The more you know about your customers, the better you can attract them and increase their lifetime value to your business. The ability of modern systems to collect, store, and leverage customer data across disparate systems has raised the bar for what it means to understand your customer. To the winner goes the spoils, and the spoils go to the companies that navigate the last mile in the journey to attain true Customer 360: they leave no customer data behind. They hunt down every relevant source of customer data in their reach and turn them into valuable insight – without breaking a sweat.
How customer acquisition costs and customer lifetime value impacts business success
Two calculations are critical to understanding modeling how to grow your business.
Customer Acquisition Costs (CAC): the amount of money a company spends to get a new customer
Customer Lifetime Value (CLV): the net profit attributed to the customer relationship for the duration of the time they use a product
Note that “customer” is front and center in both terms. Capturing the data behind these two calculations correctly and continuously on a timely basis across the whole customer journey – from first touch to renewals – and making sense of it, is essential to understanding how to grow and retain your customers. These calculations must be performed on multiple customers and their interactions over a span of years. Analytical and AI models that calculate CLV and LTV need to be fed up-to-date, contextual, reliable data to identify relevant patterns.
Historical customer data guides future CLV and influences decisions on how to optimize investments in sales, marketing, and customer service to positively impact the customer’s future purchase and product adoption behaviors. Similarly, customer data analysis guides decisions on how to optimize sales and marketing investments to dial-in CAC for the fastest and most profitable conversion of prospects to customers.
How successful a company is at leveraging CLV, and LTV calculations depends on their ability to link different data sources and formats, and integrate all of the internal and external systems required for modeling. Until now, companies have struggled to accomplish this because data joining technologies have fallen short for one or more of these reasons: cost, complexity, and scalability.
Forrester1 declared Activation Of Unstructured “Dark” Data a 2022 mega trend. According to Forrester”
"The question is no longer about collecting enough data — it’s about ensuring that the data is usable and liberated from company silos to create new streams of value. In 2022, being “data driven” must become more than just a slogan — the next wave of business transformation will hinge on activating “dark” data (data that organizations collect but do not effectively use) to drive differentiated experiences for both customers and employees."
Creating that holistic 360° view of your customer is a business imperative for every organization–but creating a unified view or golden record of your customers is hard and expensive, especially if you want to capture and make sense of the structured and coherent unstructured data and include unstructured “dark” data.
Why creating a customer 360 is a technical challenge
Customer 360 data resides in your ecommerce platforms, Customer Relationship Management (CRM), Sales Force Automation (SFA), ERP, Customer Service systems, Partner Relationship Management programs, loyalty programs, payment portals, web apps, mobile apps and more–across business units and functional departments. Cross-object reporting in a single application (like Salesforce) can be a challenge but cross application reporting (SFDC + Zoom + Zendesk + Parquet files in a data lake) present an even bigger set of challenges with no common identifiers in the data collected from various applications. The data not only comes from a variety of sources but also in different formats significant time and data engineering effort is required to combine data to create the elusive golden record.
To compound the challenge, different teams require different views of the same data which demands different flavors of customer 360:
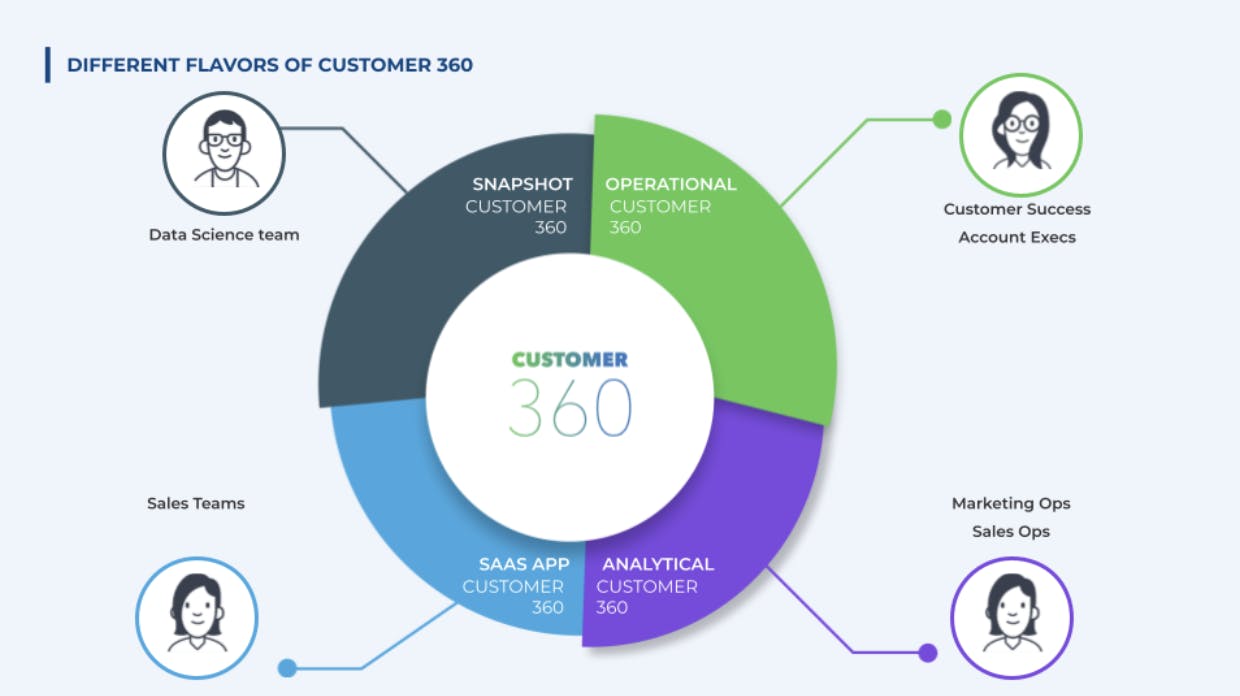
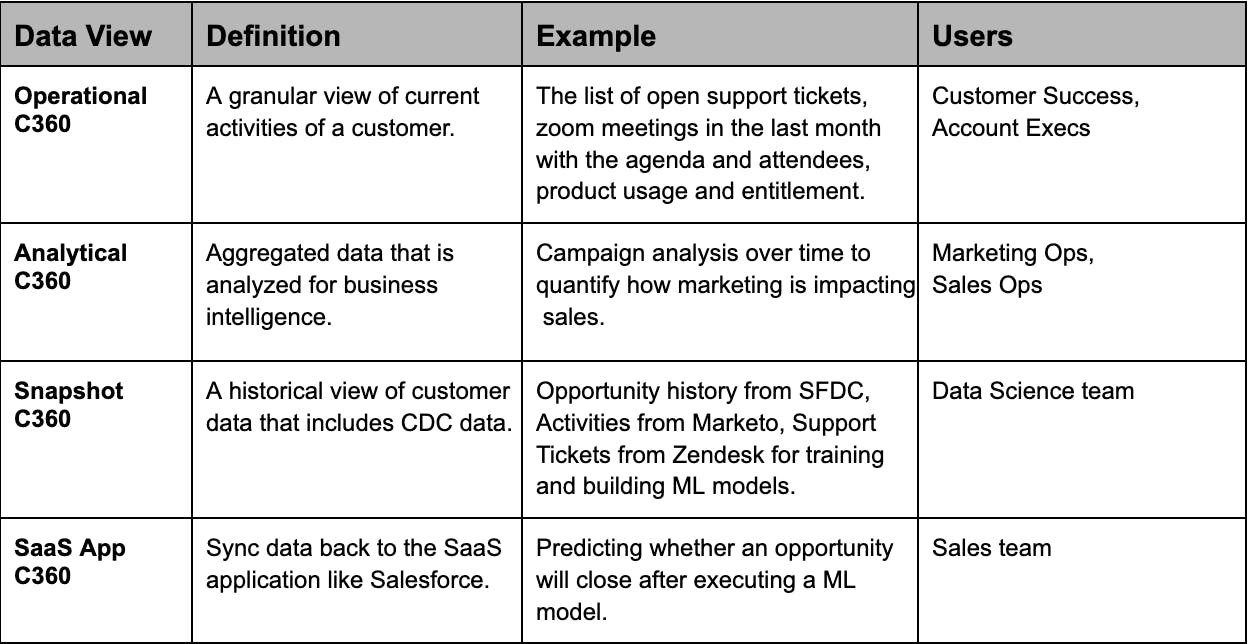
The power to harness customer data where it belongs: Business users
The traditional approach to creating a customer 360 takes the view that data from disparate sources like Prospecting (outreach.io), CRM(Salesforce), Marketing Automation (Marketo), Web Meetings (Zoom) and Support (Zendesk) needs to be combined, converted into a star or snowflake schema and deposited in an enterprise data warehouse. Or buy a Customer Data Platform (CDP) that makes yet another copy of your data that is a black box with no visibility into how data is processed. Keep in mind, this approach requires months of back and forth with the IT organization, resulting in cost and time overruns that lead to costly, stale customer 360 data that is no longer relevant.

Dataworkz gives anyone from marketing ops to sales leaders the ability to assemble a complete, reliable customer 360 in minutes or hours. Unlike a legacy CDP, Dataworkz eliminates data security concerns as a barrier because it does the job without storing customer data. Users configure their sources and destinations, then Dataworkz acts as the “personal data engineer” bringing together data, processing, and ML with a visual no-code interface for business users – with the option to use SQL.
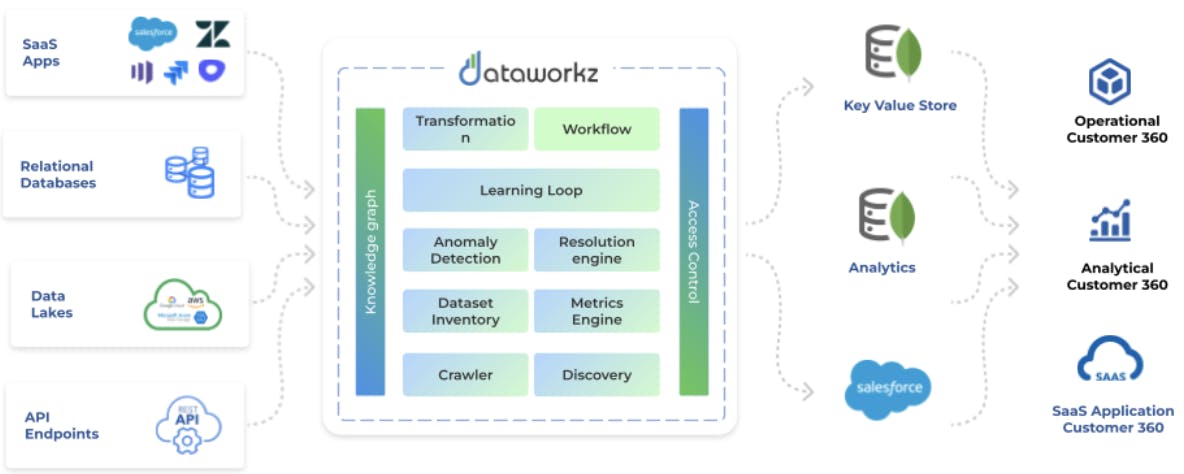
A visual, easy-to-use with a no-code approach, to seamlessly gain a 360 view of your entire customer journey is the most innovative and efficient way to gain the contextual and quick customer insights necessary to grow your business.
No more kinks in your Customer 360 data: Dataworkz and MongoDB Atlas
Getting the best of all breeds is the mantra of smart, future-proof solutions. Capitalizing on Dataworkz and MongoDB Atlas together is a “no brainer.”
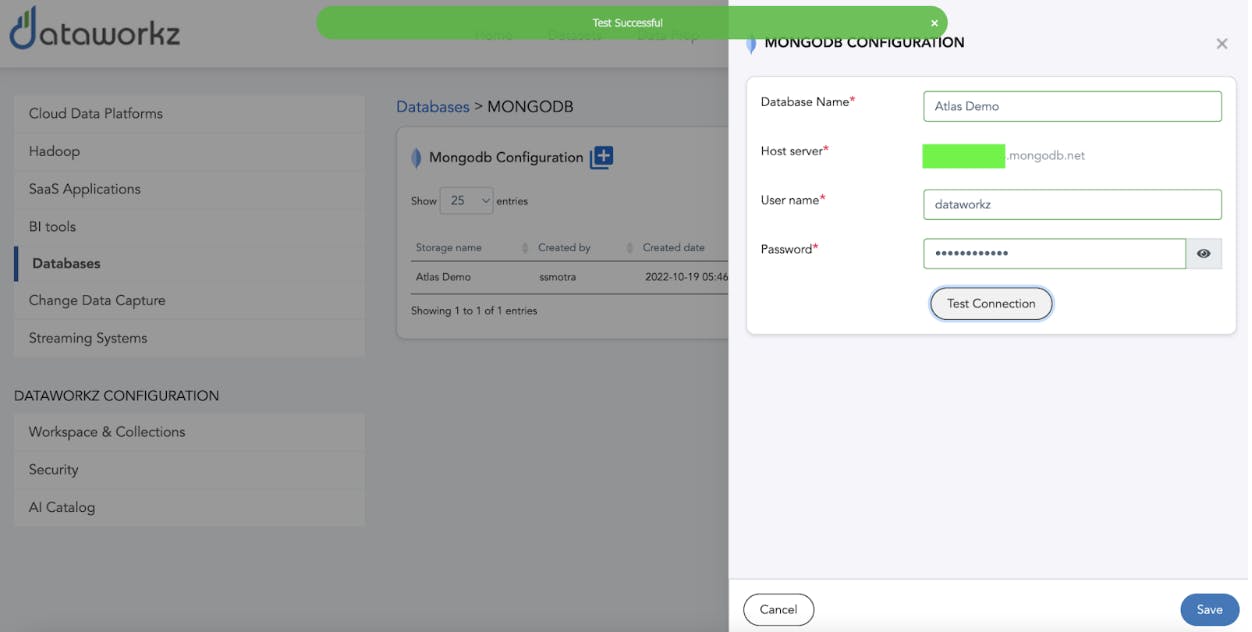
Connecting Dataworkz and Atlas
Add the Dataworkz cluster IP to the list of white listed IP addresses in the “network access” section of the Atlas console.
Navigate to the “Databases'' section in the Dataworkz configuration section and specify the Atlas cluster IP address, username and password.
Here are three ways this partnership can help:
Get out of your RDBMS: Combining data from different sources, in different formats, with changing schema, is exceptionally hard, if not impossible with a rigid relational model. But MongoDB Atlas uses a JSON data model with a flexible schema which makes it ideal for building a customer 360.
Work with a flexible, adaptive construct: Agility is a key tenet for organizations constantly adapting to their customer’s ever changing needs. With dynamic schemas, you are no longer worried about changes in source data breaking downstream applications.
In minutes, not months: Dataworkz and MongoDB Atlas are SaaS services with usage based pricing. You get started without an upfront investment or hiring a team of data engineers and scientists and get to value in a matter of minutes and not weeks or months.
Customer case study - Gunderson Dettmer
Gunderson Dettmer is the preeminent international law firm with an exclusive focus on the innovation economy. In order to serve their clients, they need to leverage the latest and greatest information about corporate innovators anywhere in the world, from a wide variety of disparate data sources.
To accomplish this, they had to transform and integrate multiple data sources into a coherent, evolving data warehouse and attempt to match financial, legal, and personnel information across “un-mappable” data sets without any common identifiers or keys. The process had to be scalable, reliable, flexible, and continuous since new information and new data sources are added daily.
The objective
Gunderson's data warehouse and analytics team were tasked with creating a brand new process for unlocking data insights by weaving together previously un-mappable data sets and serving them up to the organization to create an evolving, holistic view of the Venture Capital universe. The resulting data warehouse would be leveraged by downstream users, including data analysts, upper management, marketing, and other firm stakeholders.
The challenge with no single source of truth
Gunderson Dettmer needed to compare attributes for companies and venture capital investors across multiple internal and external datasets, but there were no globally unique identifiers available to join the datasets in most cases, and there were no off-the-shelf, end-to-end solutions to solve the problem. Data sources included Gunderson’s on-premise proprietary data held in a SQL-based relational database, CSV data dumps from Pitchbook, Crunchbase, and various PDF files, and other potential sources, as available. Although the data sets overlapped, there were no common keys or identifiers across them.
How they used power of MongoDB Atlas + Dataworkz
Before the data warehouse team at Gunderson got involved, the de facto approach was to create interim data sets for the entity matching process by extracting data from the relational database, performing multiple Excel spreadsheet lookups to enrich it, and then manually matching the exported data to the external data sources. This process typically took 3-4 weeks in order to create a unified data set that could be used for analytics. The process was static and needed to be repeated (complete with manual record matching) when any of the data sources were updated.
Not thrilled with this process, the data warehouse team created python scripts using Request and Fuzzy-Wuzzy modules to call a REST API endpoint, programmatically joining the datasets and then performing fuzzy logic for matching. Unfortunately, the REST API and Fuzzy matched datasets created were also one-time-only events and could not be leveraged for automating future analysis or ongoing data integration.
This is where MongoDB Atlas was introduced to change the one-time only dataset into a JSON collection that could be reused. It required transforming the resulting datasets into rich, nested JSON objects that could be searched and queried using MongoDB Atlas. While this reduced the data set preparation time to about one week, there was still a large human review process that required Subject Matter Experts (SMEs) for difficult matches that fell out of the simplistic, fuzzy match parameters.
For the final step in this project, they replaced the python scripts for transforming raw data into the JSON data model with Dataworkz to ingest data into MongoDB Atlas. The Dataworkz platform provided crucial features that vastly simplified the process of weaving the disparate “unmappable” data sets together into a coherent whole.
Using Dataworkz allowed Gunderson’s team to eliminate their python scripts and enabled:
Discovery, introspection, and manipulation of Parquet, BSON, JSON, CSV, structured, and unstructured data sources by bringing them all onto the same playing field for transformation,
A clearer understanding of the possible challenges to creating easy-to-match collections,
Automatically perform JSON format transformations without code,
The ability to describe and execute no-code multi-stage pattern matching
Automate their ingestion, transformation, and data storage pipeline in a day (rather than the months that it took to write the original python scripts),
Provide continuous automatic data integration within minutes, with improved accuracy, lower human intervention, and built-in data monitoring and governance to ensure against data stream contamination in the future.
Don't struggle any more for the metrics you need
Whether you are a Chief Revenue Officer, CMO, head of a regional team, leading customer service, or a data analyst/scientist; you no longer need to spend extended time and dollars to gain the insights that should be available at your fingertips. Timely, reliable CAC and CLV metrics that are correct no matter what changes occur in your processes, definitions, calculations, or systems can be yours – when you need them – across departments, product lines, and business units. Dataworkz marks the entry of a new class of data platform that delivers the insights you need – accessible across any data, from any source, combined for any use, when you need it.