Imagine you’re a data architect, a developer, or a data engineer at an insurance company. Management has asked you and your team to build a new AI claim adjustment system, a customer-facing LLM-powered chatbot, and an application to streamline the underwriting process.
However, doing so is far from straightforward due to the challenges you face on a daily basis. The bulk of your time is spent navigating your company’s outdated legacy systems, which were built in the 1970s and 1980s. Some of these legacy platforms were written in COBOL and CICS, and today very few people on your team know how to develop and maintain those technologies. Moreover, the data models you work with are another source of frustration. Every interaction with them is a reminder of the intricate structures that have evolved over time, making data manipulation and analysis a nightmare.
In sum, legacy systems are preventing your team—and your company—from innovating and keeping up with both your industry and customer demands.
Whether you’re trying to modernize your legacy systems to improve operational efficiency, boost developer productivity, or if you want to build AI-powered apps that integrate with large language models (LLMs), MongoDB has a solution for that. In this post, we’ll walk you through a journey that starts with a relational data model refactored into MongoDB collections, vectorization and querying of unstructured data and, finally, retrieval augmented generation (RAG): asking large language models (LLMs) questions about data in natural language.
Identifying, modernizing, and storing the data
Our journey starts with an assessment of the data sources we want to work with. As shown below, we can bucket the data into three different categories:
Structured legacy data: Tables of claims, coverages, billings, and more. Is your data locked in rigid relations schemas? This tutorial is a step-by-step guide on how to migrate a real-life insurance relational model with the help of MongoDB Relational Migrator, refactoring 21 tables to only five MongoDB collections.
Structured data (JSON): You might have files of policies, insurance products, or forms in JSON format. Check out our docs to learn how to insert those into a MongoDB collection.
Unstructured data (PDFs, Audios, Images, etc.): If you need to create and store a numerical representation (vector embedding) of, for instance, claim-related photos of accidents or PDFs of policy guidelines, you can have a look at this blog that will walk you through the process of generating embeddings of pictures of car crashes and persisting them alongside existing fields in a MongoDB collection.
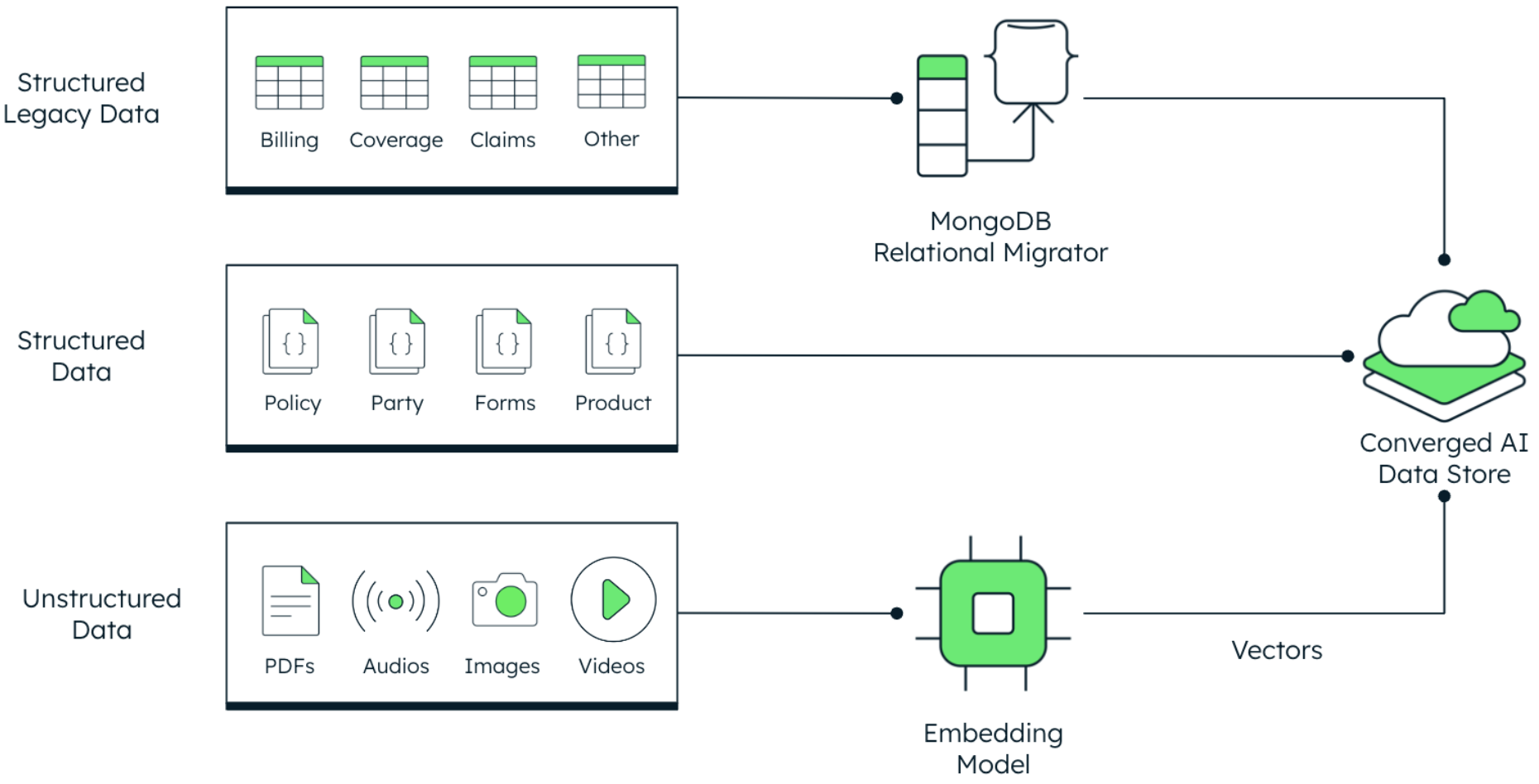
Regardless of the original format or source, our data has finally landed into MongoDB Atlas into what we call a Converged AI Data Store, which is a platform that centrally integrates and organizes enterprise data, including vectors, that enable the development of ML- and AI-powered applications.
Accessing, experimenting, and interacting with the data
It’s time to put the data to work. The Converged AI Data Store unlocks a plethora of use cases and efficiency gains, both for the business and for developers. The next step of the journey is about the different ways we can interact with our data:
Database and Full Text Search: Learn how to run database queries, start from the basics and move up to advanced features such as facets, fuzzy search, autocomplete, highlighting, and more with Atlas Search.
Vector Search: We can finally leverage unstructured data. The Image Search blog we mentioned earlier also explains how to create a Vector Search index and run vector queries against embeddings of photos.
RAG: Combining Vector Search and the power of LLMs, it is possible to interact in natural language with our data (see Figure 2 below), asking complex questions and getting detailed answers. Follow this tutorial to become a RAG expert.
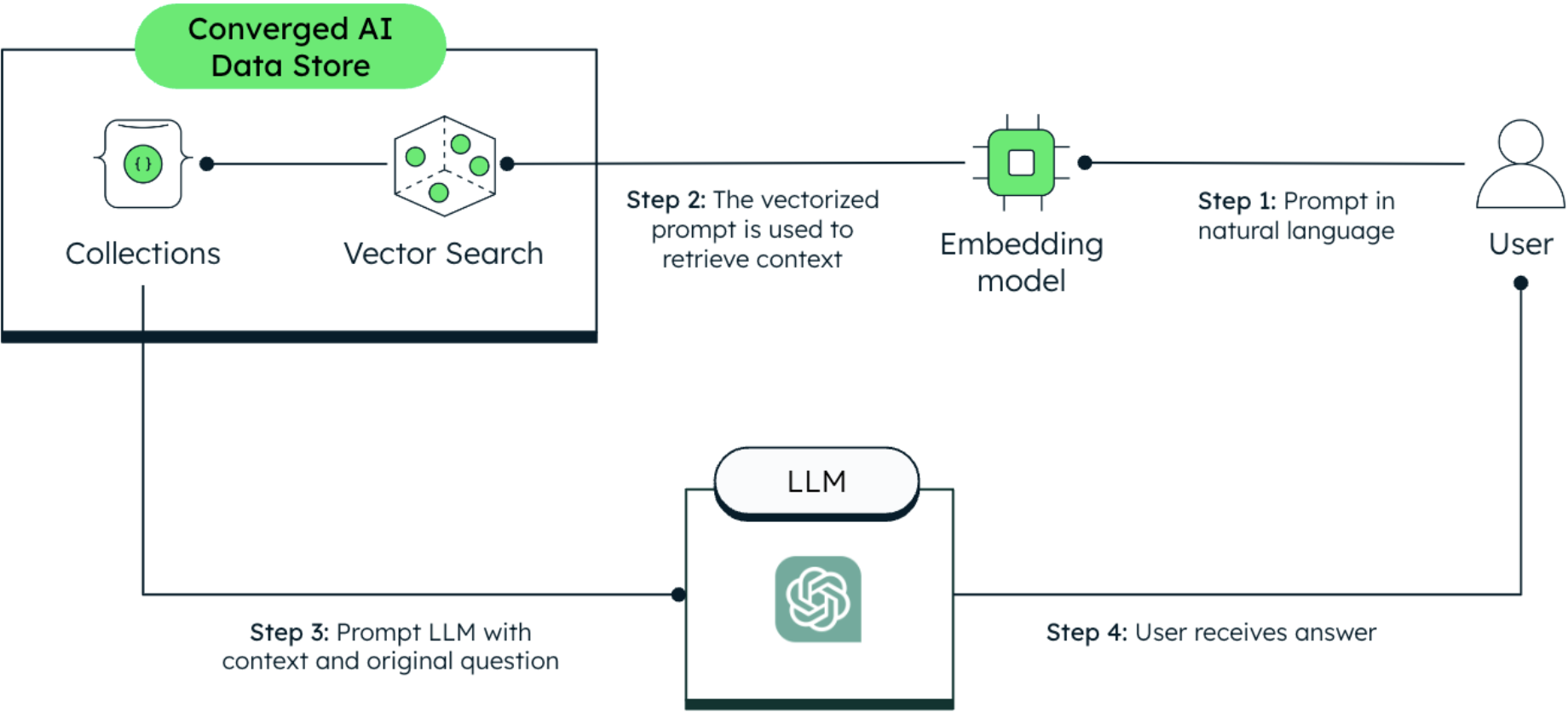
Having explored all the different ways we can ask questions of the data, we made it to the end of our journey. You are now ready to modernize your company’s systems and finally be able to keep up with the business’ demands.
What will you build next?
If you would like to discover more about Converged AI and Application Data Stores with MongoDB, take a look at the following resources: