Maximizing MongoDB Performance on AWS
September 16, 2016 | Updated: November 28, 2025
AWS is an incredibly popular environment for running MongoDB deployments. Today you have many choices about instance type, storage, network config, security, how you configure MongoDB processes, and more. In addition, you now have options when it comes to tooling to help you manage and operate your deployment.
In this post, we’ll take a look at several recommendations that can help you get the best performance out of AWS MongoDB installation.
Before we jump into the low-level recommendations, it’s worth pointing out that there are a few options for how you approach running your deployment on AWS:
- Rely on MongoDB as a service: MongoDB Atlas takes care of the operational heavy lifting so you can focus on building your apps. This is the easiest way to run MongoDB on AWS as many of the recommendations are “built-in”.
- Use management tools designed for MongoDB: Cloud Manager is a powerful management tool that simplifies and automates tasks like monitoring, backups, installation and upgrades, and more.
- Manage everything yourself: if you have an unusual configuration or you want to “roll your own,” there are lots of best practices for running on AWS.
No matter what way you feel is best, this post will help you understand your options and make the most of running MongoDB on AWS. We will discuss several critical factors to consider for optimal performance, including:
- Storage/Disk
- Networking
- Instance Size (Memory and CPU)
Storage
Databases require fast storage. You wouldn’t expect great performance out of Oracle, MS SQL, or MySQL on a single SATA disk. AWS provides fast storage through Elastic Block Store (EBS) or via Instance Store. EBS are persistent block level storage volumes that you associated to your EC2 instances. Instance Stores are storage volumes that directly attach to your EC2 instance hardware, and are designed for temporary storage (i.e. logs, temporary files, scratch space, etc.). EBS is the general type of storage that we recommend for EC2 for MongoDB and we’ll dive into how best to configure it.
When choosing your disks we have to ask AWS to guarantee our Input/Output Operations Per Second (IOPS) by requesting Provisioned IOPS (PIOPS). In the case of Provisioned IOPS (SSD) volumes, you can provision up to 50 IOPS per GiB. However there is a cap at 20,000 IOPS per volume. Amazon’s page on EBS volume types has more information on this subject. In addition, there are EBS-optimized instance types such as the C4, M4, and D2 instance family types. We recommend using this type of instance or enabling this feature for other recommended instance family types such as the R3 or the I2 types. EBS-optimized instances provide dedicated throughput between Amazon EC2 and Amazon EBS. This improves performance by minimizing contention from other traffic to your instances with regards to EBS I/O traffic.
We recommend dedicating 3 separate volumes for MongoDB, each with their own assigned IOPS due to the differing workload and purpose of each storage volume. Here is an example of where to begin with a baseline configuration for assigning PIOPS to each of the volumes:
- /data (1000 IOPS)
- /journal (250 IOPS)
- /log (100 IOPS)
The reason for separating your deployment storage across 3 volumes is that database journal files and log files are sequential in nature, and as such, have different access patterns compared to data files. Separating data files from journal and/or log files, particularly with a write intensive workload, will provide an increase in performance by reducing I/O contention. Depending on your workload, and if you are experiencing high I/O wait times, you may be able to benefit from separate disks for your data files, journal, and log files.
Along with IOPS, throughput is also important for storage performance, and something that AWS is fairly generous with considering it is a shared architecture with other users. As of this writing, these are the maximums for throughput according to AWS docs.
Max. Throughput/Volume is 320 MiB/s
Max. Throughput/Instance is 800 MiB/s
The EC2 instance throughput limitation of 800 MiB/s is the main bottleneck of which you need to be aware. MongoDB can provide greater throughput for your deployment by using sharding to spread the load across instances, each holding a subset of your database. For example, if you distribute your data across three shards on independent instances, then your maximum throughput across all three will be 2400MiB/s. However, there is still benefit to using multiple storage devices on a given instance, and we’ll cover that scenario in the next section on using RAID.
It is possible to use EC2’s instance store as the storage layer for your MongoDB deployment. If you do, we recommend using either an I2 (High I/O) or D2 (Dense-storage) instance type for best performance. The I2 instance type uses SSD storage for high random I/O performance, while the D2 instance type uses HDD storage with high disk throughput characteristics. The limits for instance stores are documented on this EC2 page. In order to assure best performance when using instance store, you should pre-heat this store by writing once to every drive location before production use.
RAID for performance and durability
We recommend using a redundant array of independent disks (RAID) to improve performance and durability of a MongoDB deployment. There are many levels of RAID, and each has its own advantages and disadvantages. The two key concepts underlying RAID are mirroring (RAID 1) where the same data is written to several disks and striping (RAID 0) where several disks are broken into stripes or bins with the data being copied across these. By using the proper RAID design, data durability and/or increased I/O performance is possible -- sometimes with one being sacrificed for the other. Fortunately, there is a RAID option that doesn’t sacrifice data reliability or increased I/O performance.
RAID 10 (sometime called RAID 1+0) combines the features of RAID 1 and RAID 0. RAID 1 provides data reliability by mirroring data on secondary drives, whereas RAID 0 helps to increase I/O performance by striping data across drives.
“In most cases, RAID 10 provides better throughput and latency than all other RAID levels, except RAID 0 (which wins in throughput). Thus, RAID 10 is the preferable RAID level for I/O-intensive applications such as database, email, and web servers, as well as for any other use requiring high disk performance.”
As noted earlier, you also need to ensure that your total throughput of the combined RAIDed volumes does not exceed the maximum instance throughput. If there are more PIOPS than this maximum limit provisioned for your combined volumes the additional IOPS will be wasted.
Networking
Because MongoDB can benefit from high packet-per-second performance and lower inter-instance latency networking, Amazon’s Enhanced Networking feature can provide significantly improved performance and consistency.
If your instance type supports the Enhanced Networking feature, we strongly recommend that you enable it. There are unfortunately a few caveats as Amazon EC2 provides enhanced networking capabilities via single root I/O virtualization (SR-IOV) which is only available on C3, C4, D2, I2, M4, and R3 instances and only supported when you are using Amazon VPC (Virtual Private Cloud).
**Configure Amazon VPCs for MongoDB.**Amazon Virtual Private Cloud allows you to provision a private, isolated section in AWS where you can define your own IP address, subnets, route tables, and gateways. Using VPC private subnets when deploying MongoDB servers is recommended. By using Network Address Translation (NAT), your private subnet can access the Internet, but no one on the Internet can access your MongoDB servers. AWS provides a Managed NAT (Network Address Translation) Gateway service and we recommend using this. It enables the mapping of your private IP addresses in your VPC private subnet to a public address with traffic leaving AWS, and it then maps any public IP addresses back to your VPC subnet private addresses for traffic entering AWS. It is also possible to configure a site-to-site VPN connection to access your MongoDB deployment.
With VPC, not only do you get the best networking flexibility, you also get enhanced security features like security groups and access control lists for inbound/outbound filtering. We recommend that you review these security features along with our MongoDB security checklist to ensure your deployment is secure.
Size is everything - choose the right instance type
If you have any doubt about sizing, err on the side of going larger and then scaling down as needed. Undersizing your instances when deploying MongoDB can, and likely will, create performance problems. In order to achieve the best performance, your MongoDB working set should fit in memory.
The working set is the portion of data and related indexes that your clients access most frequently. In cases where your data set is larger than memory, many random disk I/Os will happen which will affect performance as the necessary data is pulled from disk into memory. There are several factors that influence how you calculate working set size. Cloud manager is recommended as it provides the graphs necessary to perform this calculation. Likewise, as described above in Storage IOPS and throughput, under-provisioning storage IOPS will also have an affect on performance.
Based on our experience helping to implement and support MongoDB deployments on AWS, we have found that the M4, I2, and R3 Amazon ECW instance types tend to be the most successful and widely used in customer deployments.
A single mongod process per instance, please
While it is possible to run multiple MongoDB processes on a single instance, you will probably experience performance problems due to these processes competing for system resources such as CPU, RAM, and I/O.
For example, if you are using the WiredTiger storage engine and running two mongod processes on the same instance, you would need to calculate the appropriate cache size needed for each mongod process by evaluating the portion of total RAM each process should use and then split the default cache size between each. If you improperly size the WiredTiger cache and the cache does not have enough space to load additional data, pages will be evicted from the cache to free up space, resulting in unnecessary I/O and performance degradation. In this scenario, you will still only have addressed contention for the system’s RAM resources and may encounter further contention for I/O and CPU between these two mongod processes. Running a single mongod process per instance is recommended as this will eliminate the potential for another mongod process to “steal” instance resources.
Read and heed the MongoDB Production Notes
The MongoDB Production Notes (part of the excellent collection of MongoDB documentation) details system configurations that affect MongoDB. For optimal performance on AWS deployments -- particularly for production deployments -- it is especially important to follow the recommendations detailed in this documentation.
Ensure that you are deploying MongoDB on AWS to a recommended platform for production use and be sure to review and make the appropriate configuration modifications as described by the platform specific considerations section. The MongoDB on Virtual Environments section of the production notes also provides additional considerations when running MongoDB in a virtual environment like EC2. A key recommendation for virtual environments running the Linux OS is to use the noop scheduler when you have local block devices attached to virtual machine instances via the hypervisor. Using the noop scheduler allows the operating system to defer I/O scheduling to the underlying hypervisor and provides the best performance.
You may notice in the production notes that while there is a recommendation for the TCP keepalive setting of 120 seconds for Azure, there is not a recommended keepalive time specific to AWS. For AWS we recommend the same TCP keepalive setting of 120 seconds as well.
The importance of MongoDB Cloud Manager
So you’ve successfully set-up your AWS instances, installed MongoDB, and followed all of the performance recommendations and best practices mentioned in this blog post. Congratulations! Now, the next big question is: How do you plan to monitor, manage, maintain, and backup your MongoDB database? The performance of your application is clearly affected by the health of your underlying MongoDB database. Wouldn’t it be great if you had an operational tool to help you monitor, manage, and maintain your MongoDB deployment?
Fortunately, MongoDB offers an operational tool called MongoDB Cloud Manager that does just that. MongoDB Cloud Manager provides a single, unified interface that is specifically tailored to monitor and manage your MongoDB deployments. With Cloud Manager, you can:
- Monitor important stats like opcounters and connections
- Set-up and receive alerts when key metrics are out of range
- Automate backups
- Upgrade MongoDB with no downtime
- Easily create sharded clusters and replica sets
Another handy feature of MongoDB Cloud Manager is the ability to provision new AWS instances directly from the Cloud Manager interface.
With Cloud Manager Premium (available with MongoDB Professional and MongoDB Enterprise Advanced), you can also identify and address slow-running queries with the Visual Query Profiler, get automatic index suggestions, and automate index roll-out using MongoDB best practices that are built-in to the Cloud Manager product.
Some additional best practices
The following two sections deal with resilience and reducing the cost of your deployment. Strictly speaking, they aren’t going maximize your MongoDB performance on AWS, however we have found these to greatly contribute to the success of customer deployments.
Distributing your MongoDB instances for Resilience
One advantage of large public cloud providers is not just multiple data centers but often multiple data centers per geographic region. AWS provides a feature called “Availability Zones” which are distinct locations within a region, and you can spread your deployment across these to ensure high availability if a region were to go down. We recommend deploying MongoDB replica sets in AWS to achieve high availability -- with each MongoDB instance running across different Availability Zones (or even regions if desired).
Amazon EC2 is hosted in multiple locations around the world. These locations are made up of regions and Availability Zones. Each region is a separate geographic area, and each region has many segregated locations called Availability Zones. Although each Availability Zone is isolated, they are connected via low-latency links. The following diagram depicts 2 distinct regions, each with 3 Availability Zones.
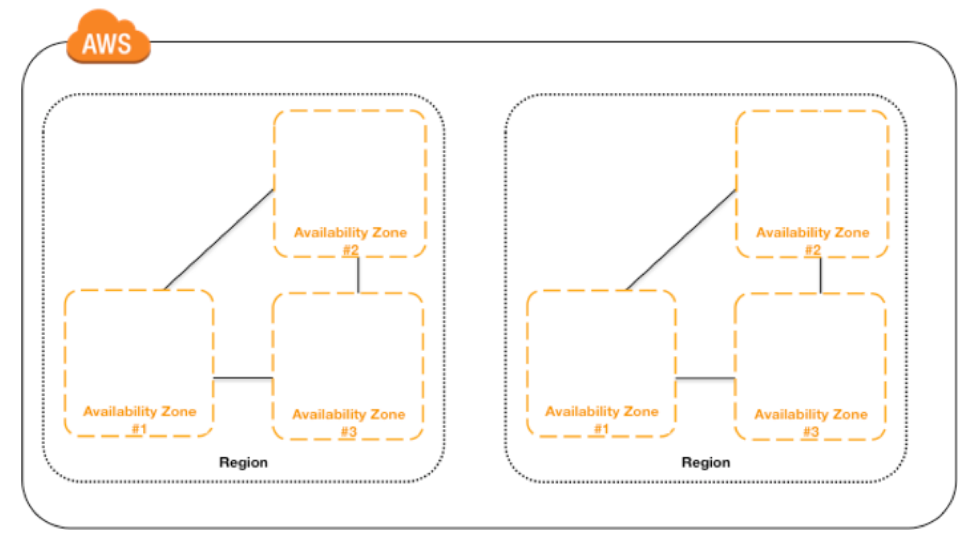
Rather than running your MongoDB instances (replica set members) in a single region and Availability Zone, distribute each MongoDB instance across regions and/or Availability Zones. Should an Availability Zone experience an outage,your MongoDB deployment can continue to process requests from your application.
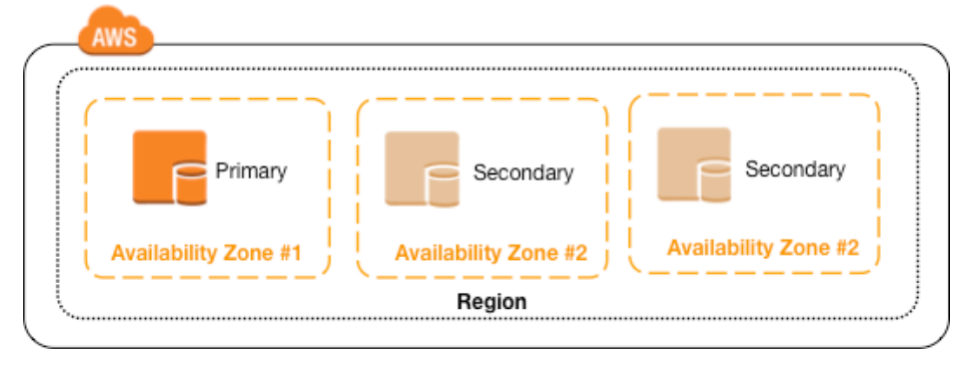
The following figure shows 3 MongoDB instances (1 primary and 2 secondaries) for high availability in a single AWS region. Additional replica set members can be added to achieve even better availability or for replicating data near users for low-latency access. You can use replica set tagging and / or sharding tags (Zones) to ensure your application targets the mongod instances geographically closest to your users to provide the low-latency.
Reducing the cost of your MongoDB deployment
Databases are typically long lived, and the assumption is that they will be “always on”. AWS provides EC2 Reserved Instances that let you reserve computing capacity for your MongoDB deployment. This particular pricing model is usually the best choice for typical database usage. Yes, there is an upfront fee associated with a reserved instance, but the per hour charge can be discounted significantly (up to 75%) when compared to on-demand pricing. Many of our customers running MongoDB on AWS find that using reserved instances is more cost-effective than using on-demand instances.
Summary
Running MongoDB on AWS offers many benefits. Deploying MongoDB on AWS is typically lower cost than traditional on-premise deployments, because you only pay for the infrastructure that is needed while avoiding the more expensive costs of hosting that infrastructure on-premises. AWS also offers great flexibility -- allowing you to scale hardware resources up or down as required. And of course, with multiple regions and availability zones, AWS offers a great level of reliability. When coupled with the high availability, scalability, and high-performance characteristics native to MongoDB, AWS and MongoDB together are a winning combination.
While deploying MongoDB on AWS is actually easy, you may not get the best performance possible without a few tweaks. As discussed in this post, you can use our database as a service, MongoDB Atlas, to make running MongoDB easy. Make sure you provision the right amount of resources in terms of instance size, IOPS, RAID configuration, and network. Adhere to the recommendations found in the MongoDB Production Notes to boost the performance of MongoDB on AWS. And lastly, if you’re not using MongoDB Atlas, use MongoDB Cloud Manager for monitoring and management of the database and follow the recommended best practices. Doing these things will not only maximize the performance of MongoDB on AWS, but also ensure that your MongoDB deployment is successful.
About the Authors - Jason Swartzbaugh and Brandon Newell
Jason Swartzbaugh has spent many years collaborating with and advising customers across multiple industries to better leverage database technologies to help solve business problems. Having worked with highly available, massively parallel relational database technologies for more than 20 years, he has performed data modeling, database administration, database performance tuning, and database operations management and support duties. Prior to MongoDB, Jason helped customers of Teradata’s Government Systems division use data warehousing technologies and analytics to improve operational efficiency and reduce cost.
A tenured subject matter expert in enterprise virtualization, Brandon Newell has expanded his portfolio into distributed enterprise computing. Working with Red Hat’s Gluster and Ceph filesystems as well as MapR’s filesystem and Hadoop platform have positioned Brandon with a prescriptive knowledge that our MongoDB customers value greatly. Brandon’s specialty topics include Microservices and Internet of Things.