那么,什么是转换器模型?
转换器模型是人工智能和自然语言处理领域的关键进步。它代表了一种深度学习模型,在各种语言相关任务中发挥了变革性作用。转换器旨在通过关注句子中单词之间的关系来理解和生成人类语言。
转换器模型的定义特征之一是它们利用了一种称为“自注意力机制”的技术。这项技术允许这些模型处理句子中的每个单词,同时考虑同一句子中其他单词提供的上下文。这种上下文意识与早期语言模型有很大不同,也是转换器成功的关键原因。
转换器模型已成为许多现代大型语言模型的支柱。通过使用转换器模型,开发者和研究人员能够创建更复杂、具有上下文感知能力的 AI 系统,以越来越像人类的方式与自然语言进行交互,最终显着改善用户体验和 AI 应用程序。
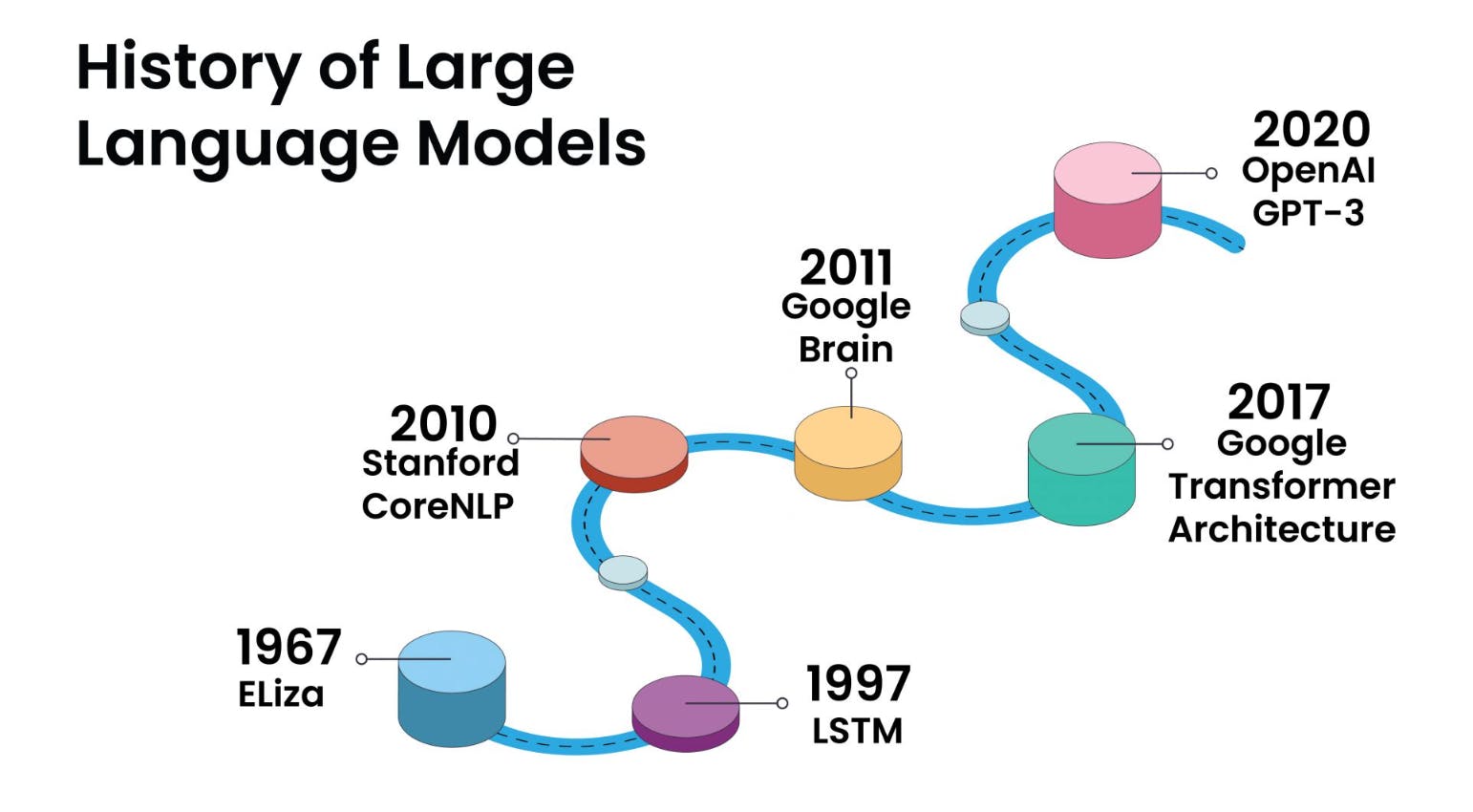
大型语言模型是如何工作的?
大型语言模型通过利用深度学习技术来处理和生成人类语言。
- 数据收集:培训 LLM 的第一步涉及从互联网上收集大量文本和代码数据集。此数据集包含广泛的人工编写内容,为 LLM 提供了多样化的语言基础。
- 预训练数据:在预训练阶段,LLM 会接触到这个庞大的数据集。他们学习预测句子中的下一个单词,这有助于他们理解单词和短语之间的统计关系。这个过程使他们能够掌握语法、句法,甚至理解一些上下文。
- 微调数据:经过预训练,LLM 针对特定任务进行微调。这涉及将它们暴露给与所需应用程序相关的较小数据集,例如翻译、情感分析或文本生成。微调可以提高他们有效执行这些任务的能力。
- 上下文理解:LLM 会考虑句子中给定单词前后的单词,从而生成连贯且与上下文相关的文本。这种情境感知使 LLM 与早期的语言模型区分开来。
- 任务适应:通过微调,LLM 可以适应各种任务。它们可以回答问题、生成类似人类的文本、翻译语言、总结文档等。这种适应性是 LLM 的主要优势之一。
- 部署:经过培训,LLM 可以部署在各种应用程序和系统中。它们为聊天机器人、内容生成引擎、搜索引擎和其他 AI 应用程序提供支持,从而提升用户体验。
总之,LLM 的工作原理是首先通过在海量数据集上进行预训练,学习人类语言的复杂性。然后,他们利用情境理解,针对具体任务对自己的能力进行微调。这种适应性使它们成为适用于各种自然语言处理应用程序的多功能工具。
此外,需要注意的是,为您的使用案例选择特定的 LLM、预训练模型、微调和其他自定义的过程,都是独立于 Atlas 进行的(因此,也在 Atlas Vector Search 之外进行)。
大型语言模型(LLM)和自然语言处理(NLP)有什么区别?
自然语言处理(NLP)是计算机科学中的一个领域,致力于促进计算机与人类语言(包括口语和书面交流)之间的交互。其范围包括赋予计算机理解、解释和处理人类语言的能力,涵盖机器翻译、语音识别、文本摘要和问答解答等应用程序。
另一方面,大型语言模型(LLM)作为 NLP 模型的一个特定类别出现。这些模型在庞大的文本和代码库中经过严格训练,能够辨别单词和短语之间错综复杂的统计关系。因此,LLM 表现出生成既连贯又与上下文相关的文本的能力。LLM 可用于各种任务,包括文本生成、翻译和问题解答。
实际应用中的大型语言模型示例
提升客户服务
想象一下,一家公司正在寻求提升其客户服务体验。他们利用大型语言模型的功能创建了一个聊天机器人,能够处理客户对其产品和服务的咨询。该聊天机器人使用由客户问题、相应答案和详细产品文档组成的大量数据集进行训练。该聊天机器人的与众不同之处在于它对客户意图的深刻理解,使其能够提供准确且信息丰富的响应。
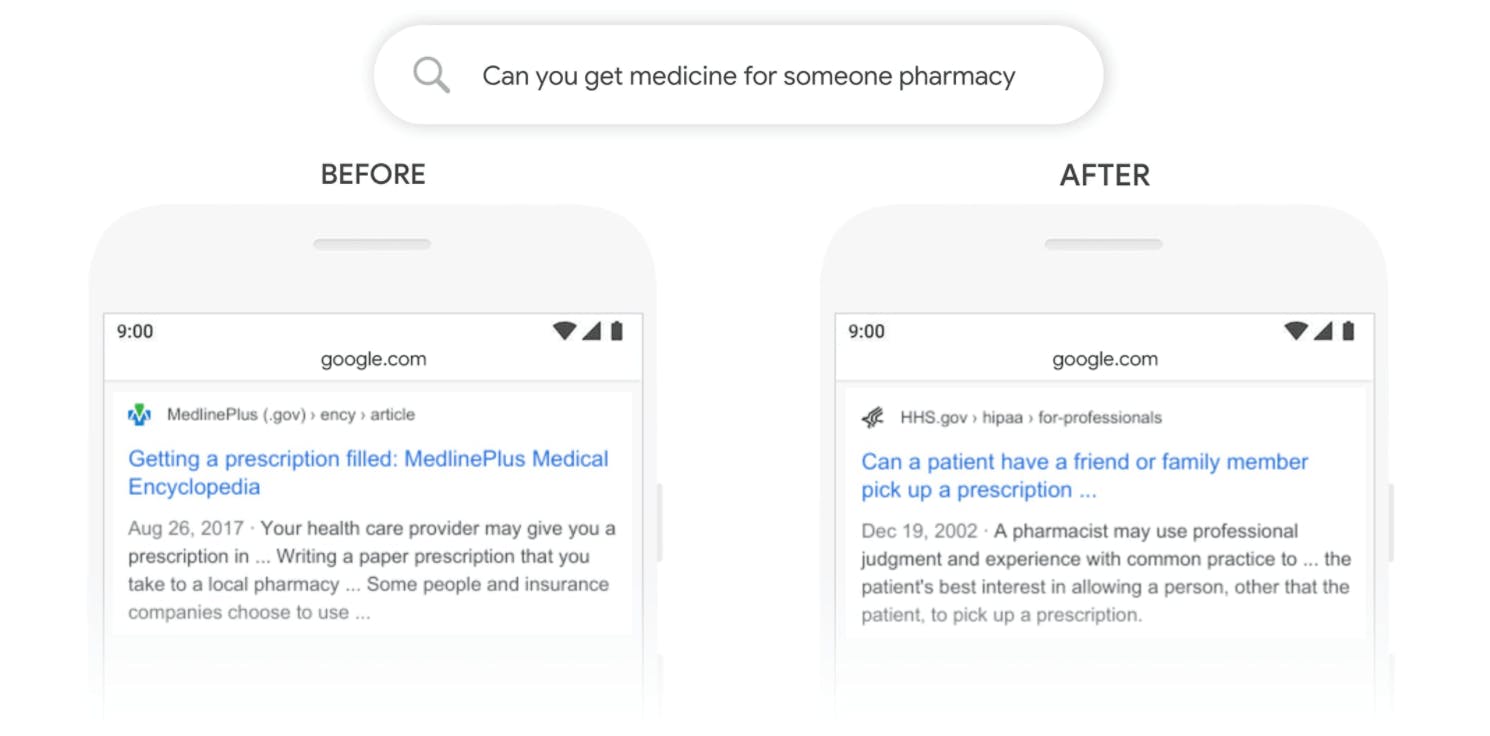
更智能的搜索引擎
搜索引擎是我们日常生活的一部分,LLM 为这些搜索引擎提供支持,使它们更加直观。即使您的措辞不够完美,这些模型也能理解您要搜索的内容,并从庞大的数据库中检索出最相关的结果,从而提升您的在线搜索体验。
个性化推荐
当您在网上购物或在流媒体平台上观看视频时,经常会看到对您可能喜欢的产品或内容的推荐。LLM 驱动这些智能推荐,分析您过去的行为,推荐符合您品味的内容,使您的在线体验更加量身定制和更加个性化。
创造性内容生成
LLM 不仅是数据处理器,他们还具有创造性思维。他们拥有深度学习算法,可以生成从博文到产品描述甚至诗歌的内容。这不仅能节省时间,还能帮助企业为受众制作引人入胜的内容。
通过整合 LLM,企业正在改进其客户互动、搜索功能、产品推荐和内容创建,最终改变技术格局。
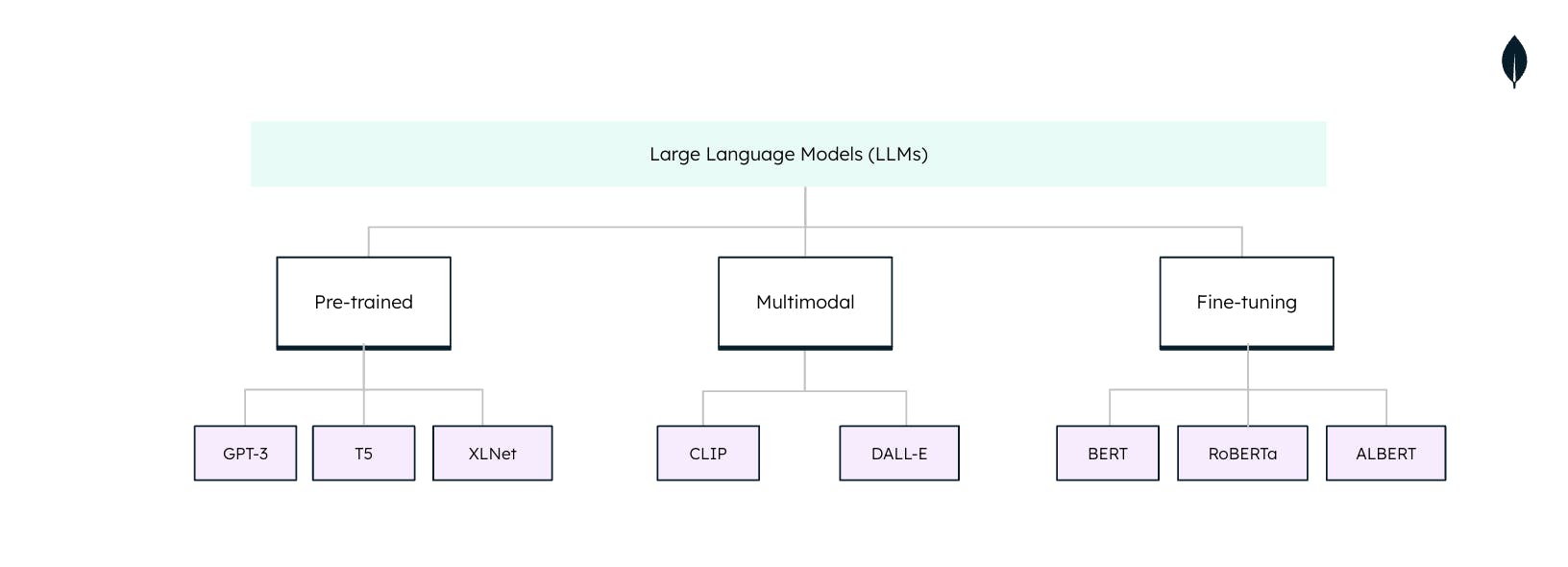
大语言模型的类型
大型语言模型(LLM)在自然语言处理(NLP)任务中使用时并不是万能的。每个 LLM 都是针对具体任务和应用程序量身定制的。了解这些类型对于充分利用 LLM 的潜力至关重要: