes to the structure of the data is very complex. You have to decide at the start what the data will look like, which isn’t always possible. If you want to make changes later, you have to change all the data, which involves the database being offline temporarily.
Performance
The performance of the database is tightly linked to the number of tables, the complexity of their architecture, and the volume of data in each table.Query performance often degrades as RDMs scale.
What is a non-relational database?
A non-relational database, sometimes called NoSQL (Not Only SQL), is any kind of database that doesn’t use the tables, fields, and columns structured data concept from relational databases. Non-relational databases have been designed with the cloud in mind, making them great at horizontal scaling.
There are a few different groups of database types that store the data in different ways:
Document databases
Document databases store data in documents, which are usually JSON-like structures that support a variety of data types. These types include strings; numbers like int, float, and long; dates; objects; arrays; and even nested documents. The data is stored in pairs, similar to key/value pairs.
Consider the same customer example as above. In this case, however, we are able to view all the data of one customer in a single place as a single document.

Below is the query to get the product name and price of the given productid using the Mongo Query API (similar to SQL in the previous section). In this query, the first argument (_id) represents the filter to use on the collection, and the second one—the projection—fields that should be returned by the query.
Because documents are structured like JSON, they are much easier for users to read and understand. The data is organized and easy to view, eliminating the need to reference multiple documents or collections to access a single customer's information. Additionally, these documents align well with objects in object-oriented programming languages, making them simpler to work with.
The document model is more suitable for modern AI applications. It allows you to store embeddings alongside other document data (as just another format supported by BSON), providing great flexibility for integrating LLM-based workflows into existing or new AI applications. MongoDB’s document model combines the capabilities of a document database with a specialized vector store, resulting in a simpler architecture, less overhead, and a unified experience to build modern AI applications.
Also, MongoDB’s search capabilities allow developers to search across entire documents, apply vector search to embeddings, full-text search to other fields, and even hybrid search by combining both approaches, offering faster querying and better accuracy.
Achieving the same functionality with a specialized database would require more effort or complex joins.
Other advantages of the document model
In addition to making it more natural to represent data at the database level, the document model also provides performance and scalability advantages:
The complete document can be accessed with a single call to the database rather than having to JOIN multiple tables to respond to a query. The MongoDB document is physically stored as a single object, requiring only a single read from memory or disk.
On the other hand, RDBMS JOINs require multiple reads from multiple physical locations.
As documents are self-contained, distributing the database across multiple nodes (a process called sharding) becomes simpler and makes it possible to achieve horizontal scalability on commodity hardware. The DBA no longer needs to worry about the performance penalty of executing cross-node JOINs to collect data from different tables.
Key-value database
This is the most basic type of database, in which information is stored as two parts: key and value.
The key is then used to retrieve the information from the database.
The simplicity of a key-value database is also an advantage. Because everything is stored as a unique key and a value that is either the data or a location for the data, reading and writing will always be fast.
However, this simplicity restricts the type of use cases it can be used for. It does not support more complex data requirements.
Graph databases
Graph databases are the most specialized of the non-relational database types. They use a structure of elements called nodes that store data, and edges between them contain attributes about the relationship.
Relationships are defined in the edges, which makes searches related to these relationships naturally fast. Plus, they are flexible because new nodes and edges can be added easily. They also don’t have to have a defined schema like a traditional relational database.
However, they are not very good for querying the whole database, where relationships aren’t as well—or at all—defined. They also don’t have a standard language for querying, which means that switching between different graph database types requires additional learning.
Wide-column databases
Wide-column databases, similar to relational databases, store data in tables, columns, and rows. However, the names and formatting of the columns don’t have to match in each row. The columns can even be stored across multiple servers. They are considered two-dimensional key-value stores because they use multi-dimensional mapping to reference data by row and column.
Like two-column key-value databases, wide-column databases are flexible, so queries are fast. Because of this flexibility, they are good at handling “big data” and unstructured data.
However, compared to relational databases, wide-column databases are much slower when handling transactions. Columns group together similar attributes rather than using rows and store these in separate files, which means transactions have to be carried out across multiple files.
When to use a relational database
If you’re creating a project where the data is predictable in terms of structure, size, and frequency of access, relational databases are still the best choice.
Normalization can help reduce the size of the data on disk by limiting duplicate data and anomalies, decreasing the risk of requiring vertical scaling in the future.
Relational databases are also the best choice if relationships between entities are important.
Non-relational databases can store documents within the documents, which helps keep data that will be accessed together in the same place. But if this isn’t right for your needs, a relational database is still the answer. For example, if you have a large dataset with complex structure and relationships, embedding might not create clear enough relationships.
The time RDMSs have been around also means there is wide support available, from tools to integration with data from other systems.
When to use a non-relational database
As discussed, there are many types of non-relational databases, each having their own advantages and disadvantages.
However, non-relational databases still maintain some consistent advantages. If the data you are storing needs to be flexible in terms of shape or size, or if it needs to be open to change in the future, then a non-relational database is the answer.
Modern NoSQL databases have been designed for the cloud, making them naturally good for horizontal scaling, where many smaller servers can be spun up to handle increased load.
Learn how you can transition your project from relational to document-based, non-relational databases.
Why might you prefer a non-relational database over a relational database?
There are many reasons why you’d want to use a non-relational database over a relational database:
- Non-relational databases are suitable for both operational and transactional data.
- They are more suitable for unstructured big data.
- Non-relational databases offer higher performance and availability.
- Flexible schema help non-relational databases store more data of varied types that can be changed without major schema changes.
Summary
In this article, you have learned about relational vs non-relational databases and how they differ from each other. You’ve also learned the advantages and disadvantages of both types of databases and which database type is most suitable for various projects.
MongoDB is a non-relational database that offers scalability, high performance, reliability, and flexibility. MongoDB has grown into a wider data platform with MongoDB Atlas, MongoDB’s cloud-based database, which makes data available at all times.
Ready to migrate from your relational database to MongoDB?
If you're considering migrating your data from your relational database to MongoDB, the Relational Migrator can help. It is a free MongoDB tool that simplifies and streamlines the migration process, significantly lowering the effort and risk of your migration initiative.