This guest blog post is from Arek Borucki, Machine Learning Platform & Data Engineer for Hugging Face - a collaboration platform for the machine learning community. The Hugging Face Hub works as a central place where anyone can share, explore, discover, and experiment with open-source ML. HF empowers the next generation of machine learning engineers, scientists, and end users to learn, collaborate and share their work to build an open and ethical AI future together. With the fast-growing community, some of the most used open-source ML libraries and tools, and a talented science team exploring the edge of tech, Hugging Face is at the heart of the AI revolution.
Traditional movie search relies on filtering by genre, actor, or title. But what if you could search by how you feel? Imagine typing:
"something uplifting after a rough day at work"
"a movie that will make me cry"
"I need adrenaline, can't sleep anyway"
"something to watch with grandma who hates violence"
This is mood-based semantic search: matching your emotional state to movie plot descriptions using AI embeddings.
In this tutorial, you will build a mood-based movie recommendation engine using three powerful technologies: voyage-4-nano (a state-of-the-art open-source embedding model), Hugging Face (for model and dataset hosting), and MongoDB Atlas Vector Search (for storing and querying embeddings at scale).
Why mood-based search?
Genre tags are coarse. A "drama" can be heartwarming or devastating. A "comedy" can be light escapism or dark satire. Traditional filters cannot capture these nuances.
Semantic search solves this by understanding meaning. When you search for "feel-good movie for a rainy Sunday", the system doesn't look for those exact words. It understands the intent and matches it against plot descriptions that evoke similar feelings.
Architecture overview
The system combines three components from the Hugging Face ecosystem with MongoDB:
voyage-4-nano (Hugging Face Hub): Converts text to embeddings (up to 2048 dimensions, we use 1024)
MongoDB/embedded_movies(Hugging Face Datasets): 1500+ movies with plot summaries, genres, cast
MongoDB Atlas Vector Search: Stores embeddings and performs similarity search
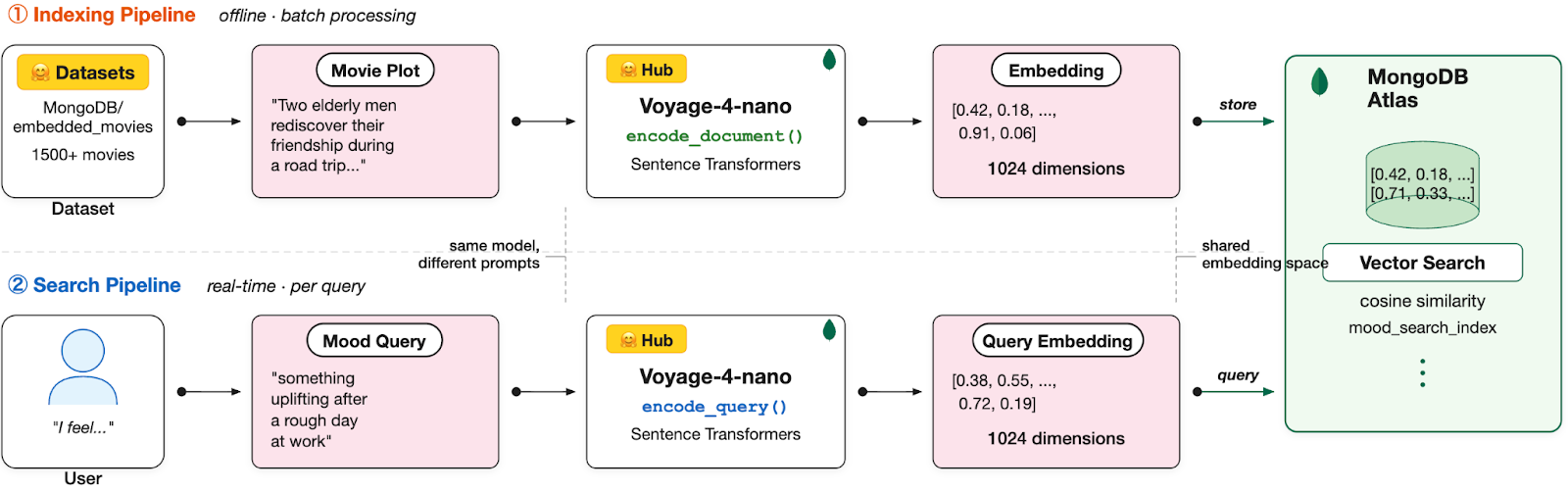
Understanding voyage-4-nano
voyage-4-nano is the smallest model in Voyage AI's latest embedding series, released with open-weights under the Apache 2.0 license. Voyage AI was acquired by MongoDB, and the Voyage 4 series models are now available through MongoDB Atlas. All models in the series (voyage-4-large, voyage-4, voyage-4-lite, and voyage-4-nano) produce compatible embeddings in a shared embedding space, allowing you to mix and match models within a single use case.
Although voyage-4-nano natively supports embeddings up to 2048 dimensions, we deliberately truncate them to 1024 dimensions using its Matryoshka embedding property. In practice, this provides a strong balance between semantic quality, storage efficiency, and vector search latency, while preserving stable ranking behavior.
Sentence Transformers
This tutorial uses Sentence Transformers, a Python library built on top of Hugging Face Transformers. It is specifically designed for working with embedding models and provides a simple API for generating text embeddings.
Why Sentence Transformers instead of raw Transformers? When working with embedding models, you need to handle tokenization, pooling, normalization, and prompt formatting. Sentence Transformers does all of this automatically in a single method call. The code is cleaner, there are fewer potential errors, and you get built-in features like batch processing with progress bars.
Under the hood, Sentence Transformers still uses Hugging Face Transformers to load and run the model.
Configure the development environment
Let's get started!
Create the Project Structure
Install dependencies
Create the requirements.txt file:
Create a Python virtual environment and install dependencies:
Run MongoDB Atlas locally
Use Atlas CLI to create a local deployment with Vector Search support:
Choose local when prompted. Once ready, you'll receive a connection string like:
Configure environment variables
Create the .env file:
I use 1024 dimensions as a balance between retrieval quality and storage efficiency. You can experiment with 2048 (max retrieval quality) or 512 (faster queries).
Implement system components
Database module
The database module manages MongoDB connections and creates the vector search index. The index must match the embedding dimensions specified in our configuration.
AI module with voyage-4-nano
The AI module loads voyage-4-nano from Hugging Face Hub and provides methods for generating embeddings. We use the sentence-transformers library for a clean API.
voyage-4-nano uses different prompts for queries and documents:
encode_query() prepends: "Represent the query for retrieving supporting documents:"
encode_document() prepends: "Represent the document for retrieval: "
This asymmetric encoding improves retrieval quality.
Data indexing module
The indexer downloads the movie dataset from Hugging Face, generates fresh embeddings with voyage-4-nano, and stores everything in MongoDB.
Search API
The FastAPI application exposes the mood-based search endpoint. Users describe their mood, and the system returns semantically matching movies.
Package initialization
Project structure
Your final project structure should look like this:
Run and test
Index the data
First, run the indexer to download movies from Hugging Face and generate embeddings:
Expected output:
Start the API server
Test mood-based queries
Query 1: Feel-good movie after a tough day
Response:
The system returned action films with themes of personal transformation and helping others. Scores around 0.65 show moderate similarity because "uplifting" is an abstract concept that does not appear directly in plot text.
Query 2: Emotional catharsis
Response:
The system found films with emotionally heavy themes. "Tae Guk Gi" is a war drama about brothers forced to fight against each other. "Split Decisions" deals with loss and revenge after a boxer's death. The word "tears" in "The Wedding Party" plot directly matched the query's emotional intent.
Query 3: With filters
Response:
With strict filters (rating >= 7.5, genre = Action), only one movie matched. Notice the significantly higher score of 0.761 compared to previous queries. The phrase "exciting adventure" directly aligns with "over-the-top action" in the plot description. This demonstrates that concrete, descriptive mood queries produce stronger semantic matches than abstract emotional ones.
Key observations
Abstract mood queries ("uplifting", "emotionally moved") score 0.62 to 0.67
Concrete descriptions ("exciting adventure") score 0.75+
Filters help find better matches even with fewer results
The system understands themes even without exact word matches
Comparing embedding dimensions
One unique advantage of voyage-4-nano's Matryoshka embeddings is the ability to experiment with different dimensions. Let's compare how dimension choice affects results.
Create a test script:
Run the script:
Result:
In this example, all three dimension settings correctly rank the plots in the same order: the friendship story scores highest, the robot companion story is second (thematically related through companionship), and the violent thriller scores lowest.
The key differences:
Discrimination gap: With 2048 dimensions, the gap between the best match (0.4496) and worst match (0.1472) is 0.302. With 256 dimensions, the gap is larger at 0.397 (0.4139 minus 0.0168). Interestingly, lower dimensions can produce wider gaps due to more aggressive compression of the embedding space, but this doesn't necessarily mean better quality. The absolute similarity scores are lower and less reliable.
Ranking stability: In many cases, the top-ranked results will remain consistent across dimensions. However, lower dimensions will see a slight decrease in retrieval quality compared to the full 2048-dimensional vector.
When dimensions matter: If your application requires maximum accuracy and the ability to distinguish between very fine semantic nuances, higher dimensions are the best choice. However, if you have constraints around storage costs and query latency, lower dimensions may be a better fit, as they offer significant efficiency gains with only a marginal trade-off in retrieval precision.
Practical recommendation: Start with 1024 dimensions as a balanced default. Drop to 512 if storage is a concern. Use 2048 only when you need maximum precision for nuanced queries.
Next Steps