Suppose you are building a recommendation engine for your app. When you display a product page, you want to show other products that are “like” this product in a semantic sense – for example, you might show speakers and cables as a related product for a record player. Folks are often reaching for dense vector search to serve these kinds of applications, as embedding models are good at capturing semantic similarity. When you get it working, you might notice it’s not as fast as you hope. Dense vectors tend to be large (4-12KB), and scoring matches involves computing a geometric distance metric between a query vector and vectors in the database.
Figure 1. A query vector (green) and the 5 nearest neighbors in 2-dimensional space by Euclidean measurement.
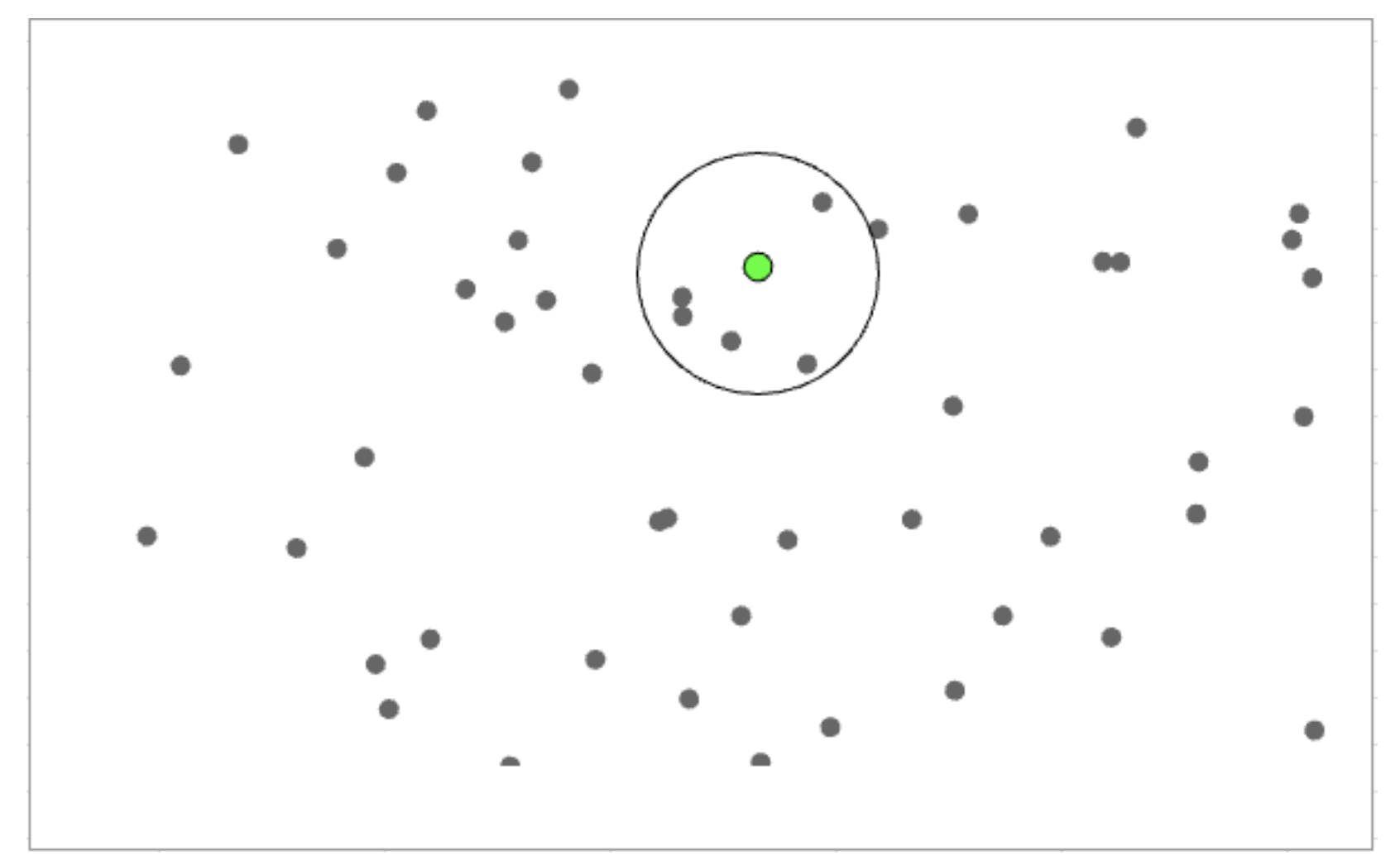
In more traditional index types, you might be able to avoid work at query time by sorting the contents of the database or examining prefixes of a key. In dense vector search, this doesn’t really work due to the Curse of Dimensionality: there’s no global ordering of vectors that serves as a proxy for distance, and in general, we can’t compute an unbiased distance estimate from a partial vector. This property makes it very tricky to build an efficient vector index.
If you observe a query workload on an Atlas Vector Search cluster, it seems clear that the CPU is being used intensively. This isn’t the whole story, though, and Chris Hegarty and I worked together on a pair of changes to Lucene, the open source search engine that powers Atlas Vector Search, to help speed up these workloads.
Vector search and memory latency
Vector search indexes often have a working set on the order of 10s of GB of vector data, but to compute the distance between two vectors, the data needs to be in the CPU cache. The largest cache on most CPUs is on the order of 16-64MB on most hosts, which is often much smaller than the data set. The CPU is generally very clever about handling memory access, anticipating the application’s needs and fetching data into memory in advance of it being used. What if the CPU can’t anticipate your next move? In those cases, your application may be bound by memory latency instead of raw compute as the CPU stalls waiting for data to arrive.
Atlas Vector Search is one of those memory latency-bound applications. Like many other vector databases, we use HNSW (Hierarchical Navigable Small World) indices for vector data. HNSW builds a graph to represent the index, where each vertex represents a single dense vector and each edge between two vertices represents a “close” relationship by distance.
Figure 2. Visiting neighbors of a vector/graph vertex.
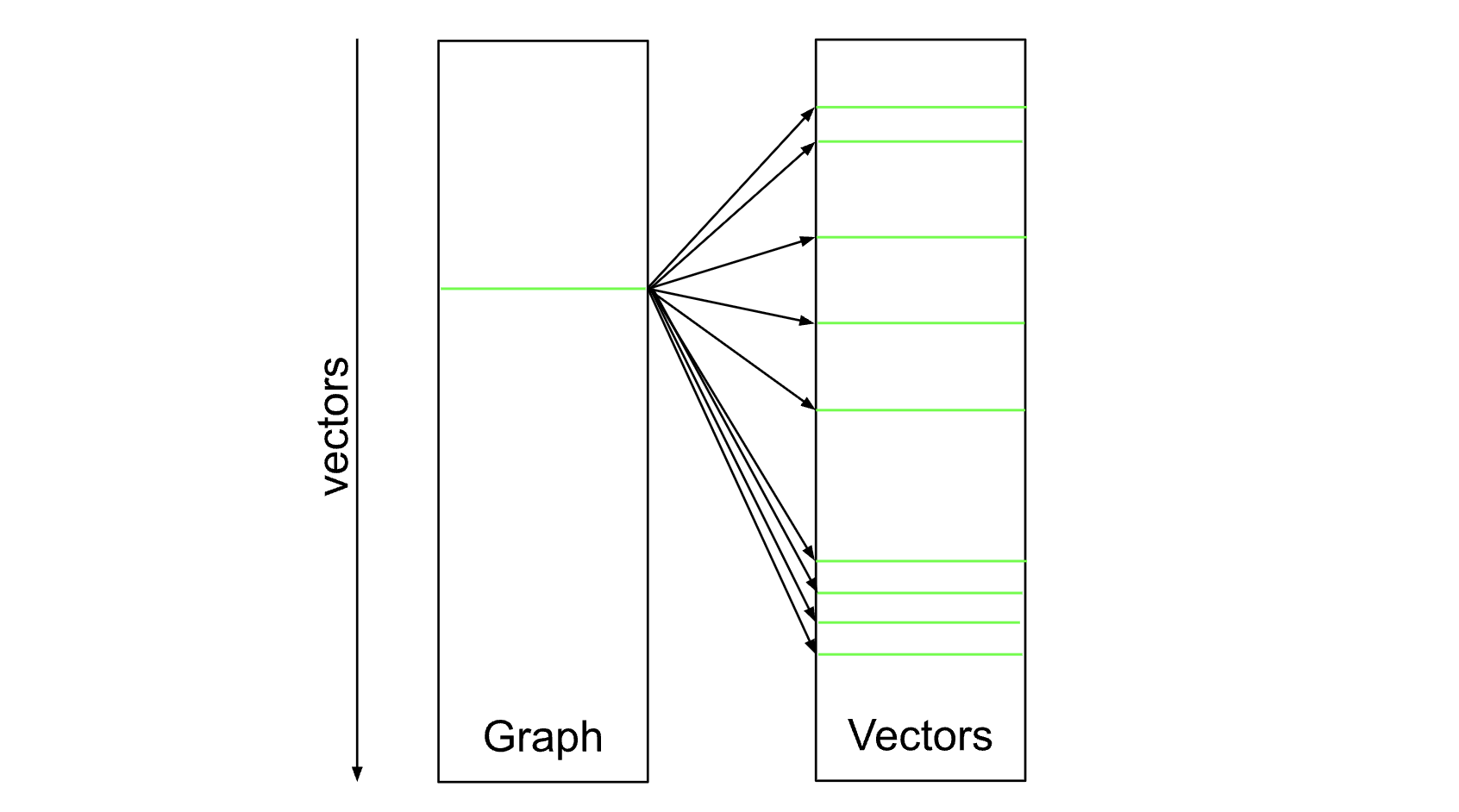
Searching the graph resembles a random walk or pointer chase: I pull a vertex from a priority queue, then score the query against each of the listed edges and insert the results back into the priority queue. Scoring each of these edges will take us to a random location in memory – forcing the CPU to pull data from main memory into its cache. Fetching data from main memory takes about 150ns on most common server CPUs, which is noticeably more expensive than computing the distance between two vectors in most configurations – for instance, I can compute the distance between two 1024-dimensional float vectors in just 60ns on an M2 Mac. I can’t make memory access any faster than it is today, so I’m left with doing what the CPU can’t do – prefetching data based on application-specific knowledge to hide the memory latency.
Bulk scoring
The outbound edges from each vertex in the graph are not ordered in any meaningful way, so we took advantage of this in the changes that we contributed to Lucene. The first change introduces an API for bulk scoring, allowing the implementation to compute the distance between a query vector and several database vectors at the same time. The second change utilizes the bulk scoring API to accelerate float vector scoring. This optimization takes advantage of instruction-level parallelism in the CPU – scoring 4 database vectors at a time against the query allows the CPU to issue multiple loads that go to main memory at once, hiding some of the memory latency and increasing throughput.
Figure 3. Bulk float vector scoring was introduced at point JF.
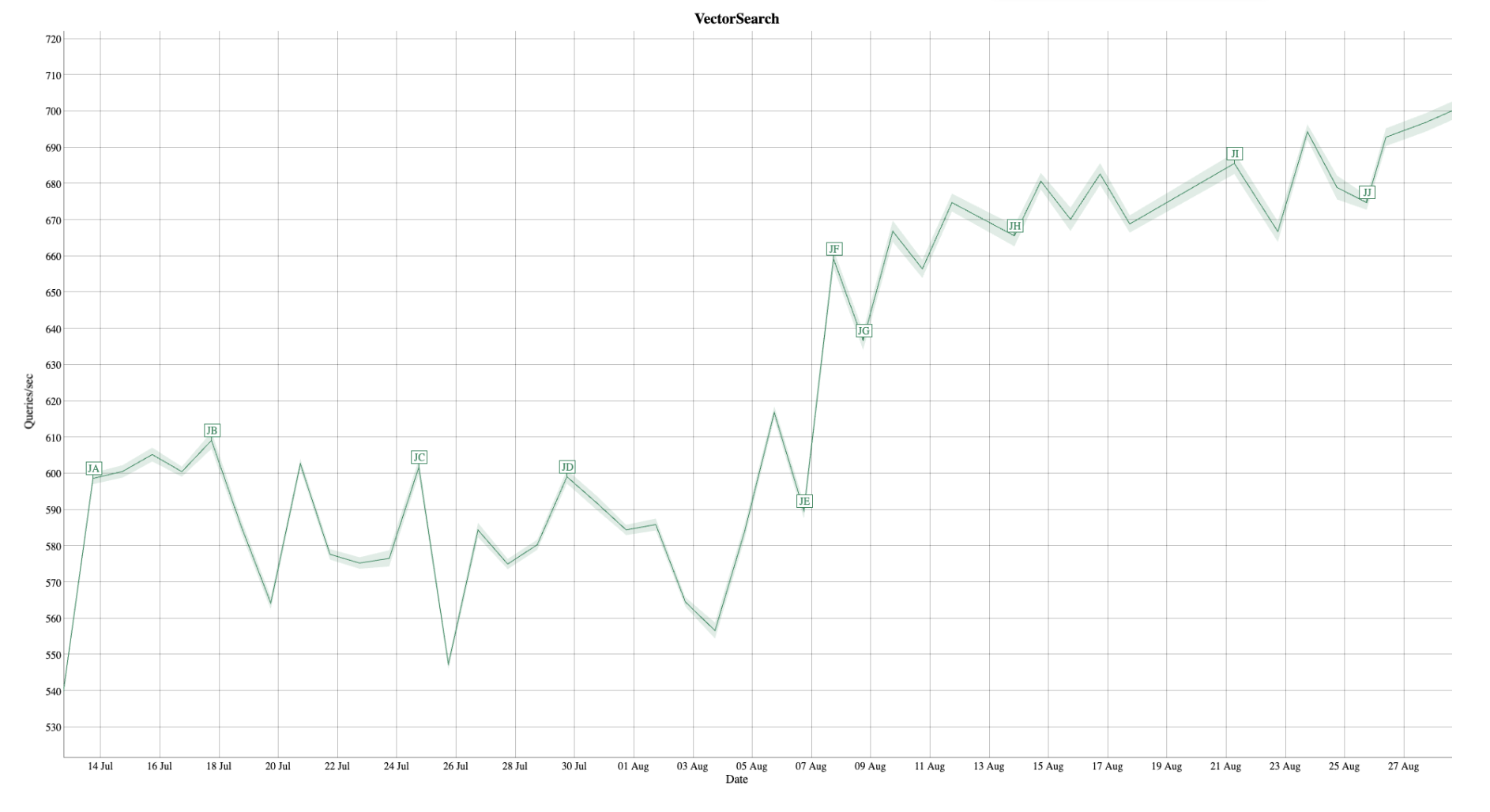
In microbenchmarks this resulted in a nearly 2x speed up; in the nightly Lucene benchmark this resulted in a ~10% query performance improvement (point “JF”). This yields improvements without any change to on-disk formats or data structures – performance improves simply by upgrading the library. Performance optimizations that prefetch memory often do this speculatively, which can exhaust memory bandwidth, but in our case, these are bytes we would have consumed anyway, so this change does not introduce a new performance bottleneck.
Future work
There are a couple of directions for future work here: wide and deep. On the wide end, implementing a similar approach for other vector formats, including pre-quantized input vectors and auto-quantized vectors, could improve performance for more workloads. On the deep end, bulk scoring could be integrated into the native C vector scoring support recently added to Lucene. When working with native code, there are also new options to use C __builtin_prefetch intrinsics to explicitly interact with the hardware prefetcher.
This does not solve working set size problems for Lucene’s vector search implementation. Using a graph means that access is random, and any data set that is larger than memory will still suffer a big latency penalty as vector data is read from storage during graph traversal. Performance of this workload could still be improved with bulk scoring since we now have an opportunity to parallelize the necessary IO using Java Virtual Threads or a platform-specific IO reactor interface.
Next Steps
To learn more about what Atlas Vector Search can do, see the vector search Quick Start guide.