Operational Management and Securing your Deployment
MongoDB Atlas radically simplifies the operation of MongoDB. As with any hosted database as a service there are still decisions you need to take to ensure the best performance and availability for your application. This blog series provides a series of recommendations that will serve as a solid foundation for getting the most out of the MongoDB Atlas service.
We’ll cover four main areas over this series of blog posts:
- In part 1, we got started by preparing for our deployment, focusing specifically on schema design and application access patterns.
- In part 2, we discussed additional considerations as you prepare for your deployment, including indexing, data migration and instance selection.
- In part 3, we provided a deep dive into how you scale your MongoDB Atlas deployment, and achieve your required availability SLAs.
- In this final instalment, we’ll wrap up with best practices for operational management and ensuring data security.
If you want to get a head start and learn about all of these topics now, just go ahead and download the MongoDB Atlas Best Practices guide.
Managing MongoDB Atlas: Provisioning, Monitoring and Disaster Recovery
Created by the engineers who develop the database, MongoDB Atlas is the simplest way to run MongoDB, making it easy to deploy, monitor, backup, and scale MongoDB.
MongoDB Atlas incorporates best practices to help keep managed databases healthy and optimized. They ensure operational continuity by converting complex manual tasks into reliable, automated procedures with the click of a button:
- Deploy. Using your choice of instance size, number of replica set members, and number of shards
- Scale. Add capacity, without taking the application offline
- Point-in-time, Scheduled Backups. Restore complete running clusters to any point in time with just a few clicks, because disasters aren't predictable
- Performance Alerts. Monitor system metrics and get custom alerts
Deployments and Upgrades
All the user needs to do in order for MongoDB Atlas to automatically deploy the cluster is to select a handful of options:
- Instance size
- Storage size (optional)
- Storage speed (optional)
- Data volume encryption (optional)
- Number of replicas in the replica set
- Number of shards (optional)
- Automated backups (optional)
The database nodes will automatically be kept up date with the latest stable MongoDB and underlying operating system software versions; rolling upgrades ensure that your applications are not impacted during upgrades.
Monitoring & Capacity Planning
System performance and capacity planning are two important topics that should be addressed as part of any MongoDB deployment. Part of your planning should involve establishing baselines on data volume, system load, performance, and system capacity utilization. These baselines should reflect the workloads you expect the system to perform in production, and they should be revisited periodically as the number of users, application features, performance SLA, or other factors change.
Featuring charts and automated alerting, MongoDB Atlas tracks key database and system health metrics including disk free space, operations counters, memory and CPU utilization, replication status, open connections, queues, and node status.
Historic performance can be reviewed in order to create operational baselines and to support capacity planning. Integration with existing monitoring tools is also straightforward via the MongoDB Atlas RESTful API, making the deep insights from MongoDB Atlas part of a consolidated view across your operations.
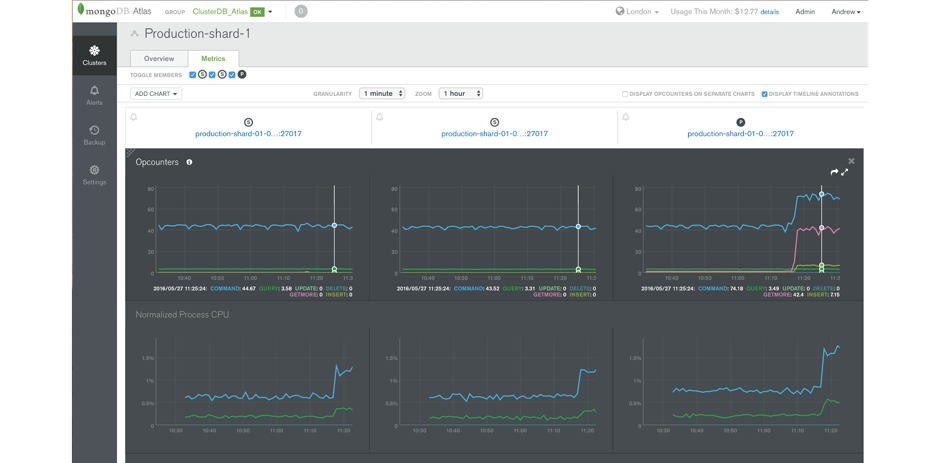
*Figure 1: Database monitoring with MongoDB Atlas GUI*
MongoDB Atlas allows administrators to set custom alerts when key metrics are out of range. Alerts can be configured for a range of parameters affecting individual hosts and replica sets. Alerts can be sent via email, webhooks, Flowdock, HipChat, and Slack or integrated into existing incident management systems such as PagerDuty.
When it's time to scale, just hit the CONFIGURATION button in the MongoDB Atlas GUI and choose the required instance size and number of shards – the automated, on-line scaling will then be performed.
Things to Monitor
MongoDB Atlas monitors database-specific metrics, including page faults, ops counters, queues, connections and replica set status. Alerts can be configured against each monitored metric to proactively warn administrators of potential issues before users experience a problem. The MongoDB Atlas team are also monitoring the underlying infrastructure, ensuring that it is always in a healthy state.
Application Logs And Database Logs
Application and database logs should be monitored for errors and other system information. It is important to correlate your application and database logs in order to determine whether activity in the application is ultimately responsible for other issues in the system. For example, a spike in user writes may increase the volume of writes to MongoDB, which in turn may overwhelm the underlying storage system. Without the correlation of application and database logs, it might take more time than necessary to establish that the application is responsible for the increase in writes rather than some process running in MongoDB.
Page Faults
When a working set ceases to fit in memory, or other operations have moved working set data out of memory, the volume of page faults may spike in your MongoDB system.
Disk
Beyond memory, disk I/O is also a key performance consideration for a MongoDB system because writes are journaled and regularly flushed to disk. Under heavy write load the underlying disk subsystem may become overwhelmed, or other processes could be contending with MongoDB, or the storage speed chosen may be inadequate for the volume of writes.
CPU
A variety of issues could trigger high CPU utilization. This may be normal under most circumstances, but if high CPU utilization is observed without other issues such as disk saturation or pagefaults, there may be an unusual issue in the system. For example, a MapReduce job with an infinite loop, or a query that sorts and filters a large number of documents from the working set without good index coverage, might cause a spike in CPU without triggering issues in the disk system or pagefaults.
Connections
MongoDB drivers implement connection pooling to facilitate efficient use of resources. Each connection consumes up to 1MB of RAM by default, so be careful to monitor the total number of connections so they do not overwhelm RAM and reduce the available memory for the working set. This typically happens when client applications do not properly close their connections, or with Java in particular, that relies on garbage collection to close the connections.
Op Counters
The utilization baselines for your application will help you determine a normal count of operations. If these counts start to substantially deviate from your baselines it may be an indicator that something has changed in the application, or that a malicious attack is underway.
Queues
If MongoDB is unable to complete all requests in a timely fashion, requests will begin to queue up. A healthy deployment will exhibit very short queues. If metrics start to deviate from baseline performance, requests from applications will start to queue. The queue is therefore a good first place to look to determine if there are issues that will affect user experience.
Shard Balancing
One of the goals of sharding is to uniformly distribute data across multiple servers. If the utilization of server resources is not approximately equal across servers there may be an underlying issue that is problematic for the deployment. For example, a poorly selected shard key can result in uneven data distribution. In this case, most if not all of the queries will be directed to the single mongod that is managing the data. Furthermore, MongoDB may be attempting to redistribute the documents to achieve a more ideal balance across the servers. While redistribution will eventually result in a more desirable distribution of documents, there is substantial work associated with rebalancing the data and this activity itself may interfere with achieving the desired performance SLA.
If in the course of a deployment it is determined that a new shard key should be used, it will be necessary to reload the data with a new shard key because designation and values of the shard keys are immutable. To support the use of a new shard key, it is possible to write a script that reads each document, updates the shard key, and writes it back to the database.
Replication Lag
Replication lag is the amount of time it takes a write operation on the primary replica set member to replicate to a secondary member. A small amount of delay is normal, but as replication lag grows, significant issues may arise.
If this is observed then replication throughput can be increased by moving to larger MongoDB Atlas instances or adding shards.
Disaster Recovery: Backup & Restore
A backup and recovery strategy is necessary to protect your mission-critical data against catastrophic failure, such as a software bug or a user accidentally dropping collections. With a backup and recovery strategy in place, administrators can restore business operations without data loss, and the organization can meet regulatory and compliance requirements. Taking regular backups offers other advantages, as well. The backups can be used to seed new environments for development, staging, or QA without impacting production systems.
MongoDB Atlas backups are maintained continuously, just a few seconds behind the operational system. If the MongoDB cluster experiences a failure, the most recent backup is only moments behind, minimizing exposure to data loss.
mongodump
In the vast majority of cases, MongoDB Atlas backups deliver the simplest, safest, and most efficient backup solution. mongodump is useful when data needs to be exported to another system, when a local backup is needed, or when just a subset of the data needs to be backed up.
mongodump is a tool bundled with MongoDB that performs a live backup of the data in MongoDB. mongodump may be used to dump an entire database, collection, or result of a query. mongodump can produce a dump of the data that reflects a single moment in time by dumping the oplog entries created during the dump and then replaying it during mongorestore, a tool that imports content from BSON database dumps produced by mongodump.
Integrating MongoDB with External Monitoring Solutions
The MongoDB Atlas API provides integration with external management frameworks through programmatic access to automation features and monitoring data. APM Integration Many operations teams use Application Performance Monitoring (APM) platforms to gain global oversight of their complete IT infrastructure from a single management UI. Issues that risk affecting customer experience can be quickly identified and isolated to specific components – whether attributable to devices, hardware infrastructure, networks, APIs, application code, databases and, more.
The MongoDB drivers include an API that exposes query performance metrics to APM tools. Administrators can monitor time spent on each operation, and identify slow running queries that require further analysis and optimization.
In addition, MongoDB Atlas provides packaged integration with the New Relic platform. Key metrics from MongoDB Atlas are accessible to the APM for visualization, enabling MongoDB health to be monitored and correlated with the rest of the application estate.
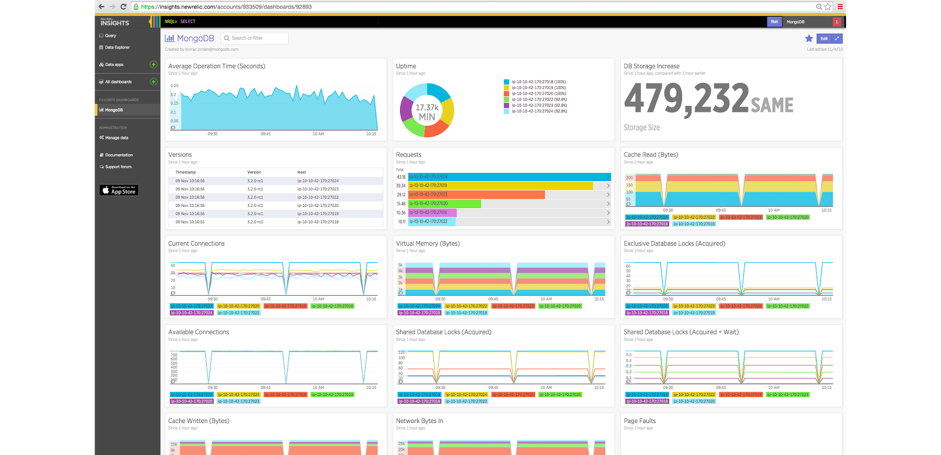
*Figure 2: MongoDB integrated into a single view of application performance*
As shown in Figure 1, summary metrics are presented within the APM’s UI. Administrators can also run New Relic Insights for analytics against monitoring data to generate dashboards that provide real-time tracking of Key Performance Indicators (KPIs).
Security
As with all software, MongoDB administrators must consider security and risk exposure for a MongoDB deployment. There are no magic solutions for risk mitigation, and maintaining a secure MongoDB deployment is an ongoing process.
Defense in Depth
A Defense in Depth approach is recommended for securing MongoDB deployments, and it addresses a number of different methods for managing risk and reducing risk exposure.
MongoDB Atlas features extensive capabilities to defend, detect, and control access to MongoDB, offering among the most complete security controls of any modern database:
- User Rights Management. Control access to sensitive data using industry standard mechanisms for authentication and authorization at the database level
- Encryption. Protect data in motion over the network and at rest in persistent storage
To ensure a secure system right out of the box, authentication and IP Address whitelisting are automatically enabled.
Review the security section of the MongoDB Atlas documentation to learn more about each of the security features discussed below.
IP Whitelisting
Clients are prevented from accessing the database unless their IP address (or a CIDR covering their IP address) has been added to the IP whitelist for your MongoDB Atlas group.
Authorization
MongoDB Atlas allows administrators to define permissions for a user or application, and what data it can access when querying MongoDB. MongoDB Atlas provides the ability to provision users with roles specific to a database, making it possible to realize a separation of duties between different entities accessing and managing the data.
Additionally, MongoDB's Aggregation Framework Pipeline includes a stage to implement Field-Level Redaction, providing a method to restrict the content of a returned document on a per-field level, based on user permissions. The application must pass the redaction logic to the database on each request. It therefore relies on trusted middleware running in the application to ensure the redaction pipeline stage is appended to any query that requires the redaction logic.
Encryption
MongoDB Atlas provides encryption of data in flight over the network and at rest on disk.
Support for SSL/TLS allows clients to connect to MongoDB over an encrypted channel. Clients are defined as any entity capable of connecting to MongoDB Atlas, including:
- Users and administrators
- Applications
- MongoDB tools (e.g., mongodump, mongorestore)
- Nodes that make up a MongoDB Atlas cluster, such as replica set members and query routers.
Data at rest can optionally be protected using encrypted data volumes.
Wrapping Up
This brings us to the end of our 4-part blog series. As you’ve seen, MongoDB Atlas automates the operational tasks that usually burdens the user, freeing you up to focus on what you do best – delivering great applications. There remain some tasks that will keep your application running smoothly and quickly; this blog series has described those best practices. Collectively, they will help you get the most out of the database service.
Remember, if you want to get a head start and learn about all of our recommendations now, just go ahead and download: