矢量数据库如何工作?
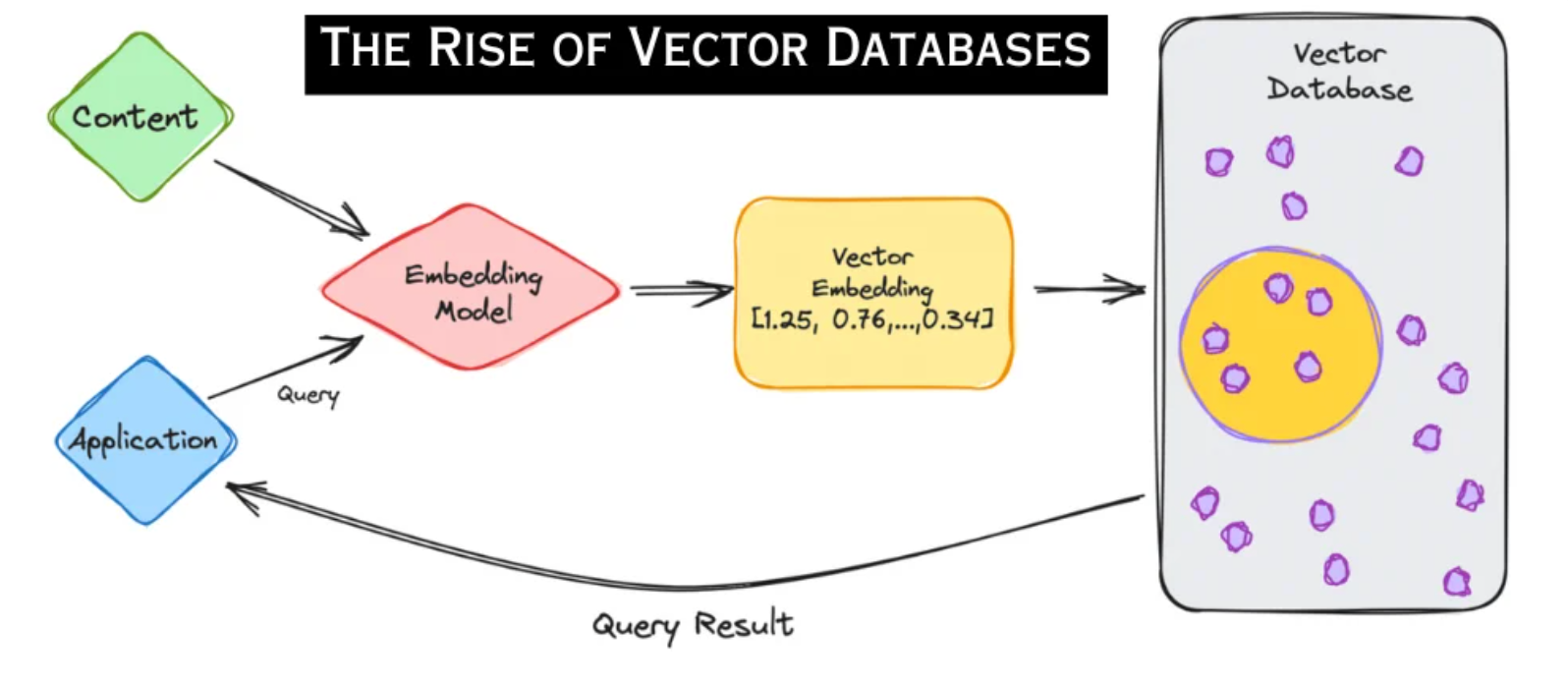
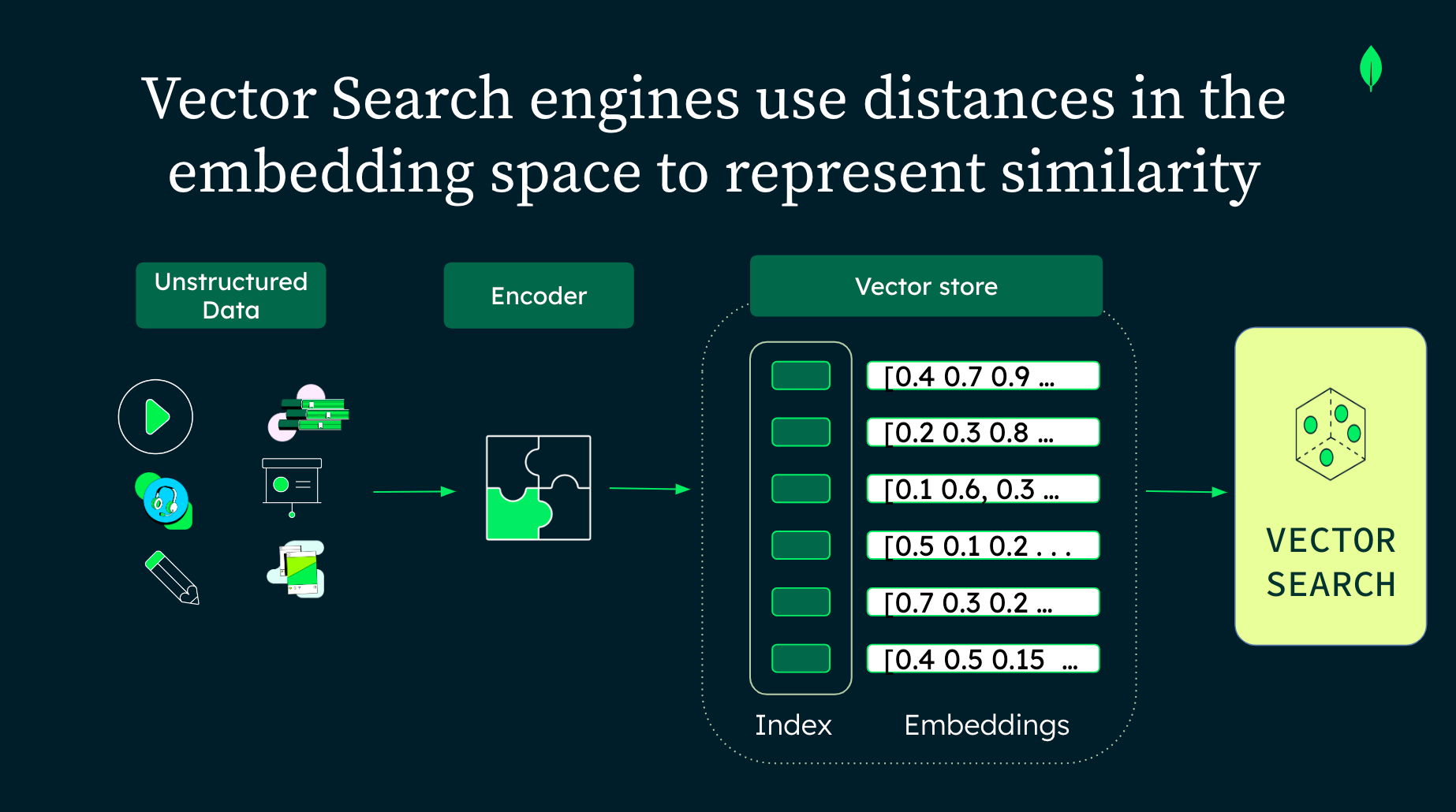
矢量数据库功能的核心是嵌入原则。 本质上,矢量或嵌入模型将数据转换为一致的格式:矢量。
虽然矢量就是一组有序的数字,但嵌入将其转换为各种数据类型的表示,包括文本、图像和音频。
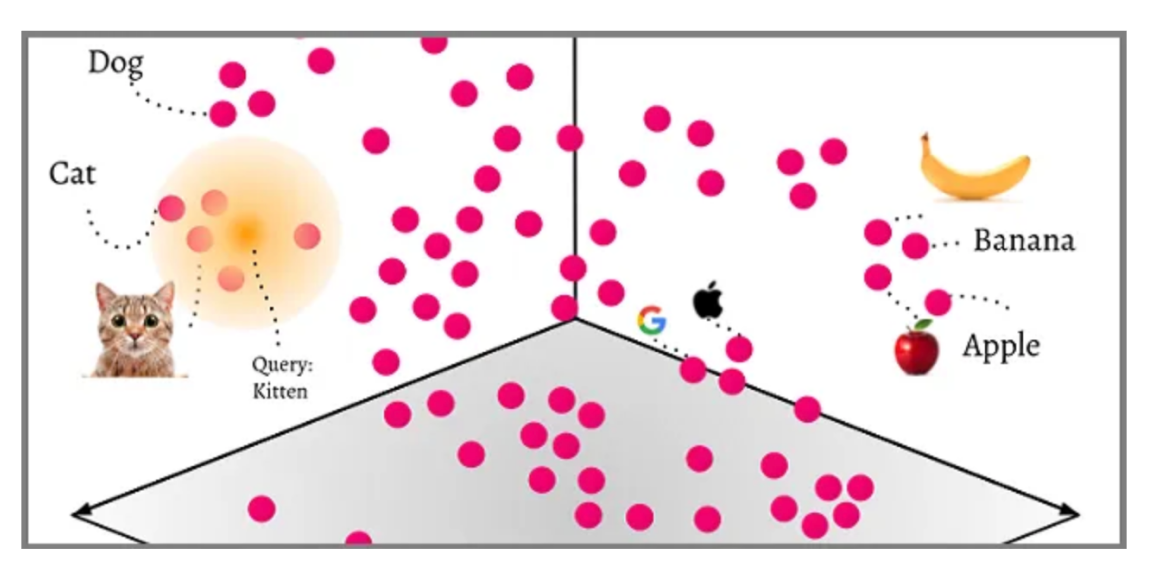
转换(将数据从一种格式转为另一种格式的过程)将矢量置于多维矢量空间中。 这种空间排列的一个最显著特点是,具有相似属性或特征的数据点会自然地相互靠拢,形成数据集群。
矢量嵌入不仅仅是数值转换;它们封装了原始数据更深层的语义本质和上下文的细微差别。 这使得它们成为一系列人工智能应用的宝贵资产,如自然语言处理 (NLP)、情感分析、文本分类。
查询矢量数据库与查询传统数据库不同。 矢量数据库不是在相同矢量之间寻找精确匹配,而是使用相似性搜索来识别多维空间内与给定查询矢量非常接近的矢量。 这种方法不仅更符合数据的固有性质,而且具备传统搜索无法比拟的速度和效率。
单词、句子甚至整篇文档都可以转化为矢量,从而捕捉其精髓。例如,标准的单词嵌入方法是 Word2Vec。通过 Word2Vec,含义相近的单词可以用多维空间中相近的矢量来表示。 最著名的例子是:国王 – 男人 + 女人 = 王后。 将与单词“国王”和“女人”相关的矢量相加,同时减去“男人”,等于与“女王”相关的矢量。
即使有复杂的图案和颜色,图像也可以转换为矢量。 例如,在满是动物图像的数据集中,经过训练的卷积神经网络 (CNN) 会将所有狗图像加入一个集群,与猫或鸟的图像集群截然不同。
通过捕获固有的数据结构和数据中的模式,矢量嵌入提供了语义丰富的描述。这种丰富性不仅有助于更深入地理解数据,而且还加快了与确定关系和衡量不同实体之间相似性相关的计算。
为什么矢量搜索至关重要?
由于其独特的数据检索方法,矢量搜索对于矢量数据库至关重要。
与依赖精确匹配的传统数据库不同,在矢量数据库中,矢量搜索基于相似性进行操作。这种语义理解意味着即使两条数据不相同但在上下文或语义上相似,它们也可以匹配。
传统的关键字搜索在精确定位文档或表格中的特定词语时表现出色。然而,它们无法处理非结构化数据,例如视频、书籍、社交媒体帖子、PDF 和音频文件。
矢量搜索通过支持非结构化数据中的搜索来填补这一空白。它不仅寻找精确匹配,还根据语义相似性识别内容,了解搜索词之间的内在关系。
在处理高维数据时,矢量搜索的效率变得显而易见。矢量数据库擅长处理跨越数百甚至数千个维度的数据点。 针对高维矢量的矢量搜索进行优化的算法,例如近似最近邻 (ANN) 搜索,可以快速识别这个广阔空间中最相似的矢量,而无需扫描每个矢量。 这种效率意味着搜索速度更快、资源利用率更高。
从用户体验的角度来看,矢量搜索的好处是多方面的。推荐系统或图像识别等应用可以根据相似性而不是精确匹配来提供结果。 例如,在电子商务环境中,显示与用户的搜索查询类似的产品可以提高客户满意度并增加销售额。 随着数据集的扩展,矢量搜索的可扩展性变得显而易见。 精确匹配搜索可能会随着数据的增长而逐渐变慢,但矢量搜索始终保持一致的查询性能,即使在处理大量数据集的情况下也能确保及时获得结果。
矢量搜索的灵活性是另一个显著的优势。 它只需最少的调整即可适应新的数据类型、不断发展的数据结构和不断变化的搜索要求。
此外,在快速发展的数据管理领域,灵活性是非常宝贵的,特别是当今许多人工智能和机器学习模型,尤其是那些植根于深度学习的模型,都以矢量形式生成数据。对于面部识别或语音识别等高级应用来说,能够原生搜索矢量数据的数据库变得不可或缺。
矢量数据库的使用案例
全球经济格局复杂且竞争激烈,而数据仍然是其核心。过去,许多人将数据称为“新石油”。在生成式人工智能时代,矢量嵌入就像石油一样,矢量数据库已经成为复杂的炼油厂,擅长处理高维数据和执行相似性搜索。
对于高管来说,生成式人工智能不仅仅是一个流行语,更是一项战略。对于开发者来说,矢量数据库的主要吸引力在于效率。传统数据库可能需要复杂的查询结构才能获取相关数据,尤其是在处理庞大的数据集时。矢量数据库简化了这一过程,允许开发者根据相似性检索数据,从而降低了代码的复杂性和数据检索所需的时间。
矢量数据库使用案例示范
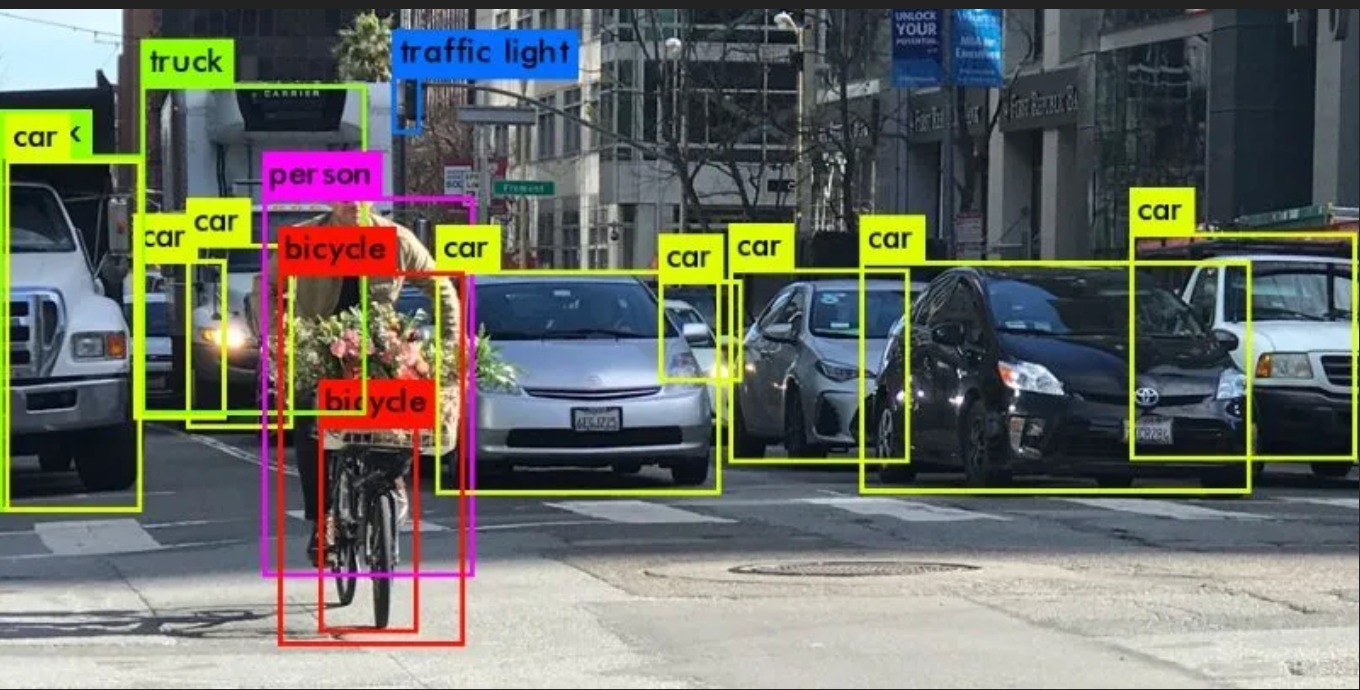
图像和视频识别:视觉内容主导着我们的视觉文化,矢量数据库在其中大放异彩。它们擅长筛选大量图像和视频存储库,以找出与给定输入惊人相似的图像和视频。这不仅仅是逐个像素的匹配;而是要了解潜在的模式和特征。这些功能对于面部识别、物体检测,甚至媒体平台中的版权侵权检测等应用至关重要。
自然语言处理和文本搜索:同义词、转述和上下文会使精确的文本匹配成为一项艰巨的任务。然而,矢量数据库可以辨别短语或句子的语义本质,使它们能够识别措辞可能不相同但上下文相似的匹配。这种能力改变了聊天机器人的游戏规则,确保它们正确响应用户的查询。同样,搜索引擎可以提供更相关的结果,增强用户体验。
推荐系统:矢量数据库在个性化中发挥着关键作用。通过了解用户偏好和分析模式,这些数据库可以向用户推荐符合其口味的歌曲或符合其偏好的产品。这一切都是为了衡量相似性并提供引起用户共鸣的内容或产品。
新兴应用:矢量数据库的应用范围不断扩大。在医疗保健领域,它们通过分析分子结构的潜在治疗特性来帮助药物研发。在金融领域,矢量数据库协助异常检测,发现可能表明欺诈活动的异常模式。
随着生成式人工智能的兴起,矢量数据库成为重要的推动者,帮助开发者将复杂的人工智能蓝图转变为实用的、价值驱动的工具。
MongoDB Atlas Vector Search:颠覆者
MongoDB Atlas Vector Search 是 MongoDB 的最新成员。它使客户能够在任何类型的数据上构建由语义搜索和生成式人工智能提供支持的智能应用程序。访问 Atlas Vector Search 快速入门指南,几分钟内即可创建您的第一个索引。
一直以来,为图像或高效相似性搜索等任务寻求矢量数据库的开发团队都面临着两难选择:是选择一个附加的矢量数据库,为技术堆栈增加另一个工具;还是混合使用搜索工具和开源解决方案。 使用全文搜索来获取语义功能,通常意味着开发者会陷入大量同义词映射的困境。 局限性很明显:如果用户的查询不准确,那么结果就很不相关。
这些挑战意味着:
- 增加一个监督的系统。
- 需要专门的技能。
- 不断更新同义词映射的精神压力。
- 对于不精确的查询,用户体验不佳。
- 从核心任务中挪用宝贵的工程时间。
Atlas Vector Search 简化了通过语义搜索和生成式人工智能丰富的应用程序设计,能够处理从视频到社交媒体内容的一系列数据类型。 利用 MongoDB Atlas 的稳健性,矢量搜索允许开发者在具有统一查询界面的可信平台上制作基于相关性的尖端搜索工具。
矢量搜索为 MongoDB Atlas 提供了理解查询所需的知识,而无需定义同义词。 即使用户不知道他们在寻找什么,矢量搜索也能够根据查询的含义返回相关结果。 例如,搜索“冰淇淋”将返回“圣代”,即使用户不知道圣代存在。
使用矢量搜索时,您会将矢量嵌入与原始数据和元数据一起存储在 Atlas 中。 这可确保对矢量数据的任何更新或添加都能立即同步,从而简化架构并提供统一的开发人员体验。
通过矢量搜索,您将使用最强大的矢量搜索算法之一来索引和查询数据:近似 k 最近邻(或“k-NN”,它使用分层可导航小世界或 HNSW 图来查找矢量相似性) 。
您可以创建大为改进的搜索体验,解决传统搜索工具无法解决的使用案例,包括:
- 语义搜索:这允许进行上下文驱动搜索。例如,即使没有任何预设同义词,搜索“冰淇淋”也可能会产生“圣代”这样的结果。
- 增强推荐:如果用户搜索割草机,系统还可能推荐相关的草坪护理产品。
- 多样化的媒体搜索:无论是寻找与“幸福家庭”等词语产生共鸣的图像,还是筛选音频日志中的特定短语,矢量搜索都可以胜任这项任务。
- 混合搜索:它结合了矢量搜索和传统全文搜索的优势,丰富了搜索结果。
- 大型语言模型的长期存储器:这为大型语言模型提供了专有的业务数据背景,提高了其输出的准确性。
Atlas Vector Search 与 LlamaIndex 和 LangChain 等流行的应用程序框架兼容。 它还与 Google Vertex AI、AWS、Azure 和 Databricks 等生态系统合作伙伴无缝集成,确保专有业务数据提高人工智能驱动的应用程序的性能和准确性。
Atlas Vector Search:用于由语义搜索支持的智能应用程序
矢量数据库以其独特的数据存储和检索方法正在改变我们对数据库的看法。它们执行快速相似性搜索的能力使它们在当今数据驱动的世界中不可或缺。当与 MongoDB Atlas 的强大功能和灵活性相结合时,它们提供了无与伦比的解决方案。
Atlas Vector Search 为高级使用案例(如语义搜索、图像搜索和相似性搜索)提供支持,而传统的 Atlas 全文搜索无法解决这些问题。开发者可以将矢量嵌入存储在 MongoDB 中,用机器学习模型补充现有的搜索功能,并查询它们以获得相关的上下文结果。工程领导者受益于运行 Atlas 带来的安心:一个完全托管的现代多云数据库。
无论您是构建推荐系统、搜索引擎还是任何其他需要快速准确的数据匹配的应用程序,都可以考虑利用矢量数据库和 MongoDB 的综合能力。未来是矢量化的,MongoDB 可以帮助您驾驭未来。