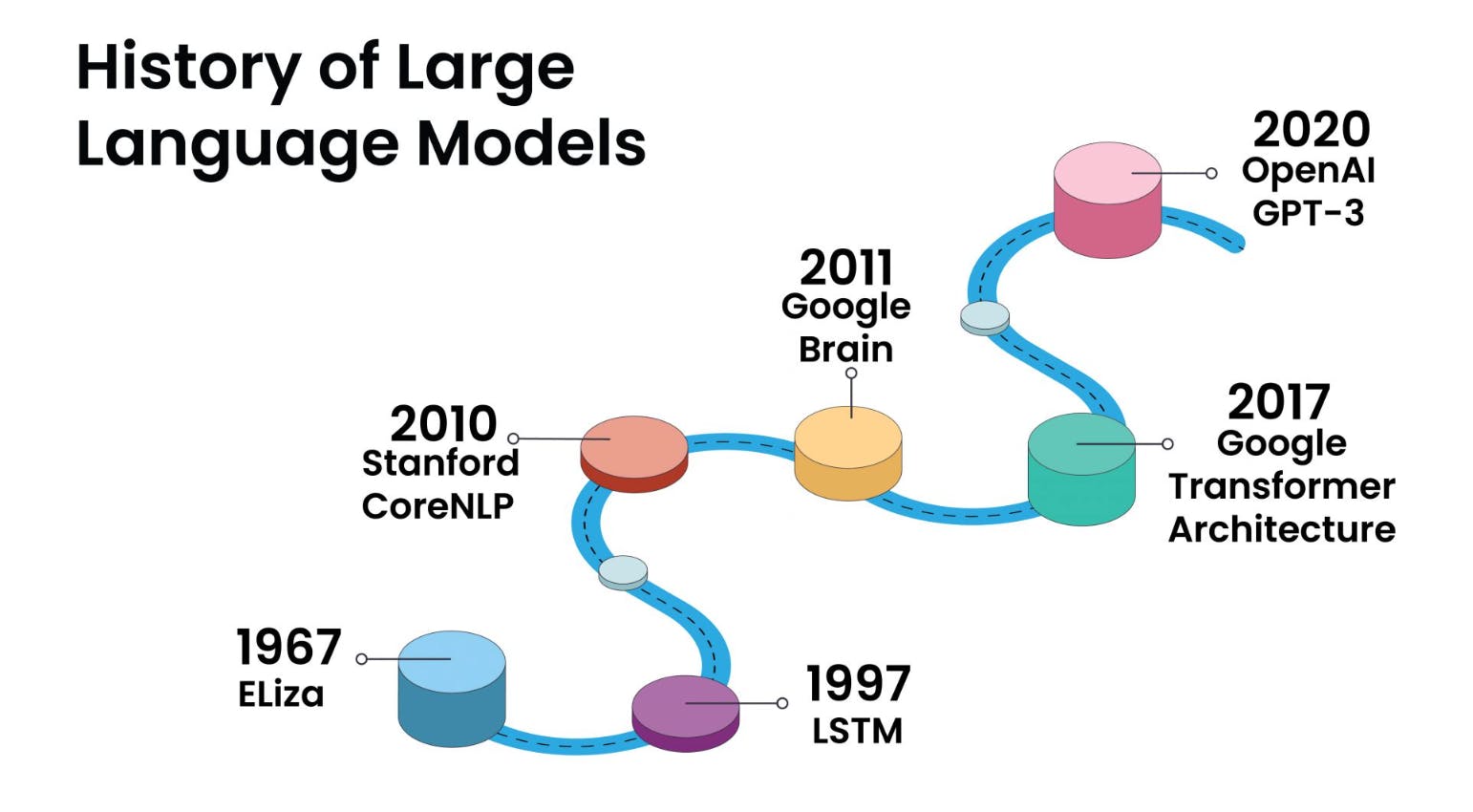
Ces modèles marquent une étape charnière dans le secteur de l’intelligence artificielle et du traitement du langage naturel. Ils désignent un modèle d’apprentissage profond qui a considérablement transformé diverses tâches liées au langage. Ils sont conçus pour comprendre et générer le langage humain en se concentrant sur les relations entre les mots dans les phrases.
L’une de leurs principales caractéristiques est l'utilisation d’une technique appelée « auto-attention ». Cette technique leur permet de traiter chaque mot d'une phrase en tenant compte du contexte fourni par les autres mots de la même phrase. Cette innovation constitue une rupture significative par rapport aux précédents modèles et explique en grande partie leur succès.
La plupart des grands modèles de langage modernes reposent sur eux. En les utilisant, les développeurs et les chercheurs ont pu créer des systèmes d'IA plus élaborés qui tiennent davantage compte du contexte et qui interagissent avec le langage naturel de manière de plus en plus humaine. L'expérience utilisateur et les applications d'IA se sont ainsi considérablement améliorées.
Les grands modèles de langage utilisent des techniques d'apprentissage profond pour traiter et générer le langage humain.
- Collecte de données : la première étape de l'entraînement des LLM consiste à collecter un ensemble massif de données de texte et de code sur Internet. Cet ensemble de données comprend un large éventail de contenus écrits par des humains, afin de leur fournir une base linguistique diversifiée.
- Données de pré-entraînement : pendant cette phase, les LLM sont exposés à ce vaste ensemble de données. Ils apprennent à prédire le mot suivant dans une phrase, ce qui les aide à comprendre les relations statistiques entre les mots et les expressions. Ce processus leur permet d'appréhender la grammaire, la syntaxe et même de comprendre en partie le contexte.
- Affinage des données : après le pré-entraînement les LLM sont affinés à des fins spécifiques. Cela implique de les exposer à un ensemble de données plus restreint lié à la tâche à réaliser, telle que la traduction, l'analyse de l'opinion ou la génération de texte. Cette mise au point affine leur capacité à effectuer ces tâches efficacement.
- Compréhension contextuelle : les LLM prennent en compte les mots qui précèdent et suivent un mot donné dans une phrase. Ils peuvent ainsi générer un texte cohérent et pertinent sur le plan contextuel. Cette caractéristique les distingue des modèles de langage antérieurs.
- Adaptation des tâches : grâce à l'affinage, les LLM peuvent s'adapter à un large éventail de tâches. Ils peuvent répondre à des questions, générer du texte semblable à celui rédigé par un humain, traduire, résumer des documents, etc. Cette capacité d'adaptation est l'un de leurs principaux atouts.
- Déploiement : une fois entraînés, ils peuvent être exploités dans diverses applications et systèmes. Ils alimentent les chatbots, les moteurs de génération de contenu, les moteurs de recherche et d' autres applications d' IA. L'expérience utilisateur est ainsi optimisée.
En résumé, ils fonctionnent en apprenant d'abord les subtilités du langage humain grâce à un pré-entraînement sur des ensembles de données massifs. Ils affinent ensuite leurs capacités à des fins spécifiques, en s'appuyant sur la compréhension du contexte. Ils peuvent ainsi être utilisés dans de nombreux domaines du traitement du langage naturel.
En outre, il convient de noter que la sélection d'un LLM adapté à vos besoins, ainsi que les processus de pré-entraînement du modèle, d'affinage et d'autres adaptations, se produisent indépendamment d'Atlas (et donc, en dehors d'Atlas Vector Search.).
Quelle est la différence entre un grand modèle de langage (LLM) et le traitement du langage naturel (TAL) ?
Le traitement du langage naturel (TAL) est un domaine de l'informatique qui vise à faciliter les interactions entre les ordinateurs et le langage humain, qu'il s'agisse de la communication orale ou écrite. Il s'agit de donner aux ordinateurs la capacité de comprendre, d'interpréter et de manipuler le langage humain (traduction automatique, reconnaissance vocale, synthèse de texte et réponse à des questions, par exemple).
D’autre part, les LLM constituent une catégorie spécifique de modèles TAL. Ils sont soumis à un entraînement rigoureux sur de vastes référentiels de texte et de code. Ils parviennent ainsi à discerner des relations statistiques complexes entre les mots et les expressions. Par conséquent, les LLM ont la capacité de générer des textes à la fois cohérents et pertinents sur le plan contextuel. Ils peuvent être utilisés pour diverses tâches, notamment la génération de texte, la traduction et la réponse aux questions.
Exemples de grands modèles de langage dans des applications du monde réel
Amélioration du service client
Imaginez une entreprise qui cherche à améliorer son service client. Elle exploite les capacités d'un grand modèle de langage pour créer un chatbot capable de répondre aux demandes des clients concernant leurs produits et services. Ce chatbot est soumis à un processus d'entraînement utilisant de vastes ensembles de données constitués de questions des clients, de réponses correspondantes et d'une documentation détaillée sur les produits. Ce qui distingue ce chatbot, c'est sa compréhension approfondie de l'intention du client. Il donne ainsi des réponses précises et éclairées.
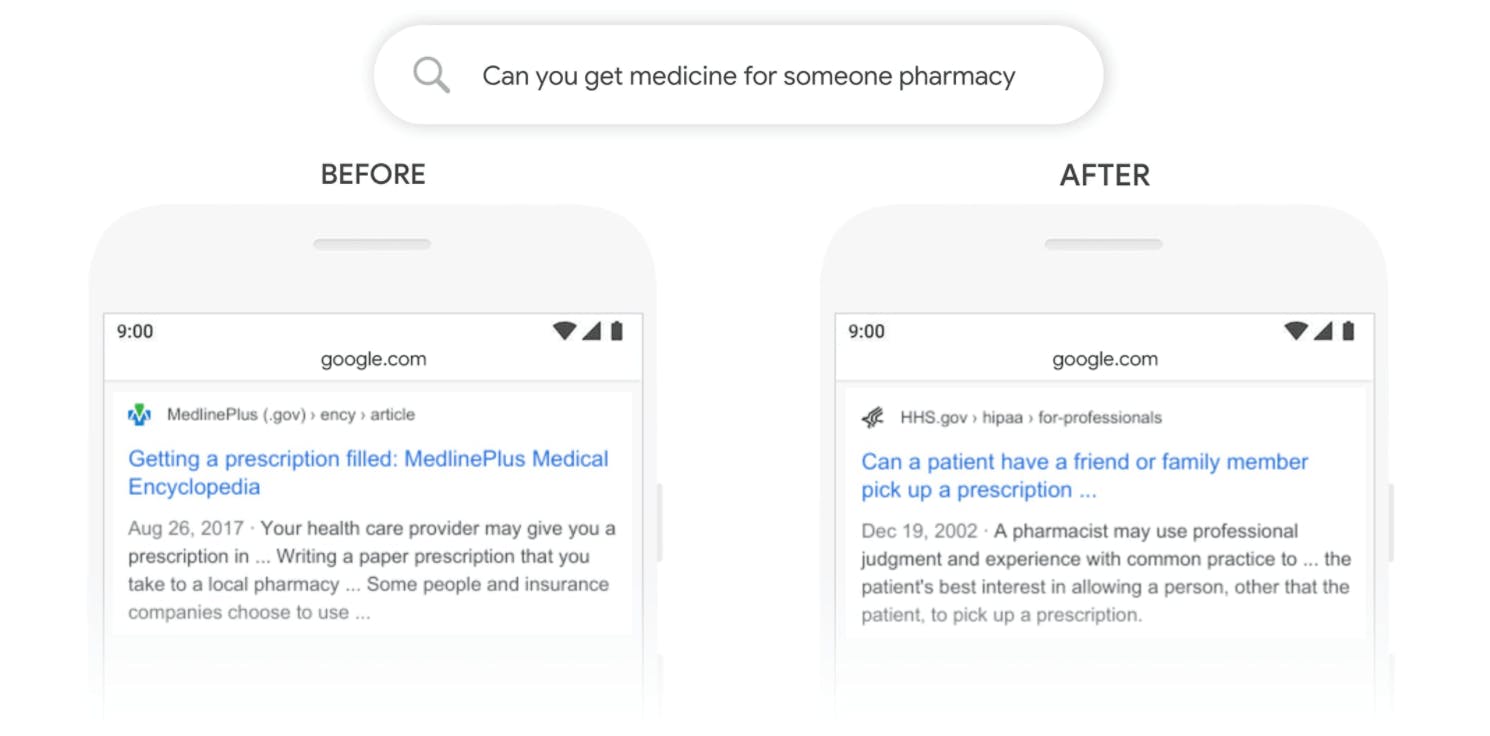
Moteurs de recherche plus intelligents
Les moteurs de recherche font partie de notre quotidien. Or, les LLM les alimentent et les rendent plus intuitifs. Ils peuvent comprendre ce que vous recherchez, même si vous ne le formulez pas parfaitement, et extraire les résultats les plus pertinents à partir de vastes bases de données. Votre expérience de recherche en ligne est ainsi optimisée.
Recommandations personnalisées
Lorsque vous effectuez des achats en ligne ou regardez des vidéos sur des plateformes de streaming, vous voyez souvent des recommandations de produits ou de contenus susceptibles de vous intéresser. Les LLM génèrent ces recommandations intelligentes. Pour ce faire, ils analysent vos habitudes de recherche pour suggérer des éléments qui correspondent à vos goûts. Vos expériences en ligne sont ainsi plus adaptées.
Génération de contenu créatif
Les LLM ne sont pas seulement des processeurs de données. Ce sont aussi des esprits créatifs. Ils disposent d'algorithmes d'apprentissage profond qui peuvent générer du contenu allant des articles de blog aux descriptions de produits, et même de la poésie. Cela permet non seulement de gagner du temps, mais aussi d'aider les entreprises à créer des contenus attrayants pour leur public.
En intégrant les LLM, les entreprises améliorent leurs interactions avec les clients, leurs fonctionnalités de recherche, leurs recommandations de produits et leur création de contenu, et transforment ainsi le paysage technologique.
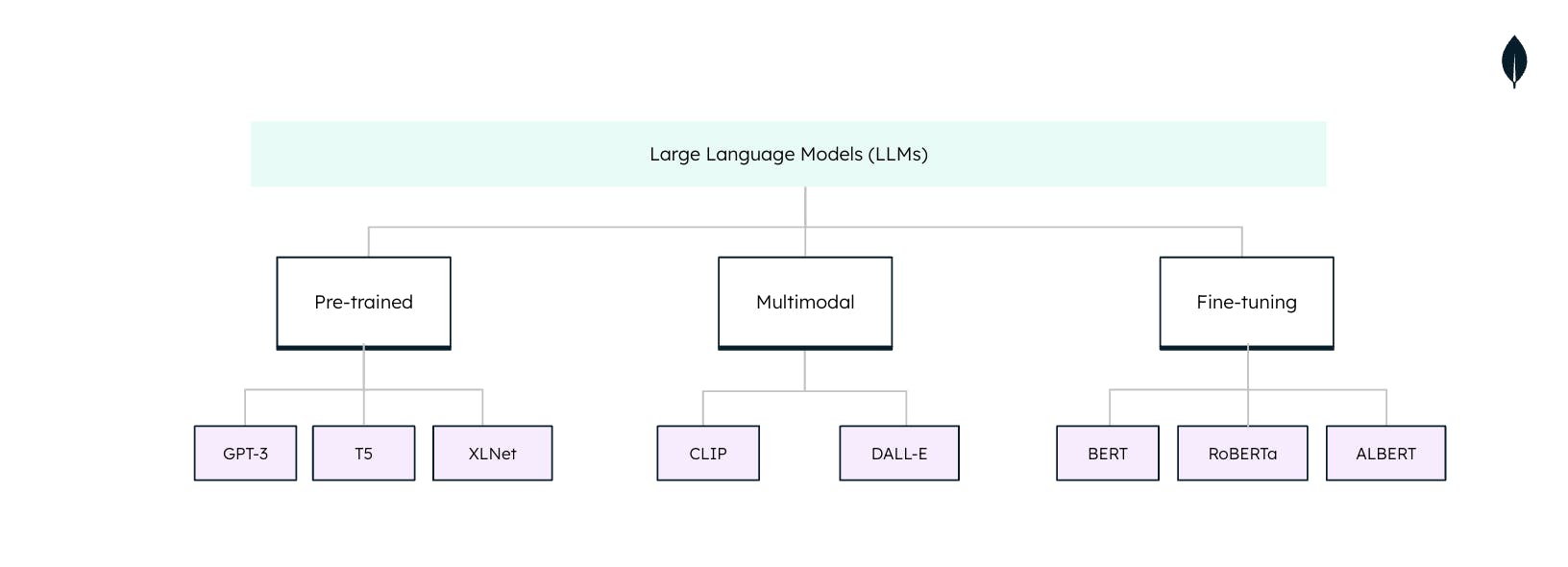
Types de grands modèles de langage
Les grands modèles de langage (LLM) ne sont pas universels lorsqu'ils sont utilisés dans des tâches de traitement du langage naturel (TAL). Chaque LLM est adapté à des tâches et des applications spécifiques. Il est essentiel de comprendre ces types pour tirer pleinement parti de leur potentiel :