We’re just under a year since OpenAI released ChatGPT, unleashing a wave of hype, investment, and media frenzy around the potential of generative AI to transform how we do business and interact with the world. But while the majority of the investment dollars and media attention zeroed in on the disruptive capabilities of large language models (LLMs), there’s a crucial component underpinning this breakthrough technology that hasn’t received the attention it deserves; the humble vector database.
Vector databases, a type of database that stores numeric representations (or vectors) of your data, allow advanced machine learning algorithms to make sense of unstructured data like images, sound, or unstructured text, and return relevant results.
(You can read more about vector search databases and vector search on our Developer Hub.)
For industries dealing with vast amounts of data, such as insurance, the potential impact of vector databases and vector search is immense. In this blog, we will focus on how vectors can speed up and increase the accuracy of claim adjustment.
Check out our AI Learning Hub to learn more about building AI-powered apps with MongoDB.
The claims process… vectorized!
The process of claim adjustment is time-consuming and error-prone. As one insurance client recently told us, “If an adjuster touches it, we lose money.” For each claim, adjusters need to go through past claims from the client and related guidelines, which are usually scattered across multiple systems and formats, making it difficult to find relevant information and time-consuming to produce an accurate estimate of what needs to be paid.
For this blog, let’s use the example of a car accident claim.
In our example, a car just crashed into another vehicle. The driver gets out and starts taking pictures of the damage, uploading them to their car insurance app, where an adjuster receives the photos. Typically, the adjuster would painstakingly comb through past claims and parse guidelines to work up an estimate of the damage and process the claim.
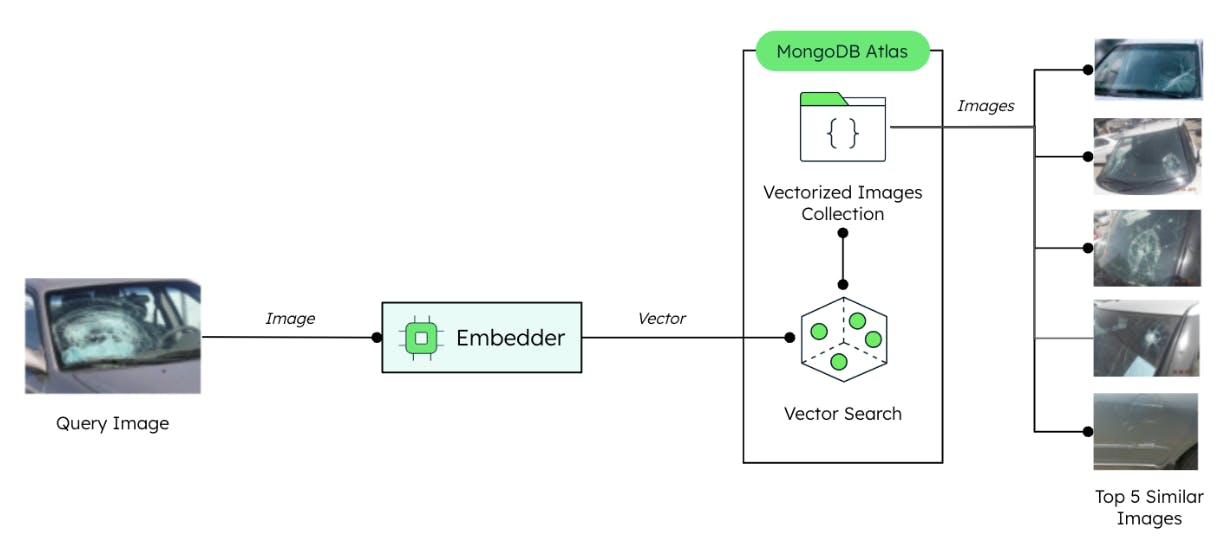
But with a vector database, the adjuster can simply ask an AI to “show me images similar to this crash,” and a Vector Search-powered system can return photos of car accidents with similar damage profiles from the claims history database. The adjuster is now able to quickly compare the car accident photos with the most relevant ones in the insurer's claim history.
What’s more, with MongoDB it is possible to store vectors as arrays alongside existing fields in a document. In our car crash scenario, this means that our fictional adjuster can not only retrieve the most similar pictures but also have access to complementary information stored in the same database: claim notes, loss amount, car model, car manufacturing year, etc. The adjuster now has a comprehensive view of past accidents and how they were handled by the insurance company, in seconds.
For this use case, we have focused on image search, but most data formats can be vectorized, including text and sound. This means that an adjuster could query using claim notes and find similar notes in the claim history or related paragraphs in the guidelines.
Vector Search is an extremely powerful tool as it unlocks access to unstructured data that was previously hard to work with such as PDFs, images, or audio files.
How does this work in practice? Let’s go through each step of the process:
- A search index is configured on an existing collection in MongoDB Atlas
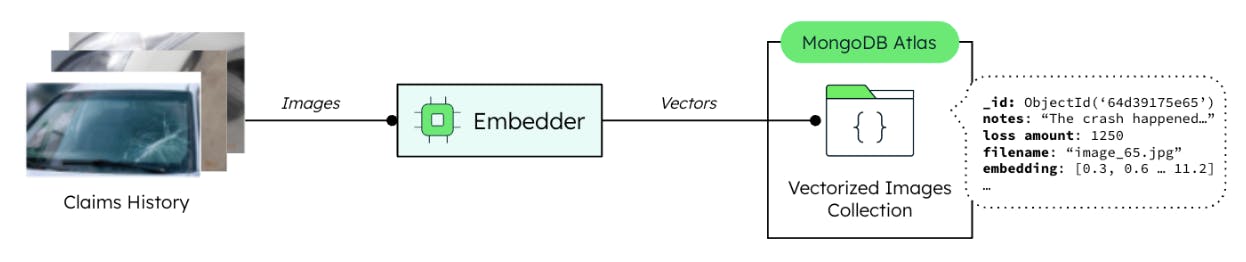
- An image set is sent to an embedding model that generates the image vectors
- The vectors are then stored in Atlas, alongside the current metadata found in the collection
- We run our query against the existing database and Vector Search returns the most similar images
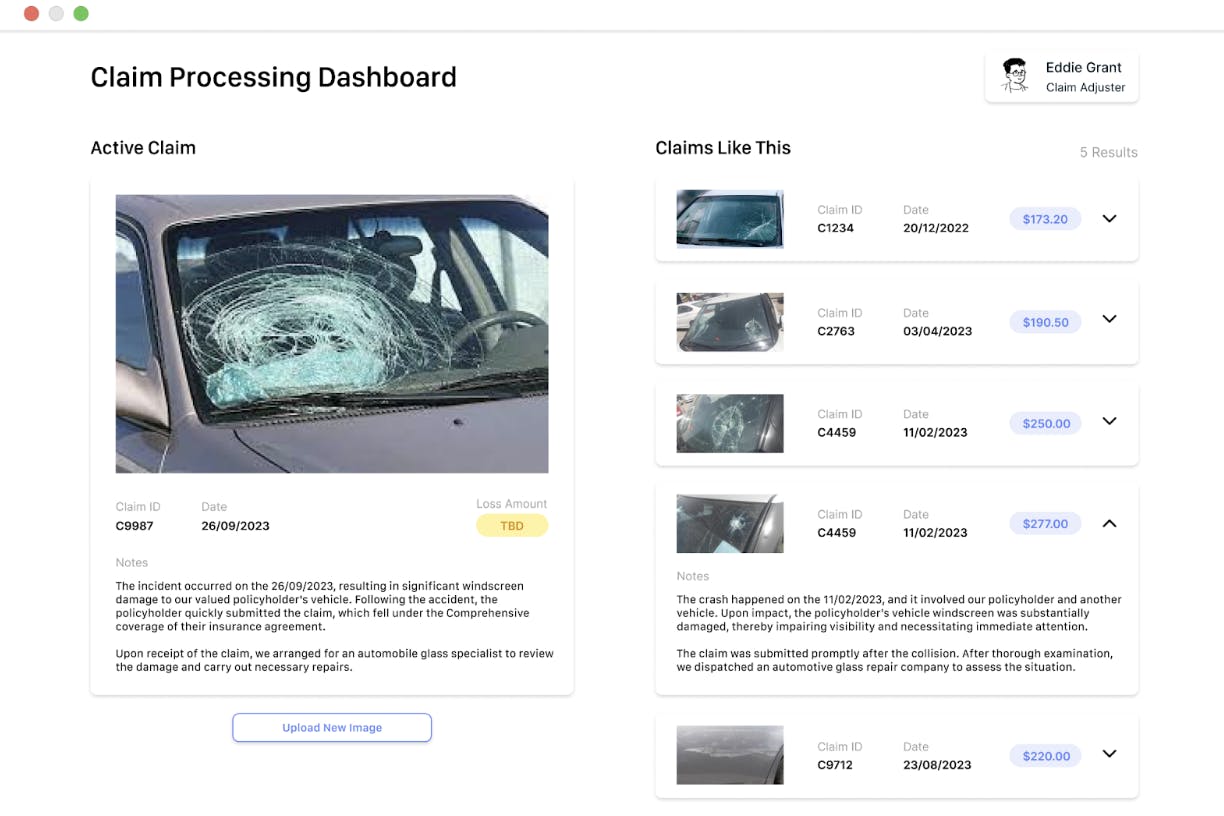
Example user interface: A claim-adjuster dashboard leveraging Vector Search
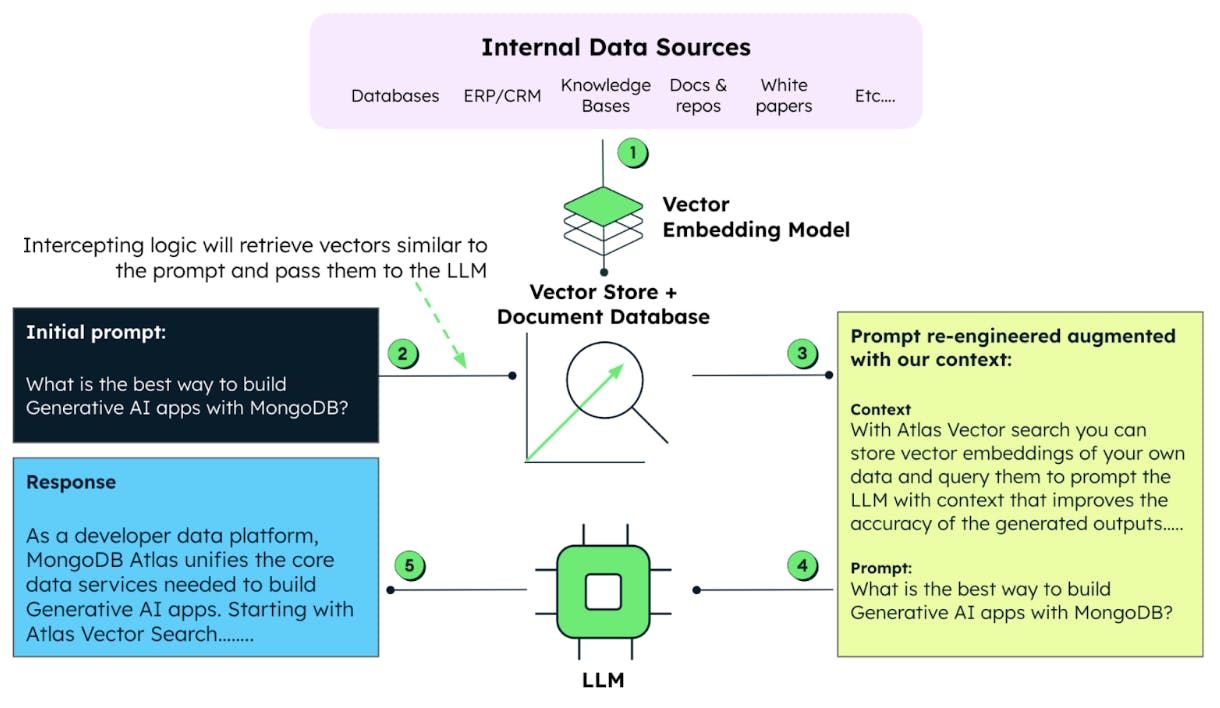
We can go a step further and use our vectors to provide an LLM with the context necessary to generate more reliable and accurate outputs, also known as Retrieval Augmented Output (RAG).
These outputs can include:
- Natural language processing for tasks such as chatbots and question-answering — think of a claim adjuster that interacts with a conversational interface and asks questions such as: “Give me the average of the loss amount for accidents related to one of the photos of claim XYZ” or “Summarize the content of the guidelines related to this accident”
- Computer vision and audio processing for image classification and object detection to speech recognition and translation
- Content generation, including creating text-based documentation, reports, and computer code, or converting text to an image or video
Figure 4 brings together the workflow enabling RAG for the LLM.
If you’re interested in seeing how to do this in practice and start prototyping, check out our GitHub repository and dive right in!
Go hands-on!
Vector databases and vector search will transform how insurers do business. In this blog we have explored how vectors can be leveraged to speed up the work of claim adjusters, which directly translates to an improved customer experience and, crucially, cost savings through faster claims processing and enhanced accuracy.
Elsewhere, vector search could be used for:
- Enhanced customer service. Imagine being able to instantly pull up comprehensive policyholder profiles, their claims history, and any related information with a simple search. Vector search makes this possible, facilitating better interactions and more informed decisions.
- Personalized Recommendations. As AI-driven personalization becomes the gold standard, vector search aids in accurately matching policyholders with tailor-made insurance products and services that meet their unique needs.
- Scaled AI Efforts. Scale AI implementations across the organization. From improving customer service chatbots to detecting fraudulent activities, vector-based models can handle tasks more efficiently than traditional methods.
Atlas Vector Search goes one step further. By unifying the operational database and vector store in a single platform, MongoDB Atlas turbocharges the process of building semantic search and AI-powered applications, empowering insurers to quickly build applications that take advantage of the value of your vast troves of data.
Find out why leading insurers trust MongoDB.
Head over to our quick-start guide to get started with Atlas Vector Search today.