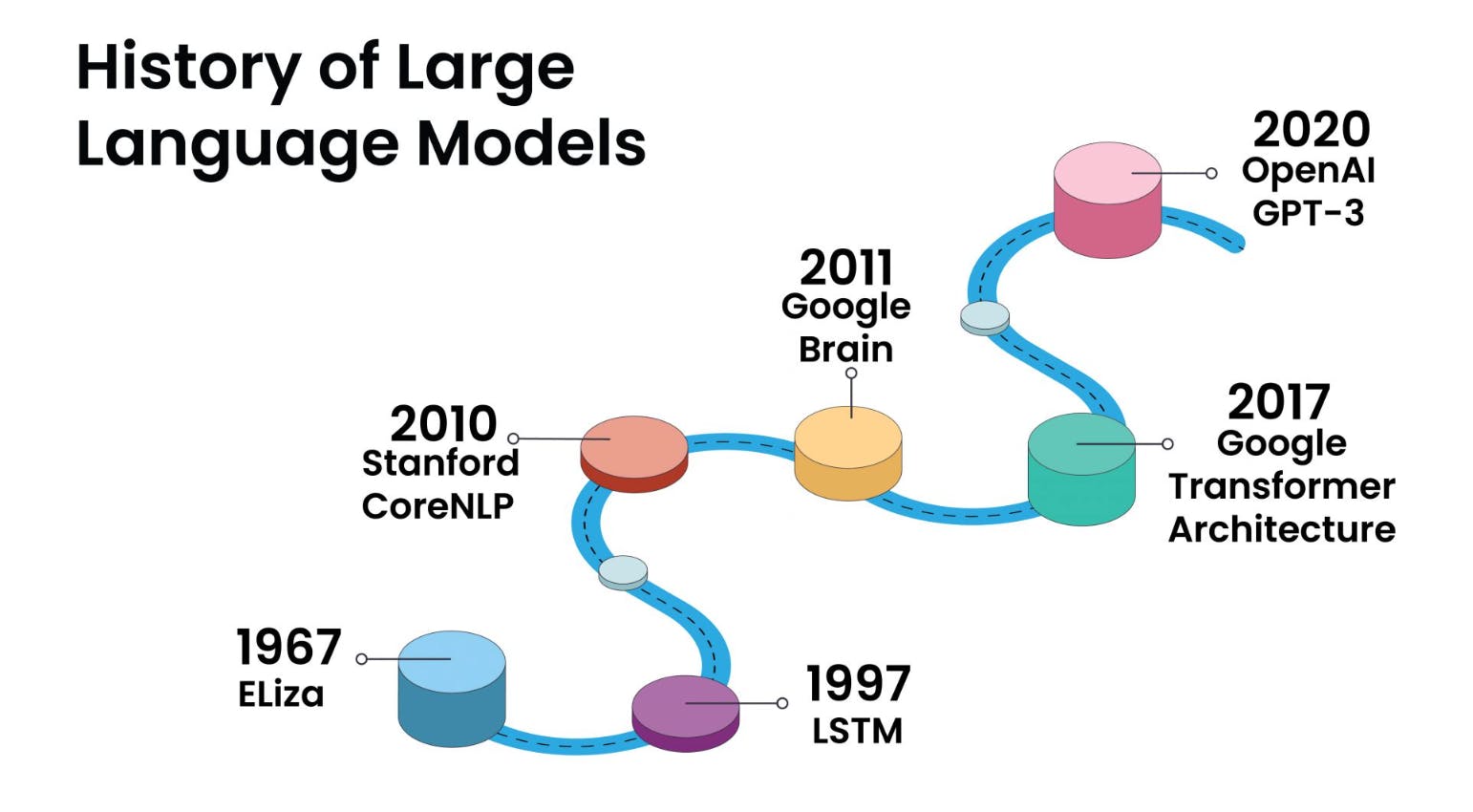
Um modelo de transformação é um avanço fundamental no mundo da IA e do processamento de linguagem natural. Ele representa um tipo de modelo de aprendizado profundo que desempenhou um papel transformador em várias tarefas relacionadas à linguagem. Os transformadores são projetados para entender e gerar a linguagem humana, concentrando-se nos relacionamentos entre palavras dentro de frases.
Uma das características peculiares dos modelos de transformadores é a utilização de uma técnica chamada "self-attention", a qual permite que os modelos processem cada palavra em uma frase enquanto consideram o contexto fornecido por outras palavras na mesma frase. Essa consciência contextual é um afastamento significativo dos modelos de linguagem anteriores e é uma das principais razões para o sucesso dos transformadores.
Os modelos de transformação se tornaram a espinha dorsal de muitos grandes modelos de linguagem modernos. Ao empregar modelos de transformação, desenvolvedores e pesquisadores criaram sistemas de IA mais sofisticados e contextualmente conscientes que interagem com a linguagem natural de modo cada vez mais próximo ao dos humanos, levando a melhorias significativas nas experiências do usuário e nos aplicativos de IA.
Como funcionam os grandes modelos de linguagem?
Os grandes modelos de linguagem funcionam com técnicas de aprendizado profundo para processar e gerar a linguagem humana.
- Coleta de dados: a primeira etapa no treinamento de LLMs envolve a coleta de um enorme conjunto de dados de texto e código da Internet. Esse conjunto de dados abrange uma ampla variedade de conteúdo escrito por humanos, fornecendo aos LLMs uma base linguística diversificada.
- Dados de pré-treinamento: durante a fase de pré-treinamento, os LLMs são expostos a esse vasto conjunto de dados. Eles aprendem a prever a próxima palavra em uma frase, o que os ajuda a entender as relações estatísticas entre palavras e frases. Esse processo permite que eles entendam a gramática, a sintaxe e até mesmo um pouco de compreensão contextual.
- Ajuste de dados: após o pré-treinamento, os LLMs são ajustados para tarefas específicas. Isso envolve expô-los a um conjunto de dados mais restrito relacionado ao aplicativo desejado, como tradução, análise de sentimentos ou geração de texto. O ajuste fino refina sua capacidade de realizar essas tarefas com eficiência.
- Compreensão contextual: os LLMs consideram as palavras antes e depois de uma determinada palavra em uma frase, permitindo que gerem um texto coerente e contextualmente relevante. Essa consciência contextual é o que diferencia os LLMs dos modelos de linguagem anteriores.
- Adaptação de tarefa: graças ao ajuste fino, os LLMs podem se adaptar a uma ampla variedade de tarefas. Eles podem responder a perguntas, gerar textos semelhantes aos redigidos humanos, traduzir idiomas, resumir documentos e muito mais. Essa adaptabilidade é um dos pontos fortes dos LLMs.
- Implantação: uma vez treinados, os LLMs podem ser implantados em vários aplicativos e sistemas. Eles potencializam chatbots, mecanismos de geração de conteúdo, motores de busca e outros aplicativos de IA, aprimorando as experiências do usuário.
Em resumo, os LLMs trabalham aprendendo primeiro as complexidades da linguagem humana por meio de pré-treinamento em grandes conjuntos de dados. Em seguida, eles ajustam suas habilidades para tarefas específicas, aproveitando a compreensão contextual. Essa adaptabilidade os torna ferramentas versáteis para uma ampla variedade de aplicativos de processamento de linguagem natural.
Além disso, é importante observar que a seleção de um LLM específico para seu caso de uso – tal como os processos de pré-treinamento do modelo, ajuste fino e outras personalizações – acontecem independentemente do Atlas (e, portanto, fora do Atlas Vector Search).
Qual é a diferença entre um grande modelo de linguagem (LLM) e o processamento de linguagem natural (PNL)?
O processamento de linguagem natural (PNL) é um domínio da ciência da computação dedicado a facilitar as interações entre computadores e linguagens humanas, abrangendo a comunicação falada e escrita. Seu escopo abrange capacitar os computadores a entender, interpretar e manipular a linguagem humana para atender a diversos objetivos, como tradução automática, reconhecimento de fala, resumo de texto e respostas a perguntas.
Por outro lado, os grandes modelos de linguagem (LLMs) emergem como uma categoria específica de modelos de PNL. Esses modelos passam por um treinamento rigoroso em vastos repositórios de texto e código, permitindo que detectem relações estatísticas detalhadas entre palavras e frases. Consequentemente, os LLMs exibem a capacidade de gerar texto coerente e contextualmente relevante. Os LLMs podem ser usados para uma variedade de tarefas, incluindo geração de texto, tradução e resposta a perguntas.
Exemplos de grandes modelos de linguagem em aplicações do mundo real
Atendimento ao cliente aprimorado
Imagine que uma empresa está interessada em elevar sua experiência de atendimento ao cliente. Ela usa os recursos de um grande modelo de linguagem para criar um chatbot capaz de responder às dúvidas dos clientes sobre seus produtos e serviços. Esse chatbot passa por um processo de treinamento usando extensos conjuntos de dados que consistem em perguntas de clientes, respostas correspondentes e documentação detalhada do produto. O diferencial desse chatbot é seu profundo entendimento da intenção do cliente, pois isso permite que ele forneça respostas precisas e informativas.
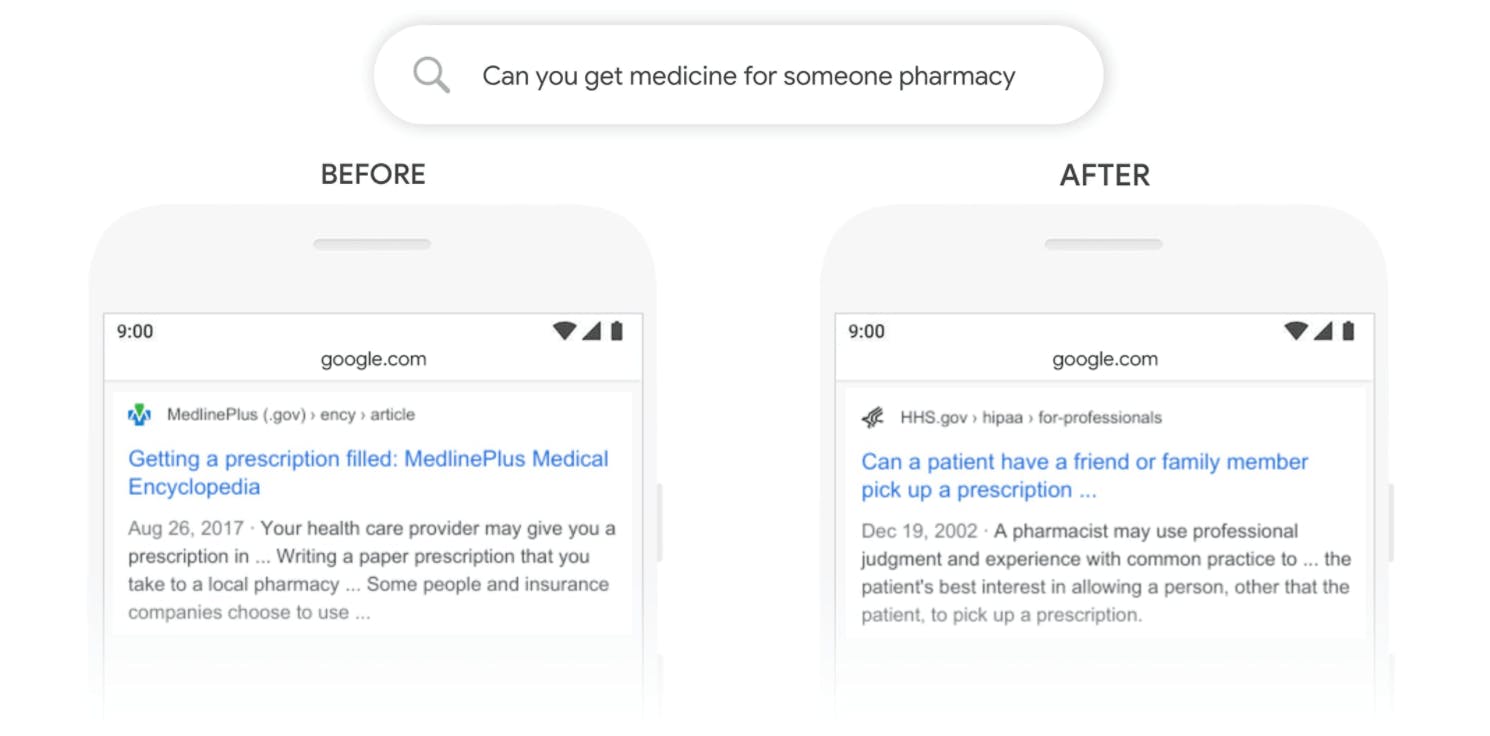
Motores de pesquisa mais inteligentes
Os motores de pesquisa fazem parte do nosso cotidiano, e os LLMs os tornam ainda mais intuitivos. Esses modelos entendem o que o usuário está procurando, mesmo que a redação da frase não tenha sido ideal, e recupera os resultados mais relevantes de vastos bancos de dados, aprimorando sua experiência de pesquisa online.
Recomendações personalizadas
Ao fazer compras online ou assistir a vídeos em plataformas de streaming, é normal que apareçam recomendações de produtos ou conteúdos que possam ser do nosso interesse. Os LLMs orientam essas recomendações inteligentes, analisando seu comportamento anterior para sugerir coisas que correspondam aos seus gostos, tornando as experiências online mais personalizadas para você.
Geração de conteúdo criativo
além de serem processadores de dados, os LLMs são mentes criativas. Eles têm algoritmos de aprendizado profundo que podem gerar conteúdo de postagens em blogs, descrições de produtos e até poesia. Isso economiza tempo e ajuda as empresas a criar conteúdo envolvente para seu público.
Ao incorporar os LLMs, as empresas melhoram as interações com os clientes, a funcionalidade de pesquisa, as recomendações de produtos e a criação de conteúdo, transformando, em última análise, o cenário tecnológico.
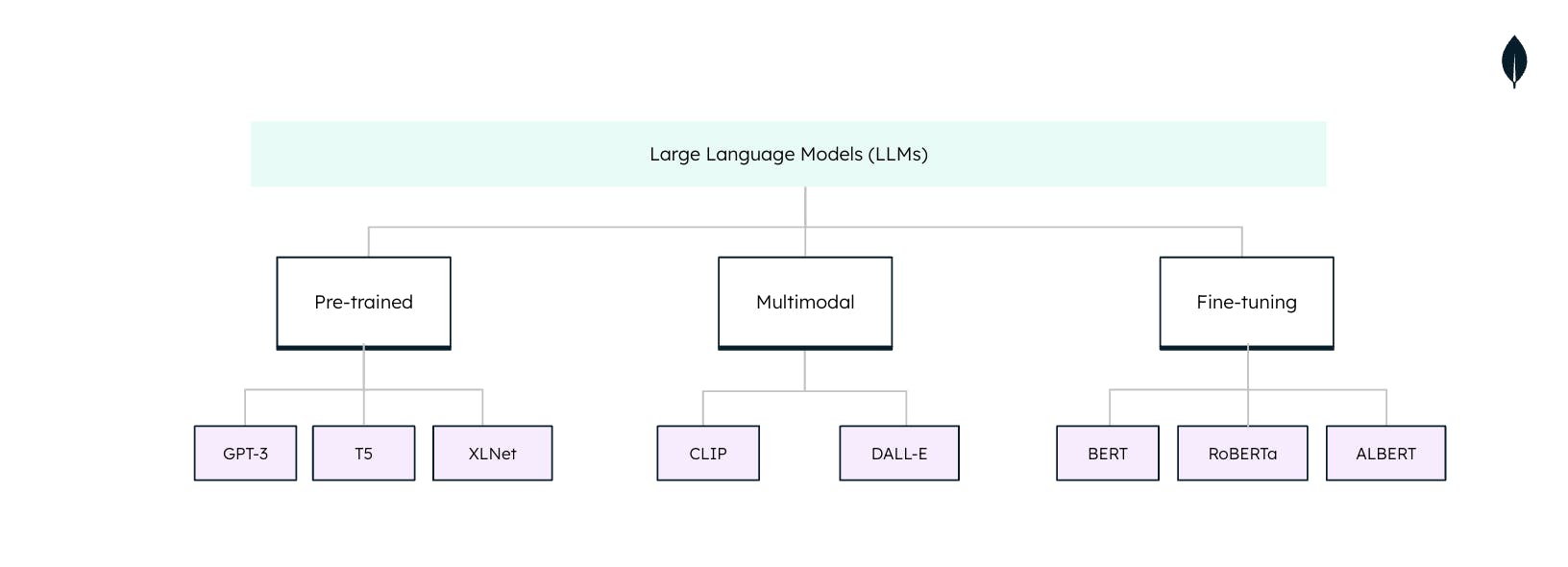
Tipos de grandes modelos de linguagem
Os grandes modelos de linguagem (LLMs) não são soluções genéricas quando usados em tarefas de processamento de linguagem natural (PLN). Cada LLM é adaptado para tarefas e aplicações específicas. Compreender esses tipos é essencial para extrair todo o potencial dos LLMs: