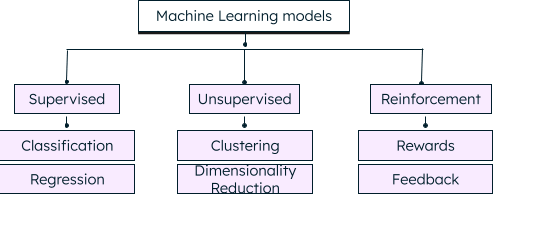
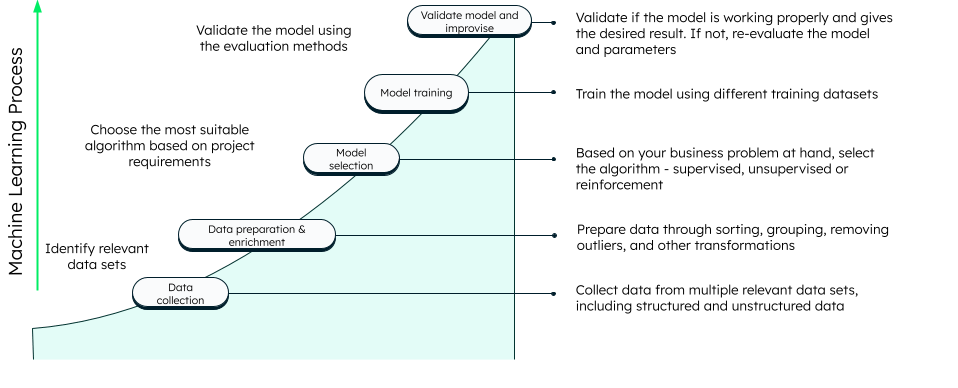
Supervised machine learning
As the name says, in a supervised learning algorithm, the machine is fed with the input training data and the expected output. The machine acquires knowledge from the training data and comes up with the right function that determines the relationship between the input and the output. The function is then applied to a new set of data, and testing is done to see if the desired output is achieved.
A similar analogy is a child's brain, which is initially a clean slate. We show him/her people of different age groups and by visualizing the features, they are able to distinguish between girl, boy, young, old, and so on. Now, when the child sees a new person, with the information already known, he/she is able to relate and identify the person to be one of the known categories (old, young, girl, boy).
Supervised machine learning algorithms
Supervised learning algorithms require a huge amount of high-quality labeled data for producing accurate results. They are divided into two main categories:
Classification
In a classification mode, the ML algorithm puts the data into one of the categories. For example, if you have a dataset of shapes with characteristics like 2D, triangle, no sides, all sides equal, four sides, and so on, your model can categorize the data based on these characteristics as triangle, square, circle, and so on.
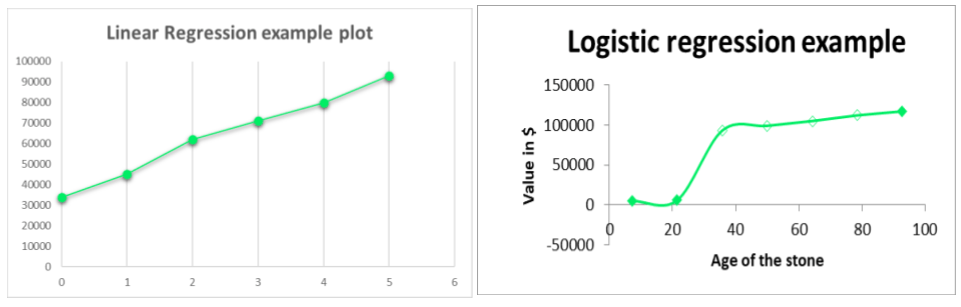
Regression
Regression uses statistical methods to predict an outcome or a continuous value, based on independent input variables. For example, by analyzing historical data that includes key features (input variables) such as mileage, age, model, after-sales service, value-adds, and durability of cars, a regression model can be developed to accurately predict the price of a particular second-hand car.
Some popular supervised learning algorithms are:
Naive Bayes: Naive Bayes is based on the Bayes theorem and is very effective for classification problems, mainly text classification. It is based on the probability of occurrence of a feature independent of the other features. Some popular applications of Naive Bayes include spam filtering, sentiment analysis, and credit scoring.
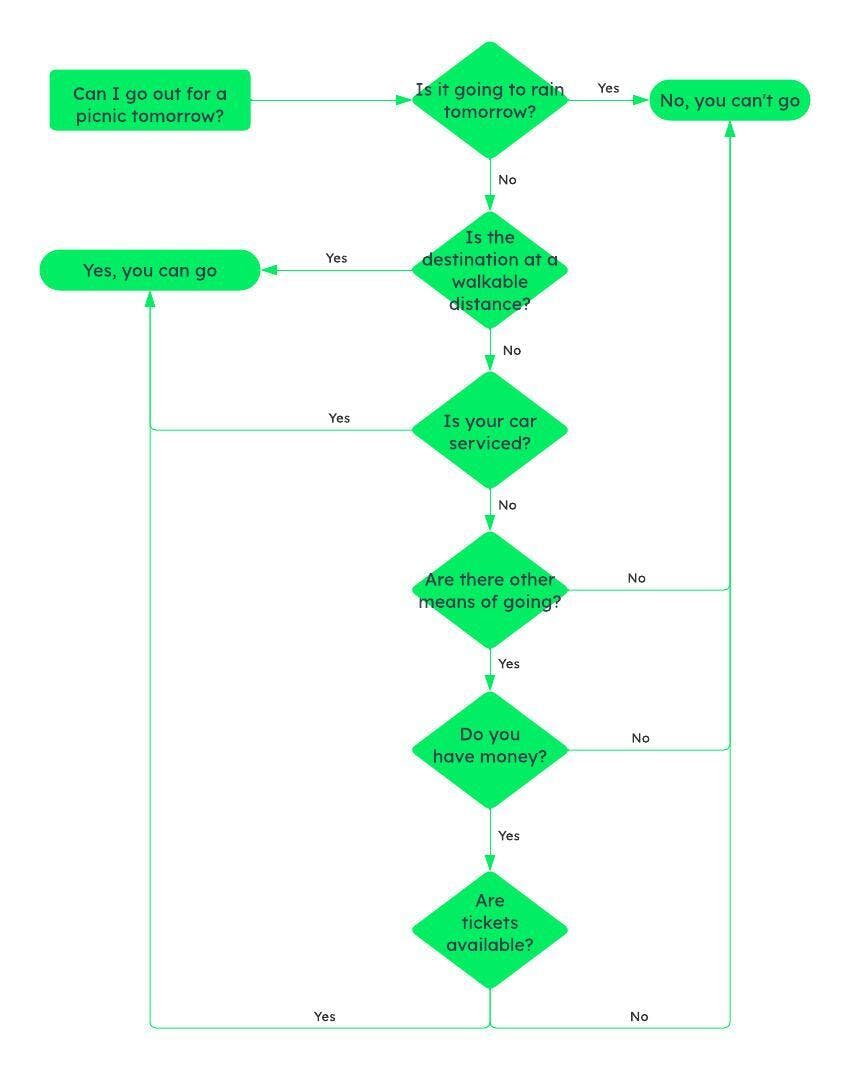
Decision Tree: Decision trees can be used for classification and regression. Decision trees follow a hierarchical structure, with the root node being the first node that represents the main problem/decision. From there, based on a series of questions, the tree is split into various paths depending on the answer (mostly yes/no). Here’s how a decision tree makes decisions.
How decision tree splits to solve yes/no problems