With the resurgence of ransomware attacks in 2023 causing U.S. companies to pay cybercriminals $449.1 million in just the first six months of this year alone, it is more imperative than ever for organizations to have strong risk management practices to fall back on in the event of cyberattack — this includes a best-in-class backup and restore function.
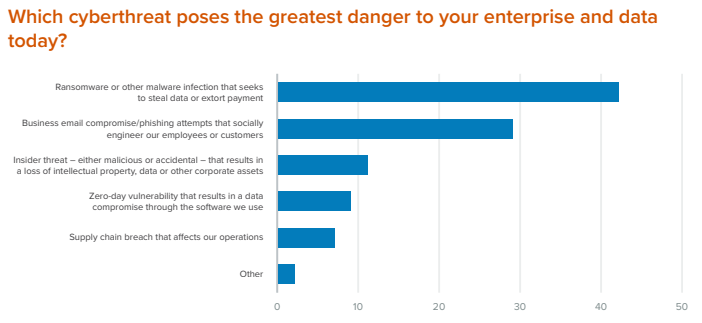
Source: Teranova Security, 2023
Read on to discover what backup and restore means, how it works, common backup restore solutions, and how to choose the right backup restore solution for you.
Table of contents
- What does database backup and restore mean?
- How does backup and restore work?
- Common backup restore solutions
- Choosing the right database backup and restore solution for you
- FAQs
What does database backup and restore mean?
There are two distinct elements in database backup and restore. The term “database backup” refers to making a copy of a database at a specific point in time, sometimes referred to as the current state. The database copy will include such elements as the actual current-state data within the database, along with additional elements such as the database schema. With that said, there are several different types of database backup methods to consider.
Types of backup methods
The three most commonly referenced backup methods include:
- Full backup: The entire database is copied and stored every time a database backup is executed.
- Incremental backup: Only changes made to the database since the last backup are copied and saved.
- Differential backup: Only the changes made to the database since the last full backup are copied and saved, meaning that changes from an incremental backup would not be saved.
.png)
Source: Business2Community, 2023
Some additional types of database backup methods include:
- Mirror backup: As the name implies, an exact copy (or mirror image) of the data is maintained. This means that any time a record is changed or deleted, it is changed or deleted in the database backup which can result in lost data due to human error.
- Continuous backup: Sometimes referred to as continuous data protection (CDP), continuous database backup provides just that — instant backup of data continuously. However, unlike mirror backup, continuous backup can restore data back to any point in time which minimizes potential data loss through human error.
Database restore, on the other hand, is used to bring a database back to its state/contents at a specific point in time (e.g., prior to a ransomware attack or data corruption). The desired database backup is simply loaded into the database, replacing the current data and restoring the database's current state to the desired point in time. The example below illustrates a database restore process when database access is impeded.
Example: Database recovery diagram
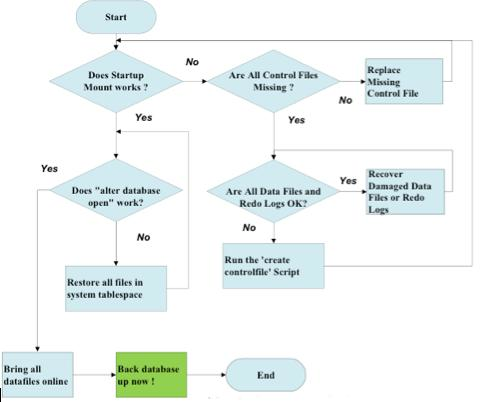
Source: ResearchGate, 2023
Database backup and restore processes are critical to maintaining data protection, business continuity, industry compliance, and disaster recovery levels needed to ensure an organization's reputation, viability, and ongoing operations.
How does backup and restore work?
There are several key elements to the backup and restore process, all of which comprise a best-practice database backup protocol.
Key elements of a backup and restore process
Evaluation of data assets
Prior to making decisions about the types of backup and restore practices appropriate for an organization, it's necessary to understand the criticality and nature of an organization's data assets. By identifying the criticality and changeability of various data assets, organizations can tailor their database backup and restore program to both optimally protect data while taking advantage of labor and cost savings as well.
Backup type
As previously discussed, there are different types of backup, including full backup, incremental backup, differential backup, mirror backup, and continuous backup. Each organization must review the pros and cons of each method to determine which is the right fit for its operations and data assets.
Backup schedule
Categorizing both the importance and changeability of data assets allows organizations to create customized backup schedules that best serve their needs. This means that critical databases may be backed up more frequently, while static or low-value data may be backed up less often.
Backup storage
There are a variety of backup storage options available to house backup data, including:
- On-premises storage: On-premises (or on-prem) storage involves the use of on-site servers to store an organization's database backup files. These resources are usually owned and maintained by the organization, but service contractors and vendors are also available to provide database backup storage.
- Cloud storage: Cloud backup storage involves saving data in off-site servers that are easily accessed via an internet connection. Third-party vendors usually manage cloud storage as a service, but larger corporations often will have their own private cloud solution available as well.
- Hybrid storage: A hybrid storage solution is one where backup data is stored both in the cloud and on-premises.
Backup execution
It's possible to execute database backup functions either manually or on an automated basis. For small or infrequent backup tasks, some organizations may choose a manual backup process. However, many organizations rely on their database management system (DBMS) to automate and execute routine backup tasks. Alternatively, other organizations may rely on their cloud backup services provider to execute their scheduled backup tasks.
Verification and monitoring
Just as important as the correct backup storage and execution, backup verification and monitoring ensure that critical data access is protected. A comprehensive system of backup monitoring and data integrity verification ensures the accuracy and completeness of each backup instance, as well as the ready access of the backup file(s) when required by users.
Restoring data
Whether database access is interrupted due to cybercrime, or data corruption occurs due to a system malfunction, database administrators (DBAs) must be ready to restore backup files or a complete copy of the database quickly. The complexity of this task is impacted not only by the type of data loss incurred but also by the type of database backup employed (e.g., incremental backups may need to be combined with other backup types to reach the required restore point). In addition, the type of backup storage employed may impact complexity (e.g., external drive vs. cloud backup). Regardless, the DBA must identify the needed database backup restore files and execute the restore process.
Recovery testing
Ongoing testing of the restore process for all database backups is needed to not only ensure the viability of the backups but also that access to those backups is available and functional. These recovery tests can be completed manually but many organizations choose to use software to schedule and conduct their recovery testing operations.
Common backup restore solutions
There are several backup and restore solutions available, ranging from simple manual procedures to sophisticated automated systems.
Manual backup
This approach involves manually exporting data to storage equipment such as an external hard drive or even a Google drive. While this type of solution can be time-consuming, requires direct employee action, and has an increased risk for error, it is also a low-cost solution that helps safeguard local files on a computer. Many small businesses find that manually creating their own backup is a cost-effective way to meet their interim needs.
DBMS native backup
Many software providers — such as Oracle, Microsoft, IBM, and MongoDB — offer database management systems (DBMSs) that include backup and restore tools. For example, MongoDB offers tools such as Mongodump and Ops Manager which can be used for backup and recovery.
As an interesting side note, this functionality is not limited to large corporate database DBMS. Your Apple or Android phone (e.g., iPhone, Samsung Galaxy) also includes this functionality. For example, when a Samsung Galaxy phone is purchased, the user is asked to create a Samsung account which also functions as an Android backup utility in the event of data loss.
Third-party backup software
Specialized backup software that works across various database systems can be purchased via license or as a service from third-party sellers such as Veeam, Rubrik, and Commvault. These software offerings include basic services such as automated database backup scheduling, data encryption, and application programming interfaces (APIs) that connect easily with popular storage systems.
Cloud-based backups
Cloud-based backup solutions offer scalability, ease of use, and built-in redundancy. And, because cloud backup solutions are often sold as a service, organizations are able to rely on service-provider expertise rather than directly employing those skills in-house. For example, MongoDB's cloud service MongoDB Atlas offers two types of fully managed database backup— continuous backup and cloud provider snapshots.
Choosing the right database backup and restore solution for you
Choosing the right database backup and restore solution involves assessing your organization's unique requirements, data compliance, and retention policies. It also requires an understanding of your recovery point objectives (RPOs), which refers to the age of files that must be recovered for operations to resume after a data loss, and your recovery time objectives (RTOs), which refers to the greatest amount of time your organization can operationally tolerate a loss of systems and database access and functionality. Finally, the breadth and depth of your employee's experience in backup restore and your budget should also factor into solution considerations.
Key questions to answer before choosing a database backup and restore solution
Objectives: What are the objectives being addressed by your backup and restore solution and which objectives are most important? Some possibilities include:
- Operational viability.
- To protect data in the event of a disk or network failure.
- Defense against cybercrime and ransomware attacks.
- To align with regulation compliance or insurance requirements.
Requirements: By considering your objectives and ranking them in order of importance, it's possible to create a requirements list that focuses on organizational priorities. For example:
- Is offsite backup storage via a device (e.g., external drive) acceptable, or must backups be stored in such a way that third parties can monitor them for compliance or insurance purposes (e.g., cloud storage or second-site servers)?
- What are your organization's RPO requirements (e.g., minutes, hours, days)?
- What are your organization's RTO requirements (e.g., minutes, hours, days)?
- Will your chosen solution be required to create hot backups (e.g., a backup made while the database is still in operation) or are cold backups (e.g., the database is taken offline for backup) acceptable?
- Do you require disaster recovery and failover functionality from your chosen solution (advanced functionality) or are your organizational requirements met with standard database backup and restore functionality?
- How long must specific backup instances be stored for operational, compliance, or insurance purposes? How will the duration and volume of backup storage and access required be addressed by each possible solution type and at what cost?
Internal employee experience: Does the necessary backup restore experience reside within your current employee base? If not, how easily acquired are personnel with the necessary skill set and how much will it cost to hire and retain them? Some organizations choose to hire additional staff or contractors if they don't possess the internal resources while others choose to rely on the specialized skill sets of cloud backup providers or third-party vendors. Which makes the most sense for your organization's budget, timeline, and long-term objectives?
Budget: As with any project, budget has a significant impact on solution choice. If current cash flow is an issue, perhaps backup software and an external hard drive may be acceptable for now with plans to move to a more advanced system at a later date. For others anticipating rapid growth and database backup requirements, a cloud solution with highly scalable virtual machines and advanced backup services may make sense financially over time. Considering the short-term costs while balancing the overall long-term costs and impact on operations will help define the right solution for your organization's needs today and in the future.