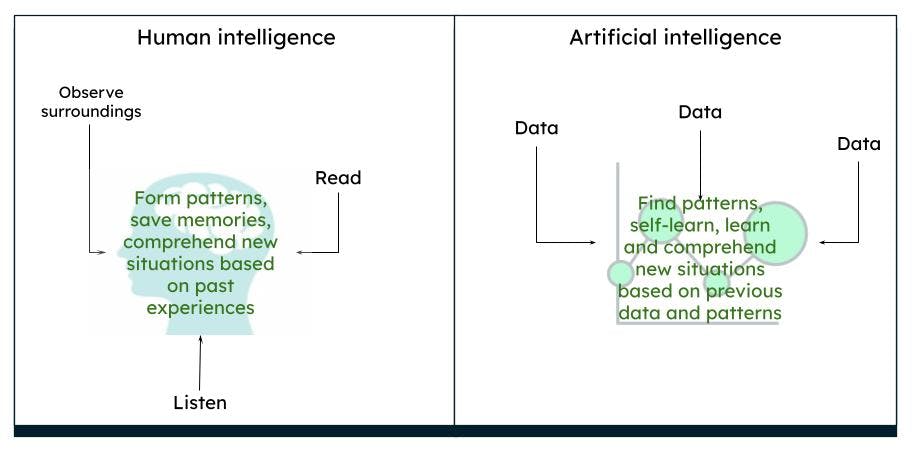
Types of AI
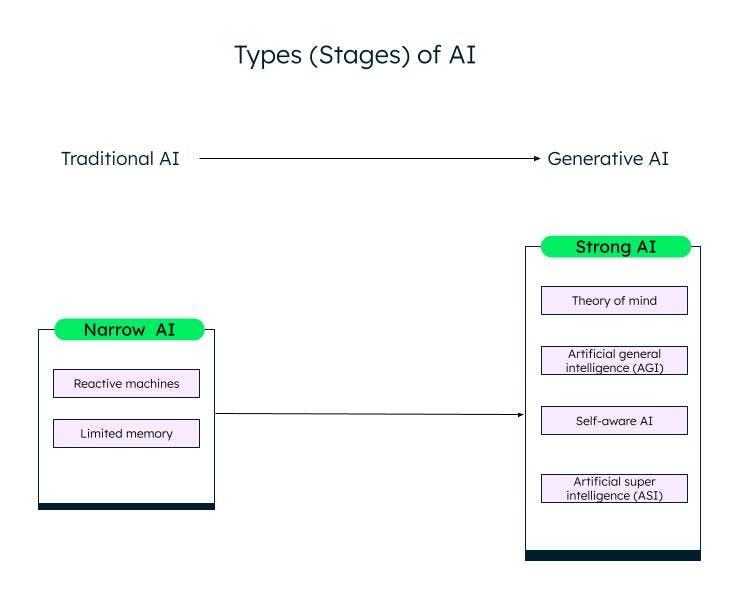
A broad classification of artificial intelligence, based on its capability, is narrow (or weak) AI and strong AI. Through research and advancements in the field of machine learning and deep learning algorithms, we are moving from weak AI to strong AI.
Narrow AI
Weak AI/narrow AI, or artificial narrow intelligence (ANI), systems are trained to perform specific tasks and have limited capabilities based on the data they are trained on. They are also known as traditional AI systems, where the system can respond intelligently based on a certain set of inputs and rules. However, it cannot create anything new.
Traditional or weak AIs are further classified into two categories: reactive machines and limited memory.
Reactive machines
The oldest form of artificial intelligence was the reactive machines that did not have a memory but could emulate a human’s ability to respond to different stimuli. They cannot learn from their experience (no memory) and base their response on a limited combination of inputs. IBM’s Deep Blue machine is a reactive machine.
Limited memory AI
Limited memory systems have memory and can learn and make decisions based on the input data provided. Most of the AI we see—self-driving cars, chatbots, personal assistants like Alexa, and recommendation systems like that of Netflix—are all examples of limited memory AIs.
Strong AI
With the innovation of ChatGPT and other similar generative AI models, we are slowly entering the strong AI phase. Generative AI is a sort of next-gen AI, which can create something new based on user inputs. ChatGPT is an example of generative AI based on the large language model (LLM). Much more work needs to be done in strong AI, which can be categorized as follows:
Theory of mind (ToM)
ToM is a cognitive skill to understand the different mental states—like beliefs, thoughts, and the feelings of others—to explain their behavior and actions. Researchers are working on applying ToM to AI with the goal of enabling AI systems to understand human beings' emotions and states of mind. ChatGPT, the new AI system that can interact with humans in natural language and produce new content, has demonstrated some form of theory of mind during testing. However, it still does not possess the ability to comprehend desires, beliefs, or emotions. The responses of ChatGPT are based on data and common patterns.
Artificial general intelligence (AGI)
Artificial general intelligence is the next stage of AI development, where an AI system or agent will behave exactly like a human, including independently building multiple competencies and functionalities as well as forming connections and generalizations, with little or no training.
Self-aware
The next stage is a point of AI singularity, where machines will be aware of self. They will have their own desires, beliefs, and emotions, in addition to understanding human emotions, desires, and beliefs. Self-aware agents can be used in healthcare and robotics.
Artificial super intelligence (ASI)
Self-aware AI may lead to ASI, where AI agents might become super artificially intelligent systems and overpower humans in values and motives. Self-aware AIs and ASIs could raise problems with employment and ethics, for which researchers and governments need to be alert and form rules and guidelines.
Different stages (types) of AI