2023 年、生成 AI(Generative AI、略称:GenAI)の台頭により、世界は大きな変革の時代を迎えました。AI を活用した革新的なコンテンツ生成アプリケーションが次々と登場し、生成 AI がさまざまな業界や社会のあらゆる領域に劇的な影響を与えるという見方が広がっています。
現在、多くの組織は生成 AI の可能性を活用しようと競争を繰り広げています。このレースに参加するためには、まずは生成 AI の仕組みとその複雑さを理解する必要があります。本記事では、AI 活用の方向性を検討するうえで役立つ以下の主要な点について説明します。
これらの疑問を掘り下げたうえで、生成 AI を搭載したアプリケーションの構築をめざす組織に対し、MongoDB がどのように支援できるかについても紹介します。
まずは、基本的な概要から始めましょう。
生成 AI の基本的な仕組みとは?
生成 AI とは人工知能の 1 分野で、テキストや視覚芸術、音楽、ソフトウェアコードなど、新しい独自コンテンツの創出に重点を置いています。機械学習を用いて過去のデータを分析し、パターンや傾向を特定して予測を行う予測型(あるいは分析型)の AI とは異なり、生成 AI は単なる分析や予測の域を出て、新しいコンテンツを生み出します。
例えば、膨大な数の絵画とその画家のデータを基にトレーニングされた予測 AI ツールについて考えてみましょう。予測 AI ツールは、これまで見たことのない絵画を与えられると、その絵を描いた画家を特定できるかもしれません。他方で、生成 AI システムはその画家の画風に沿って新しい絵画を作り出すことができます。

生成 AI は、一般的に人間の知性と創造性を模倣するよう設計されており、これは、生成されたコンテンツが文脈的な関連性と一貫性を持っていることを意味します。斬新な生成コンテンツでも、人間の思考や表現のパターンに共鳴します。そのように生成された視覚要素や AI アートは、人間の作ったコンテンツとほとんど区別がつかないかもしれません。コンテンツは、テキストや音声の形式で出力されることもあります。いずれにせよ、生成 AI ツールによる出力は、親近感と独自性、革新性と本物らしさを兼ねそなえたものとなります。
推論を通じて文脈上関連性の高いコンテンツを生み出すことで、戦略計画や予測、課題解決、仮説分析などのビジネス業務で生成 AI 機能を応用することができます。
生成 AI モデルの種類
AI モデルとは、機械学習を用いてデータからパターンを特定する AI アルゴリズムのセットのことで、予測を行ったり、元データの構造やスタイルを模倣した新規データを生成したりできます。AI 界にはさまざまなタイプのモデルが数多く存在するなかで、現在、生成 AI で最もよく知られているのが基盤モデルです。
基盤モデルは膨大な量のデータを用いて事前にトレーニングされています。基盤モデルを「基盤」にして、特定のタスクに合わせた調整が可能です。そのため、基盤モデルは非常に汎用性が高く、多種多様なタスクに対応できます。基盤モデルの一例が大規模言語モデル(LLM)です。OpenAI 社の GPT(Generative Pre-trained Transfomrer の頭文字)は、人間の言語を用いて動作するよう設計された大規模言語モデルです。大規模言語モデルでは自然言語処理を中心として、質疑応答やチャットボット、文字起こし、翻訳などの対話型タスクを実行できます。
また、非テキストコンテンツに焦点を当てた基盤モデルもあります。Flamingo や OpenAI 社の DALL-Eのように画像を生成する視覚基盤モデルや、UniAudio や LLark などの音声基盤モデルがその例です。
検索拡張生成(RAG)とは
LLM は、最終トレーニング時点で入手可能な情報に制限されるため、それ以降に発生した出来事や進展についての情報をもちません。では、新しいデータを生かして大規模言語モデルを活用するにはどうすればいいのでしょうか。
1 つの選択肢として、生成モデルを新しいデータで再トレーニングまたはファインチューニングする方法があります。しかし、そのためには大量の時間とリソースが必要です。それよりも良い方法が検索拡張生成(RAG)です。RAG を用いると、LLM はコンテンツ生成処理中に外部の情報をリアルタイムでダイナミックに取得できます。RAG を通じて生成 AI システムが情報データベースをリアルタイムで検索するため、トレーニング時のデータに必要な知識が含まれていなくても、より正確で情報に富んだ、文脈上関連性の高い出力を生成できます。
RAG を用いて、大規模なデータコーパスから関連性の高い、意味的に類似した情報を効率的に取得するには、高次元空間でデータを数値で表現するベクトル埋め込みがなくてはなりません。ベクトル埋め込みの保存と検索には、ベクトルデータベースの使用が最適です。

RAG により能力を拡張した LLM は、さまざまな用途に応じて、最新情報に基づいた高品質なコンテンツを生成します。こちらの記事からの以下の引用は、RAG の機能をうまく要約しています。
RAG は LLM の未学習の知識ギャップを埋め、従来の質疑応答タスクを「資料参照可の試験」に変えます。参考資料を検索できるため、際限のないオープンな質疑応答タスクよりも簡単で複雑性が低くなります。
AI 界における生成 AI の重要性
新規コンテンツを生み出す生成 AI の役割が、AI に関連する全ての物事に変革の可能性をもたらします。生成 AI モデルはエンターテイメント業界からヘルスケア業界まであらゆる産業で応用可能です。AI 研究と AI 技術のイノベーションにより、生成 AI モデルの能力と応用範囲は絶えず広がっています。近い将来、生成 AI 機能はモダンな AI ツールキットの一部として必要不可欠になるでしょう。
生成 AI を用いた画像生成が、GPT と Stable Diffusion などの拡散モデルの組み合わせにより実現しました。その結果、AI アートが一大市場となり、アーティストは生成 AI を用いて自然画像とほとんど区別のつかないリアルな画像を作りだしています。
その他にも、マーケターがセールスイベントに関する 180 文字のツイートを生成 AI で作成したり、デザイナーが新たな製品デザイン作りに生成 AI を活用したりしています。製薬会社までもが、創薬過程で生成 AI を使用しています。

生成 AI におけるデータの役割
生成 AI システムを含めてすべての AI システムの有効性と汎用性は、モデルのトレーニングに用いられるデータの質と量、多様性に依存します。データと生成 AI モデルの関係について、重要な諸側面を見てみましょう。
トレーニング用のデータ
生成 AI モデルは膨大な量のデータセットに基づいてトレーニングされています。テキスト生成モデルのトレーニングには数十億もの記事が、画像生成モデルのトレーニングには数百万もの画像が用いられることもあります。大規模言語モデルが、一貫性があり文脈的に関連性の高いコンテンツを生成するには、膨大な量の機械学習トレーニングデータが必要です。データが多様かつ包括的であればあるほど、広範なコンテンツを理解して生成する能力が高まります。
一般的に、データ量が増えるほど出力が向上します。データセットが大きくなれば、生成 AI モデルはより微細なパターンも特定できるようになり、より正確で繊細な出力を実現できます。他方で、データの質も極めて重要です。多くの場合、小規模で高品質なデータセットのほうが、大規模で関連性の低いデータセットよりも優れた出力を生み出します。
複雑なローデータ
ローデータの中でも、複雑で構造化されていないデータは特に、トレーニングで使える状態にする前に、データパイプラインの初期段階で前処理が必要となることがあります。また、この段階でデータの妥当性を検証し、データの代表性と偏りがないかを確認します。この検証ステップは、歪な出力や偏った出力を避けるために必要不可欠です。
ラベル付きデータとラベルなしデータ
ラベル付きデータは、各データポイントに関する特定の情報(例えば、画像に付随する説明文)を提供するのに対し、ラベルなしデータはそのような注釈を含みません。生成 AI モデルは、内在する構造やパターンを理解することでコンテンツの生成方法を学習できるため、多くの場合、ラベルなしデータでもうまく機能します。
独自データ
データの中には、組織に固有のデータもあります。例えば、顧客の注文履歴や従業員の業績評価指標、業務プロセスなどがこれに当たります。多くの企業が独自データを収集すると、極秘の PII(個人識別用情報)や PHI(個人健康情報)が下流プロセスに漏洩しないよう匿名化したのち、従来のデータ分析を実施しています。これらのデータには、生成モデルのトレーニングに使用すればさらに深くマイニングできる情報が豊富に含まれています。その結果得られる出力は、企業特有のニーズや特性に即したものになるでしょう。
RAG におけるデータの役割
前述のとおり、RAG を用いると LLM の能力とリアルタイムのデータ検索を組み合わせられます。RAG があれば、学習済みのデータのみに頼る必要がありません。外部のデータベースから関連情報を必要なタイミングで必要なだけ引き出すことができます。その結果、最新かつ正確なコンテンツを生成できるようになります。
生成 AI モデルを独自データで拡張する方法
生成 AI モデルの使用に際して、より適した出力や応答をモデルから引き出せるように特定の入力クエリや指示を工夫する手法がプロンプトエンジニアリングです。RAG を用いると独自データでプロンプトを拡張できるため、AI モデルを強化して企業データを生かした正確で関連性の高い応答を生成できます。独自データを RAG で用いるアプローチは、独自データで LLM を再トレーニングまたはファインチューニングするアプローチよりも大幅に時間とリソースを削減でき、望ましい方法でもあります。
課題と留意点
生成 AI の活用には当然ながら課題もあります。生成 AI の可能性を有効活用するには、次の主な課題を考慮する必要があります。
データに関する専門知識と膨大な演算能力の必要性
生成モデルには膨大なリソースが必要です。第一に、専門のデータサイエンティストとエンジニアが必要です。データ関連の組織を除いて、大半の企業には LLM のトレーニングやファインチューニングに必要な専門的なスキルセットをもつチームがいません。
また、コンピューティングのリソースについて、包括的なデータを基にモデルをトレーニングするには数週間、あるいは数ヶ月を要することがあります。これは、強力な GPU や TPU を使用しても同じです。また、LLM のファインチューニングについても、ゼロからのトレーニングと同じくらい高い演算能力は必要ないかもしれません。しかし、膨大なリソースを要することに変わりありません。
LLM のトレーニングとファインチューニングに多大なリソースが必要であることを考えると、事前トレーニング済み LLM の既存データに、最新(かつ独自)のデータを組み込むことのできる RAG は魅力的な代替手法となります。
倫理的な留意点
生成 AI の台頭により、生成 AI の開発と活用に関する倫理面について活発な議論が巻き起こっています。生成 AI アプリケーションが一般的になり、多くの人々が利用するようになるにつれ、以下をどのように実現するかが議論されています。
- 公平かつ偏りのないモデルの確保
- モデル汚染やモデル改ざんなどの攻撃からの保護
- 誤情報の拡散防止
- 生成 AI の悪用防止(ディープフェイクや誤解を招く情報の生成など)
- 帰属の保護
- エンドユーザーに対する透明性の向上(人間ではなく生成 AI のチャットボットとやりとりしていることをユーザー自身が認識できるようにする)
他の AI ツールや AI システムとの比較
生成 AI ツールに関する誇張された宣伝文句や目新しさにより、他の AI ツールや AI システムの全般的な状況が覆い隠されています。生成 AI こそあらゆる問題を解決する唯一の AI ツールだと誤解する人も少なくありません。しかし、生成 AI が新しいコンテンツの作成に秀でている一方で、特定の業務タスクには他の AI ツールのほうが適している場合もあります。生成 AI の利点は、他のツールを評価するときと同様に、生成 AI 以外のツールの利点と比較して評価する必要があります。
RAG 特有の課題
RAG を用いて大規模言語モデルを強化するアプローチは強力である一方、特有の課題もあります。
- ベクトルデータベースと検索技術の選択:結局のところ、RAG アプローチの効率性は関連データを迅速に検索する能力次第です。ベクトルデータベースと検索技術の選択がRAG の性能に影響を及ぼすため、慎重な判断が必要です。
- データの一貫性:RAG はリアルタイムでデータを取得するため、ベクトルデータベースを常に最新に保ち、一貫性を確保することが重要です。
- 統合の複雑さ:RAG を LLM に統合することで、システムが複雑になります。RAG を用いて生成 AI を効果的に活用するには、専門知識が必要になることもあります。
以上のような課題があるものの、RAG は組織が業務データとアプリケーションデータを活用するための簡単かつ強力な手段です。RAG を用いることで、豊富なインサイトを収集し、ビジネスの重大な意思決定のための情報を得られます。
MongoDB Atlas を生成 AI 搭載アプリに活用
本記事では、生成 AI の変革的な可能性に触れ、RAG を用いたリアルタイムデータによる強力な拡張について説明してきました。両技術を統合するには、生成 AI 搭載アプリケーション向けの機能をまとめて提供する、柔軟なデータプラットフォームが必要です。生成 AI と RAG の世界へ踏み出す組織にとって、MongoDB Atlas はゲームチェンジャーとなるでしょう。
MongoDB Atlas の主な機能は次のとおりです。
- ネイティブなベクトル検索機能:ベクトルストレージと検索機能がネイティブに組み込まれた MongoDB Atlas では、ベクトル処理用のデータベースを追加する必要がないため、RAG のデータ検索を迅速かつ効率的に行えます。
- 統合 API と柔軟なドキュメントモデル:MongoDB Atlas が提供する統合 API により、開発者はベクトル検索を、構造化検索やテキスト検索など他のクエリ機能と組み合わせられます。さらに MongoDB のドキュメントデータモデルとの組み合わせにより、高い柔軟性を実現します。
- 拡張性・信頼性・安全性:MongoDB Atlas の提供する水平スケーリングにより、お客さま(とお客さまのデータ)に合わせて容易に拡張できます。耐障害性とシンプルな水平・垂直スケーリングにより、MongoDb Atlas がワークロードの増減に関わらず中断のないサービスを保証します。また、MongoDB が安全性を重視していることは、クエリ可能なデータ暗号化の実現によって業界をリードしていることからも明らかです。
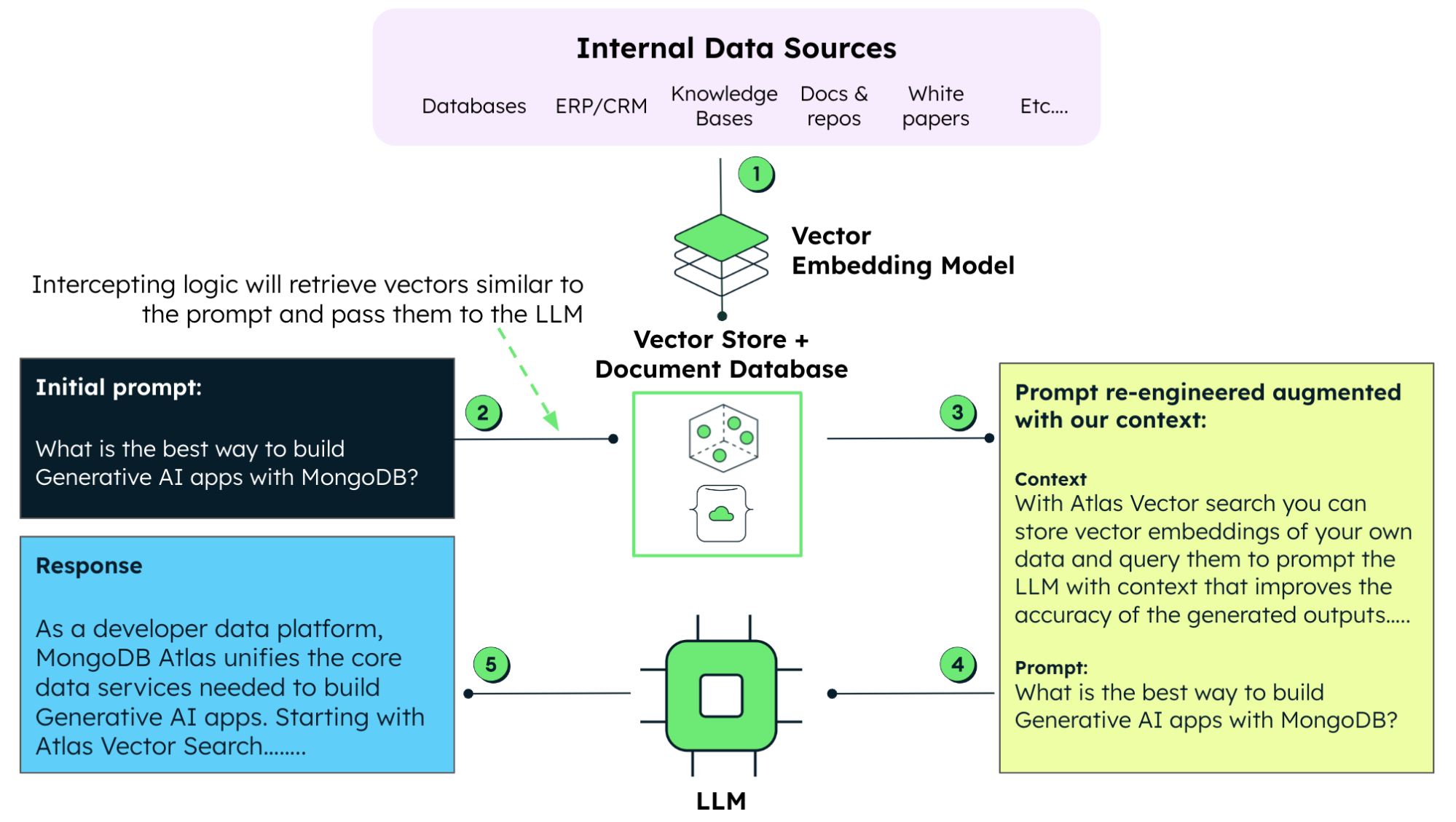
MongoDB Atlas は RAG で拡張した LLM システムの導入を簡素化するうえで、重要な役割を果たします。お客さまの既存の生成 AI データサービスをうまく処理することで、MongoDB がエンタープライズ向けの生成 AI 搭載アプリの構築プロセスを合理化します。取り込みたいデータが独自データであれ、最新のイベントデータであれ、MongoDB が RAG アプローチを実現します。1,500 人が回答した AI に関する最近の調査では、MongoDB Atlas Vector Search が、全てのベクトルソリューションの中で開発者満足度 No.1 を獲得しました。
結論
人工知能の 1 つである生成 AI は、膨大な量の既存コンテンツを基にトレーニングしたモデルを用いて、新たな独自コンテンツを生み出します。生成 AI の誕生は、現代テクノロジーの革新的な飛躍を表しています。他方で、生成 AI に人間の知性と創造性を確実に模倣させるには、大量の高品質なデータでトレーニングを行う必要があります。生成 AI モデルの効果はトレーニングデータの質と量、そして多様性に依存します。
LLM が利用できるデータは、その LLM の最終トレーニング時点のデータに限られます。最新データの取り込みは、モデルの再トレーニングやファインチューニングでは実現できません。というのも、再トレーニングやファインチューニングのプロセスが完了するときには、データが既に古くなっているからです。それを解決するのが RAG を用いたアプローチで、プロンプトエンジニアリングのタスクの一環として、ベクトルデータベースから最新のデータを参照する方法です。RAG は、最新の関連する情報(組織の独自情報も含む)にアクセスする能力を LLM に追加して補強します。膨大なリソースを必要とするトレーニングやファインチューニングは必要ありません。
RAG アプローチを実現するうえで MongoDB Atlas が注目を集めています。ネイティブなベクトル検索機能と統一の API、柔軟なドキュメントモデルの組み合わせは、RAG アプローチで LLM を強化して独自データを活用したい企業にとって魅力的な選択肢となります。