La Retrieval-augmented generation (RAG) è un framework di generative AI molto popolare che potenzia le capacità dei modelli linguistici di grandi dimensioni (LLM) incorporando informazioni pertinenti e aggiornate durante il processo di generazione. Questo approccio consente agli LLM di integrare le proprie conoscenze pre-addestrate con dati aggiornati e relativi a domini specifici. La RAG è una soluzione conveniente per personalizzare un LLM per casi d'uso specifici, senza il costoso e lungo processo di fine-tuning o riqualificazione dell'intero modello.
RAG per un'AI più intelligente
La RAG consente alle organizzazioni di utilizzare i modelli linguistici di grandi dimensioni di uso generale per applicazioni specializzate senza la necessità di modelli costosi e personalizzati. La RAG affronta direttamente le limitazioni fondamentali di questi modelli, arricchendo le query con informazioni aggiornate e specifiche per migliorare le capacità di generazione. Questo consente alle organizzazioni di integrare informazioni in tempo reale, set di dati proprietari e documenti specializzati che non sono inclusi nell'addestramento del modello originale. Fornendo prove in modo trasparente con le risposte, la RAG migliora la fiducia e riduce il rischio di allucinazioni.
Cosa sono gli LLM?
Gli LLM sono una forma di intelligenza artificiale progettata per comprendere e generare testo che imita il linguaggio umano. In quanto applicazione avanzata del Natural Language Processing (NLP), gli LLM possono apprendere schemi, strutture e grammatica da enormi quantità di dati di addestramento, che consentono loro di generare risposte coerenti alle richieste degli utenti. Il punto di forza degli LLM risiede nella loro capacità di eseguire un'ampia gamma di compiti di generazione di linguaggio senza la necessità di un addestramento specifico per i singoli compiti. Questo li rende strumenti versatili per applicazioni come chatbot, traduzioni, creazione di contenuti e sintesi.
Le limitazioni degli LLM
Un LLM è una rete neurale complessa che apprende dall'analisi di enormi set di dati di addestramento. Questi modelli richiedono ingenti risorse computazionali e richiedono uno processo di sviluppo molto lungo e costoso. Inoltre, l'infrastruttura specializzata necessaria per l'hosting e la manutenzione di LLM personalizzati crea barriere finanziarie significative, limitandone l'accessibilità solo alle organizzazioni dotate di risorse adeguate e con notevoli investimenti tecnologici.
Gli LLM sono molto abili nel rispondere alle domande su contenuti storici, ma la loro conoscenza è limitata dai dati su cui sono stati addestrati. Questo li rende meno efficaci per le query che richiedono conoscenze aggiornate, perché non possono rispondere a domande su eventi recenti senza un nuovo addestramento del modello.
Allo stesso modo, gli LLM non possono rispondere in modo nativo a domande sulla documentazione interna di un'azienda o su altri set di dati specifici di un dominio relativi a una particolare organizzazione. Questa limitazione pone sfide significative per le aziende che desiderano sfruttare le tecnologie AI, che richiedono conoscenze approfondite e specializzate specifiche per le loro esigenze.
Queste limitazioni evidenziano un'altra sfida degli LLM: le allucinazioni. Senza informazioni verificabili, i modelli linguistici possono generare risposte che appaiono sicure e plausibili ma sono del tutto inventate. Questa tendenza a produrre informazioni convincenti ma false crea rischi significativi per le applicazioni che richiedono precisione e affidabilità.

Vantaggi della RAG
La RAG è diventata popolare grazie alla sua architettura relativamente semplice unita a significativi miglioramenti delle prestazioni.
Convenienza
La RAG consente alle organizzazioni di utilizzare modelli pre-addestrati generici per applicazioni specializzate senza dover affrontare i costi di sviluppo di modelli addestrati personalizzati. Un recupero efficace delle informazioni riduce i costi delle API, garantendo che siano incluse solo le informazioni necessarie per ottimizzare gli LLM che applicano tariffe in base al numero di token.
Personalizzazione del dominio
La RAG consente alle organizzazioni di personalizzare i modelli pre-addestrati per domini specifici integrando librerie di conoscenze specializzate. Questo consente ai modelli di generare risposte su documenti proprietari e relativi a settori specifici senza la necessità di un addestramento personalizzato del modello. Il fine-tuning può offrire vantaggi simili, ma richiede tempo, costi e interventi di manutenzione molto maggiori.
Insight in tempo reale
La RAG consente agli LLM di accedere e generare risposte utilizzando informazioni aggiornate recuperando dinamicamente dati recenti da fonti esterne. In questo modo si superano i limiti di conoscenza dei set di dati di addestramento statici, consentendo ai modelli di fornire informazioni su eventi recenti e tendenze emergenti.
Trasparenza
La RAG migliora l'affidabilità delle risposte dell’AI fornendo citazioni delle fonti e prove per i contenuti generati. Collegando ogni risposta a fonti specifiche nella knowledge base, la RAG consente agli utenti di verificare l'origine e l'accuratezza delle informazioni, riducendo il rischio di allucinazioni e rafforzando la fiducia nei risultati generati dall'AI.
Adattabilità
Uno dei principali vantaggi della RAG è la sua capacità di adattarsi facilmente ai nuovi modelli all'avanguardia. Man mano che emergono progressi nei modelli linguistici o nelle tecniche di recupero, le organizzazioni possono integrare modelli più recenti o modificare le strategie di recupero senza dover rivedere l'intero sistema. Questa flessibilità garantisce che un sistema RAG possa rimanere aggiornato con le tecnologie più avanzate.
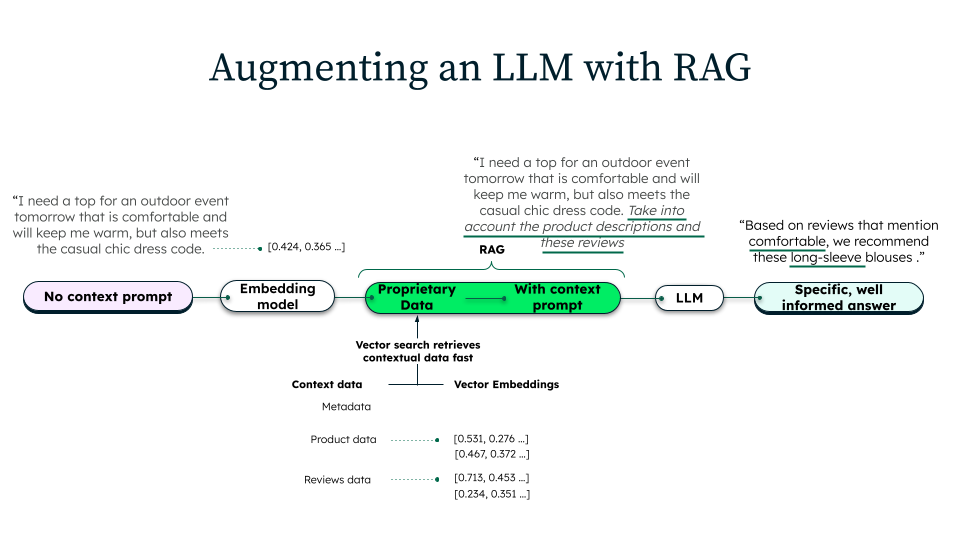
Come funziona la RAG?
La RAG è composta da tre fasi distinte: acquisizione, recupero e generazione.
Acquisizione dei dati
Durante la fase di acquisizione dei dati, le organizzazioni preparano la propria knowledge base per il recupero. I dati di origine vengono raccolti da vari repository, come documentazione interna, database o risorse esterne. Questi documenti vengono quindi ripuliti, formattati e suddivisi in parti più piccole e gestibili. Ogni chunk viene convertito in una rappresentazione vettoriale utilizzando un modello di incorporamento, che cattura il significato semantico del testo. Questi vettori sono memorizzati in database vettoriali che consentono una ricerca semantica e un recupero efficaci.
Recupero delle informazioni
Quando un utente invia una query, il sistema recupera il contesto pertinente prima della generazione. La query viene trasformata in una rappresentazione vettoriale utilizzando lo stesso modello di incorporamento usato durante l'acquisizione. La ricerca vettoriale cercherà nel database i chunk di documenti più semanticamente simili alla query. È possibile applicare tecniche aggiuntive di filtraggio, classificazione o riassegnazione dei pesi per garantire che vengano recuperate solo le informazioni più rilevanti, migliorando l'accuratezza della risposta finale.
Generazione
Una volta recuperato il contesto pertinente, viene costruito un prompt aumentato utilizzando il prompt originale, gli stessi passaggi recuperati e istruzioni specifiche. L'LLM elabora questo prompt per generare una risposta che sintetizzi le sue conoscenze pre-addestrate con i contenuti recuperati. Questo approccio assicura che la risposta sia basata su fonti di dati esterne e allineata con l'intento dell'utente, generando una risposta più precisa.
Casi d'uso della RAG in diversi settori
La RAG è già utilizzata in vari settori per sbloccare il potenziale trasformativo dell'AI e degli LLM.
- Produzione: arricchisci gli LLM con i manuali delle apparecchiature e i registri di manutenzione per fornire indicazioni operative in tempo reale. La RAG consente ai tecnici di accedere rapidamente a informazioni precise sui macchinari, riducendo i tempi di inattività e migliorando le prestazioni delle apparecchiature.
- Assistenza clienti: utilizza la documentazione interna, le guide ai prodotti e la cronologia dell'assistenza per diagnosticare i problemi. La RAG aiuta i team di supporto a recuperare istantaneamente contenuti utili, riducendo i tempi di risposta e migliorando i tassi di risoluzione al primo contatto per rispondere in modo efficiente alle domande dei clienti.
- Sanità: sintetizza ricerche mediche, linee guida cliniche e cartelle cliniche per supportare le decisioni diagnostiche e le raccomandazioni terapeutiche. La RAG consente ai professionisti del settore sanitario di accedere alle conoscenze mediche attuali fornendo al contempo insight trasparenti e basati su prove.
- Servizi finanziari: integra documenti normativi, report di mercato e linee guida di conformità per supportare la ricerca sugli investimenti, la valutazione del rischio e la conformità normativa. La RAG consente agli analisti finanziari di recuperare e analizzare rapidamente informazioni finanziarie complesse e aggiornate.
- Ingegneria del software: esamina documenti e frammenti di codice per assistere gli ingegneri durante la scrittura di codice. La RAG può anche assistere nel debug suggerendo potenziali soluzioni basate su problemi simili del passato, migliorando la produttività e la qualità.
Concetti chiave della RAG
Chunking
Il chunking è una parte del processo di acquisizione dei dati che migliora l'accuratezza del sistema riducendo i costi. Consiste nel suddividere grandi porzioni di contenuto in segmenti più piccoli e gestibili per prepararli al recupero. L'obiettivo è creare dei chunk significativi e completamente contestualizzati, assicurandosi che contengano informazioni sufficienti per essere utili, riducendo al minimo la ridondanza.
Un processo di chunking efficace bilancia la granularità e la completezza, consentendo al sistema di recuperare informazioni pertinenti senza sovraccaricare l'LLM con dettagli non necessari. Dei chunk ben strutturati migliorano la precisione del recupero, riducono l'uso dei token e portano a risposte più accurate e convenienti.
Modelli di incorporamento
I modelli di incorporamento convertono i dati in rappresentazioni numeriche chiamate vettori che rappresentano il loro significato semantico. Ciò consente al sistema di comprendere le relazioni tra parole, frasi e documenti, migliorando l'accuratezza nel recupero delle informazioni pertinenti.
Durante l'acquisizione, il modello di incorporamento elabora ogni chunk di dati, trasformandolo in un vettore prima di memorizzarlo in un database vettoriale. Quando un utente invia una query, questa viene convertita in un vettore utilizzando lo stesso modello di incorporamento.
Diversi tipi di modelli di incorporamento supportano vari casi d'uso. I modelli di uso generale funzionano bene per applicazioni ampie, mentre i modelli specifici sono personalizzati per settori come quello legale, medico o finanziario, migliorando l'accuratezza del recupero in ambiti specializzati. I modelli multimodali vanno oltre l'elaborazione del testo e gestiscono immagini, audio e altri tipi di dati, consentendo capacità di recupero più avanzate. Alcuni modelli possono creare una rappresentazione numerica del testo che può essere confrontata direttamente con un'immagine o un video per un recupero multimodale davvero avanzato.
Ricerca semantica
La ricerca semantica migliora il recupero delle informazioni concentrandosi sul significato dietro la query di un utente, migliorando notevolmente la ricerca per parole chiave. Utilizzando gli incorporamenti, sia le query che i documenti vengono convertiti in vettori che rappresentano il loro significato semantico. Quando un utente invia una query, il database vettoriale ricerca i documenti più pertinenti, anche se i termini esatti della query non sono direttamente presenti nel contenuto.
Questo approccio consente una migliore comprensione del contesto, garantendo risultati più accurati e pertinenti. Riconoscendo sinonimi, concetti correlati e varianti di parole, la ricerca semantica migliora l'esperienza dell'utente e riduce l'ambiguità, fornendo risultati che corrispondono meglio all'intento dell'utente.
Reranking
Il reranking è una tecnica utilizzata per migliorare la pertinenza dei risultati di ricerca dopo una fase iniziale di recupero. Una volta recuperato un insieme di documenti, un modello di reranking li riordina in base alla loro pertinenza alla query dell'utente. Questo modello può sfruttare caratteristiche aggiuntive, come la qualità dei documenti, la rilevanza contestuale la valutazione basata su machine learning per affinare i risultati.
Il reranking aiuta a dare priorità alle informazioni più utili e contestualmente appropriate, migliorando l'accuratezza e la soddisfazione degli utenti. È particolarmente utile quando la fase iniziale di recupero restituisce un'ampia gamma di risultati, consentendo al sistema di ottimizzare la selezione e presentare le risposte più pertinenti.
Ingegneria del prompt
Il prompt engineering implica la creazione accurata dell'input fornito a un LLM per guidarne l'output nella direzione desiderata. Strutturando i prompt in modo efficace, si può garantire che il modello generi risposte più accurate, pertinenti e appropriate. Questo processo prevede l'inclusione di istruzioni chiare, contesto pertinente e talvolta esempi per aiutare il modello a comprendere il compito.
Nella RAG, il prompt engineering svolge un ruolo chiave nel combinare i documenti recuperati con la query originale dell'utente per produrre risposte coerenti e precise. Dei prompt ben progettati riducono l'ambiguità, minimizzano le informazioni irrilevanti e garantiscono che il modello sia allineato con l'intento dell'utente, portando a risultati di qualità superiore.
Ottimizzazione dell'applicazione della RAG
Le soluzioni RAG possono essere ottimizzate per fornire una maggiore accuratezza e un'esperienza complessiva migliorata per gli utenti finali.
Ottimizzazione del recupero delle informazioni
Il recupero delle informazioni per la RAG può essere migliorato attraverso diverse strategie. In primo luogo, è possibile rivedere le tecniche di chunking per garantire che i documenti siano suddivisi in segmenti significativi e contestualmente rilevanti. Successivamente, è necessario scegliere il modello di incorporamento corretto per catturare il significato semantico dei propri contenuti. I modelli specifici per dominio possono offrire risultati migliori per determinati casi d'uso. Sebbene la ricerca semantica sia quella più comunemente utilizzata, occorre valutare se la ricerca per parole chiave o un approccio ibrido possano migliorare il recupero.
Inoltre, è opportuno applicare i metodi di reranking dopo il recupero iniziale per perfezionare l'accuratezza dei risultati. È anche fondamentale regolare il numero di documenti recuperati: un numero eccessivo può introdurre rumore, mentre uno insufficiente potrebbe far perdere informazioni contestuali cruciali. Trovare il giusto equilibrio aiuta a migliorare le prestazioni di recupero e la pertinenza.
Ottimizzazione della generazione di risposte
Per migliorare la generazione di linguaggio nella RAG è possibile adottare diversi approcci chiave. Innanzitutto, è necessario concentrarsi sulla progettazione dei prompt per strutturare le query e il contesto in modo da guidare il modello linguistico a generare risposte più accurate e pertinenti. Istruzioni chiare, contesto ed esempi aiutano a ridurre l'ambiguità e a migliorare la qualità dell'output. Successivamente, è necessario valutare diversi modelli o LLM specifici per garantire che le risposte generate siano in linea con le sfumature del proprio caso d'uso specifico, migliorando la pertinenza e l'accuratezza. Inoltre, per controllare la creatività delle risposte del modello, si dovrebbero prendere in considerazione i parametri regolabili del modello, come la temperatura.
Ottimizzazione per la produzione su larga scala
Assicurati che il tuo sistema RAG sia pronto per la produzione scegliendo i migliori fornitori per i componenti chiave delle tue applicazioni.
Per il tuo database vettoriale, opta per una piattaforma che offra funzionalità di ricerca e indicizzazione altamente efficienti, in particolare una che supporti la ricerca Approximate Nearest Neighbor (ANN) veloce e scalabile. I database vettoriali avanzati possono anche supportare il filtraggio dei metadati, il che può migliorare la precisione e la velocità restringendo i risultati della ricerca in base a informazioni contestuali aggiuntive. Ciò consentirà al sistema di recuperare rapidamente i documenti pertinenti, anche man mano che il set di dati cresce.
Quando si sceglie un modello di incorporamento, è importante bilanciare l'alta dimensionalità dei vettori con un'archiviazione e un recupero efficienti. Sebbene gli incorporamenti ad alta dimensionalità catturino relazioni semantiche più ricche, comportano un aumento dei costi computazionali, dei requisiti di archiviazione e tempi di recupero più lenti.
Inoltre, quando si seleziona un LLM per la componente di generazione, è necessario assicurarsi che sia in linea con le esigenze specifiche del proprio caso d'uso. Gli LLM dovrebbero essere in grado di interpretare accuratamente le informazioni recuperate e generare risposte coerenti e contestualmente pertinenti. La scelta dell'LLM influisce anche sui costi e sulle prestazioni complessive del sistema: i modelli più grandi possono offrire una maggiore precisione, ma a scapito di una maggiore latenza e di maggiori esigenze di calcolo. È fondamentale valutare i tempi di risposta, la qualità dell'output e i requisiti infrastrutturali per selezionare un LLM che trovi il giusto equilibrio tra prestazioni ed efficienza.
Sfide della RAG
Una delle sfide principali della RAG è la difficoltà di centralizzare e organizzare i contenuti per un recupero efficace. I sistemi RAG richiedono l'accesso a grandi quantità di dati in diversi domini, ma organizzare questi contenuti in modo che il modello possa recuperare in modo efficiente le informazioni più pertinenti e aggiornate è un compito complesso. I dati possono essere distribuiti su diverse piattaforme, formati e database, rendendo difficile garantire una copertura completa e un'accuratezza precisa. Inoltre, è fondamentale garantire la coerenza tra più fonti. Le informazioni recuperate possono essere contraddittorie, obsolete o incomplete, il che può confondere la knowledge base e compromettere la qualità e l'affidabilità delle risposte generate. Queste sfide evidenziano la necessità di sistemi di indicizzazione e recupero più sofisticati per consentire ai modelli RAG di ottenere i migliori contenuti possibili e generare output pertinenti e accurati.
Un'altra sfida significativa è l'attuale limite della RAG nel rispondere alle domande piuttosto che svolgere compiti più complessi. Sebbene i sistemi RAG siano molto abili nel generare risposte basate sulle informazioni recuperate, faticano a eseguire azioni che vanno oltre il rispondere alle domande o il generare contenuti. Questo vincolo si presenta perché la RAG è progettata principalmente per raccogliere dati pertinenti da fonti esterne e fornire output basati su tali dati, piuttosto che interagire o manipolare ambienti del mondo reale. Di conseguenza, mentre i modelli RAG possono assistere nel recupero delle informazioni e nella generazione di contenuti, la loro capacità di eseguire compiti come la risoluzione di problemi o il processo decisionale rimane poco sviluppata, limitando il loro potenziale per applicazioni più dinamiche.
Creazione di una RAG interattiva con memoria migliorata
Potenziare la RAG con la memoria consente i espandere la sua capacità di creare un'esperienza più interattiva ricordando i dettagli chiave e il contesto delle interazioni passate. I sistemi RAG tradizionali solitamente rispondono alle query senza conservare le informazioni tra più scambi, il che comporta un'esperienza frammentata. Integrando meccanismi di memoria, i sistemi RAG possono memorizzare fatti rilevanti, preferenze o intuizioni provenienti da conversazioni attuali e precedenti, con la possibilità di richiamare queste informazioni quando necessario. Questo consente al sistema di offrire risposte più personalizzate, contestualizzate e di creare un'esperienza più fluida. Nel tempo, il sistema sviluppa una comprensione più approfondita delle esigenze dell'utente, adattando le sue risposte per renderle più pertinenti e coinvolgenti, rendendo l'esperienza una conversazione continua piuttosto che una serie di query isolate.
Il futuro della RAG e della generative AI
In futuro continueranno a emergere nuove tecniche all'interno della RAG, che miglioreranno la sua capacità di recuperare e generare informazioni in modo più efficiente, adattivo e intelligente. Un'area chiave di crescita è lo sviluppo di meccanismi di recupero avanzati, che consentono ai sistemi RAG di accedere in modo dinamico a una gamma più ampia di fonti, tra cui database specializzati, contenuti non strutturati e informazioni in tempo reale. Questi miglioramenti renderanno i sistemi RAG più consapevoli del contesto, consentendo loro di generare output altamente pertinenti e accurati in vari domini.
Allo stesso tempo, l'integrazione di agenti di generative AI consentirà ai sistemi di AI di svolgere compiti di risoluzione dei problemi, analisi dei dati e presa di decisioni. Questi sistemi basati su agenti non solo recupereranno e genereranno risposte, ma intraprenderanno anche azioni in base alle informazioni raccolte, diventando così più interattivi, autosufficienti e intelligenti. Di conseguenza, la RAG diventerà centrale per applicazioni come la ricerca automatizzata, le raccomandazioni personalizzate e gli assistenti virtuali interattivi, inaugurando una nuova era di AI reattiva e proattiva.
Fine-tuning e RAG a confronto
Il fine-tuning è un processo in cui un modello linguistico viene modificato attraverso un addestramento aggiuntivo su nuovi contenuti, insegnando essenzialmente al modello nuove conoscenze o comportamenti che vengono incorporati in modo permanente nella sua memoria parametrica. Questo approccio richiede risorse computazionali e competenze significative, ha una capacità limitata per le nuove informazioni a causa dei vincoli delle dimensioni del modello, e qualsiasi modifica apportata è permanente e non può essere facilmente aggiornata. Un modello ottimizzato può fornire risultati specifici per un dominio, ma richiede tempi di addestramento e investimenti significativi, rendendo difficile mantenerlo aggiornato.
La RAG recupera dinamicamente contenuti non inclusi nei dati di addestramento prima che avvenga la generazione del linguaggio. Ciò consente ai modelli RAG di incorporare nuovi dati senza modificare i parametri sottostanti del modello, rendendoli più flessibili e scalabili, evitando la necessità di attività complesse e dispendiose come il fine-tuning.
Crea applicazioni RAG con MongoDB Atlas e Voyage AI
MongoDB Atlas è un solido database generico che supporta vettori e ricerca vettoriale, il che lo rende la scelta ideale per sviluppare applicazioni RAG di livello produttivo.
Voyage AI fornisce potenti modelli di incorporamento e reranker per consentire un recupero delle informazioni altamente accurato.
Porta i tuoi progetti a un livello superiore: semplifica il processo di sviluppo e sblocca nuovo valore beneficiando di un'integrazione perfetta con i principali partner AI, i principali provider di cloud, i fornitori di modelli LLM e gli integratori di sistemi.
Risorse
Esplora MongoDB Atlas, il database vettoriale con funzionalità di ricerca integrate, capacità vettoriali e altro ancora. Registrati gratuitamente ora.
Per saperne di più su Voyage AI, visita questo blog.
Ottieni consigli strategici e supporto all’implementazione per la ricerca e il resto dello stack AI, visita il nostro MongoDB AI Applications Program per maggiori dettagli.